













PapersWithCode發布代碼完整性自查清單:想獲得更多星,你需要注意這五項
如何恰當地提交代碼,才能既保證研究的可復現性,又能擴大傳播?近日,PapersWithCode 發布了機器學習代碼完整性自查清單。目前,該清單已成為 NeurIPS 2020 代碼提交流程的一部分。
可復現性是科學領域長期關注的話題,近期人工智能和機器學習社區也對此投入了更多關注。例如 ICML、ICLR 和 NeurIPS 這些頂級學術會議都在努力推進將實驗代碼和數據作為評審材料的一部分提交,并鼓勵作者在評審或出版過程中提交代碼以幫助結果可復現。
加拿大麥吉爾大學副教授、Facebook 蒙特利爾 FAIR 實驗室負責人 Joelle Pineau 多次探討該領域的可復現問題,并在去年底發布了可復現性檢查清單。但是這份清單中的大部分內容與論文本身的構成有關,對于代碼開源提供的指導較少。
最近,Papers with Code 聯合創始人 Robert Stojnic 發布了一份機器學習代碼完整性自查清單,或許可以幫助社區部分地解決這一難題。
Papers with Code 網站收集了大量論文實現集合和最佳實踐。該團隊對這些最佳實踐進行了總結,得出一份機器學習代碼完整性自查清單。目前該清單已成為 NeurIPS 2020 代碼提交流程的一部分,并且將會提供給評審人員使用。
清單項目地址:https://github.com/paperswithcode/releasing-research-code
機器學習代碼完整性自查清單
為鼓勵復現性,幫助社區成員基于已發表工作更輕松地構建新的項目,Papers with Code 團隊發布了機器學習完整性自查清單。
該清單基于腳本等評估代碼庫的完整性,共包含五大項:
- 依賴項
- 訓練腳本
- 評估腳本
- 預訓練模型
- 結果
該團隊對 NeurIPS 2019 論文的官方 repo 進行分析后發現,代碼完整性越高,項目的 GitHub 星數越多。
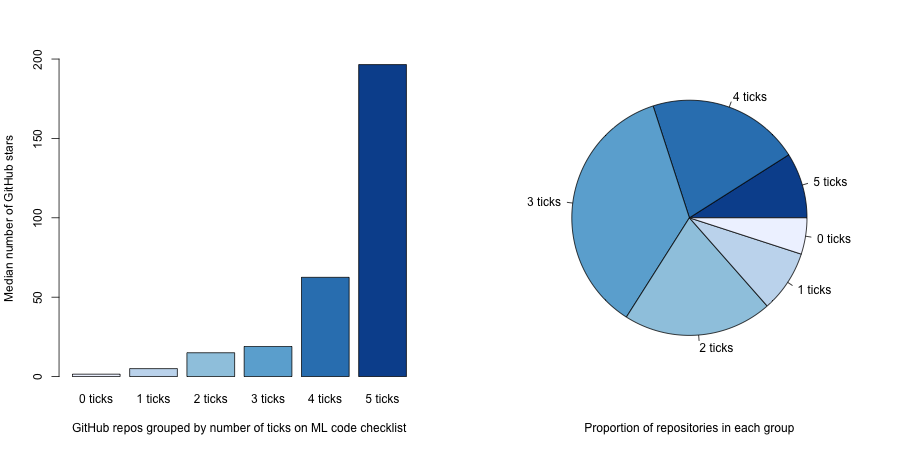
既然如此,我們趕快來看這五項的具體內容,并實施起來吧。
1. 依賴項
如果你用的語言是 Python,那么當使用 pip 和 virtualenv 時,你需要提供 requirements.txt 文件;當使用 anaconda 時,你需要提供 environment.yml 文件;當使用的是代碼庫時,你需要提供 setup.py。
在 README.md 中解釋如何安裝依賴項是一種很好的做法。假設用戶具備極少的背景知識,編寫 README 文件時盡量給出清晰完整的說明。因為如果用戶無法設置好依賴項,那么他們大概率不會繼續看你的代碼。
如果想提供整體可復現的環境,你可以考慮使用 Docker,把環境的 Docker 鏡像上傳到 Dockerhub。
2. 訓練腳本
代碼應包含用來實現論文結果的訓練腳本,也就是說你應該展示獲得結果的過程中所使用的超參數和 trick。為了將效用最大化,理想情況下寫代碼時你的腦海中應當有一些擴展場景:如果用戶也想在他們自己的數據集上使用相同的訓練腳本呢?
你可以提供一個完備的命令行包裝器(如 train.py)作為用戶的切入點。
3. 評估腳本
模型評估和實驗通常細節較多,在論文中常常無法得到詳細地解釋。這就是提交評估模型或運行實驗的確切代碼有助于完整描述流程的原因所在。而且,這也能幫助用戶信任和理解你的研究。
你可以提供一個完備的命令行包裝器(如 eval.py)作為用戶的切入點。
4. 預訓練模型
從頭訓練模型需要大量時間和成本。增加結果可信度的一種有效方法是提供預訓練模型,使社區可以評估并獲得最終結果。這意味著用戶不用重新訓練就能看到結果是可信的。
它還有一個用處,即有助于針對下游任務進行微調。發布預訓練模型后,其他人能夠將其應用于自己的數據集。
最后,有些用戶可能想試驗你的模型在某些樣本數據上是否有效。提供預訓練模型能夠讓用戶了解你的研究并進行試驗,從而理解論文的成果。
5. 結果
README 文件內應包括結果和能夠復現這些結果的腳本。結果表格能讓用戶快速了解從這個 repo 中能夠期待什么結果。
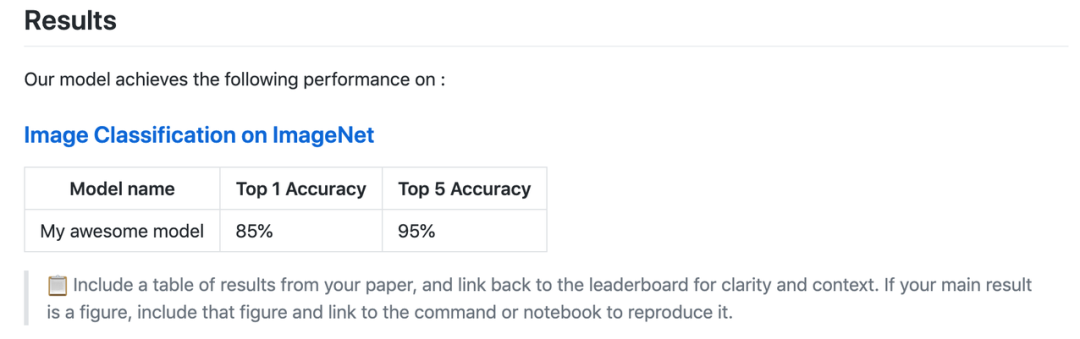
README.md 模板中的示例(模板地址:https://github.com/paperswithcode/releasing-research-code/blob/master/templates/README.md)
能夠復現結果的指令給用戶提供了另外一個切入點,能夠直接促進可復現性。在一些情況下,論文的主要結果只有一張圖,對于沒有讀過論文的用戶,理解起來會很困難。
你還可以放置包含其他論文最新結果的完整排行榜鏈接,這有助于用戶進一步理解你的研究結果。
具備代碼完整性的項目示例
此外,該團隊還提供了多個具備代碼完整性的項目,以及有助于代碼提交的額外資源。
NeurIPS 2019 項目示例
- https://github.com/kakaobrain/fast-autoaugment
- https://github.com/bknyaz/graph_attention_pool
- https://github.com/eth-sri/eran
- https://github.com/NVlabs/selfsupervised-denoising
- https://github.com/facebookresearch/FixRes
額外資源
預訓練模型文件托管平臺:
- Zenodo
- GitHub Releases
- Google Drive
- Dropbox
- AWS S3
模型文件管理工具:
- RClone
標準化模型界面:
- PyTorch Hub
- Tensorflow Hub
- Hugging Face NLP models
結果排行榜:
- Papers with Code leaderboards
- CodaLab
- NLP Progress
- EvalAI
- Weights & Biases - Benchmarks
制作項目頁面工具:
- GitHub pages
- Fastpages
制作 demo 和教程工具:
- Google Colab
- Binder
- Streamlit

















