













如何評測語音技能的智能程度之一意圖理解
從事AI-NLP領域已經一年半了,一直潛心學習。
平日里研究各種各樣的語音助手,輸出各種類型的調研分析報告,以培養自己的業務敏銳度,同時也研究各種框架型知識以豐富自己的知識庫。
在仔細、反復研讀完了
- 《Google對話式交互規范指南》
- 《阿里語音交互設計指南》
- 《亞馬遜語音交互設計規范》
- 《DuerOS技能交互設計規范》
幾大交互規范后,累積過往的工作過程中所遇見的問題,自己努力嘗試著提煉出一個知識框架,并期望把這些規范類的東西,內化成為自己的被動技能,繼而為自己以后做出更好用的產品做出積累。
Part 1 我心中的超級人工智能
私以為,最理想的人工智能,就像
《Her》里面的薩曼莎;《鋼鐵俠》里面的賈維斯;《超能陸戰隊》里面的大白;《多啦A夢》里面的機器貓;
這些超級英雄總能解決我們生活中的各種各樣的問題。
雖然我們的世界距離這種超級人工智能還非常遙遠,也許永遠達不到,但是不妨以一種非常高的標準對AI去做出苛求,繼而去倒逼自己做出更好的產品。
文章開始前,請先短暫忘記自己是AI從業者這個身份,讓我們變成一個小白用戶,盡管提要求吧。
簡單而言就是一句話。
“我就想要一個聰明且好用的智能助理,能夠滿足我生活中的各種需求。”
“好用”如何定義?“各種需求”如何滿足?難就難在沒有邊界。
真正意義能符合上面要求的是,可以無限許愿的神燈。
所以我們干脆模塊化一些,筆者就智能語音助理這一產品有如下四個大的評判維度。
它們依次是【意圖理解】、【服務提供】、【交互流暢】、【人格特質】。

亦或者是說,這些指標如果能夠得到全部滿足,距離我們想要的超級人工智能也就不遠了。誰能夠提供,誰就可以獲得用戶的青睞。
每個評判維度還有對應的細分指標,讓我們一步步拆解。
Part 2 【意圖理解】維度的5個指標
本文重點定義和討論第一大模塊【意圖理解】,即。是否能夠理解/識別用戶表述的意圖。
私以為,這個模塊是衡量AI智能與否的核心維度。
【意圖理解】(1)中控分配意圖能力
當前市面上的AI智能助手,往往包含著各種各樣的能力。
從業者角度而言,本質是各個技能的集合,而每一項能力都是服務和滿足特定領域類的需求,比如聽音樂,導航,事項提醒,電影票,機票,火車票什么的。
很多的技能在固定域里面能夠表現得非常好,但是集中到一起,表現就未必好了。
核心考量點:準確識別用戶需求,并分配到指定技能服務的能力。
用戶提出的每個需求,計算機都會做出反饋(文本、語音、圖片、功能卡片、多媒體事件等等)。
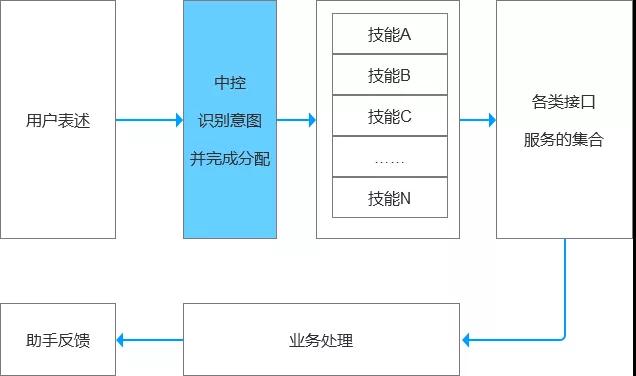
在反饋之前,是先要做到識別并理解,然后成功分配到指定的技能上,最后由指定的技能完成反饋,即服務行為。
而人類的語言表達千奇百怪,我們期望計算機自然能夠通過人的自然表達,成功理解人類的意圖,并使用對應的回復銜接業務。
例子:我想聽我想去拉薩>>>意圖應該分配給音樂,然后由【音樂】完成反饋。我想去拉薩>>>意圖分配導航,然后由【導航】完成反饋。
例子:提醒我一下我明天幫女朋友買一束花花>>>意圖可以分配給【事項提醒】技能 我想明天幫女朋友訂一張到上海的火車票,你早上8點半提醒我下搶票>>>意圖如果分配給【訂火車票】技能就錯了
這個就是中控分配意圖的能力。也是所有AI智能助手,集合各項能力的一個核心能力。做不好中控的意圖識別,智能化無從談起。
市面上,例如騰訊叮當、小愛同學,小度助手這類大生態的集合的處理方案,屬于最大的開放域,相當多的技能只能是采用命令詞跳轉的方式啟動,這種對話行動無疑是要等待,而且對話流程冗長,面對著輸入的不確定性,所以用戶為什么不用GUI(圖形交互界面)去完成目標呢。
而一些細分領域的,比如說出行、餐飲、客服、游戲領域的智能助手,這些相對的封閉固定的領域,還用關鍵詞的方式進入指定技能再尋求服務,就顯得非常笨了。
如果做不到全開放域的中控,至少也得在固定域里面做好意圖需求識別以及分配的能力,這樣方便發揮語音輸出便捷直達目標的能力,才不至于像個玩具。
【意圖理解】(2)句式/話術/詞槽泛化度
用大白話來講:同一個意思,當用戶采用不同的表達的時候,AI是否能夠正確理解。
業內的專業說法是“可識別話術/詞槽的泛化程度”。解決方案是“增加更多的語義覆蓋”。
泛化有兩種,一種是句式,另一種是槽位。
先說句式的例子:
筆者經常觀察用戶的對話日志后臺,發現用戶在播放音樂的時候,表述各種各樣。
我想聽音樂>>>隨便放首歌>>>音樂響起來>>>music走起>>>
有些能夠能理解,【音樂】正確回復隨機歌單,有些話術的表述無法理解則被【兜底】給接走了,這種反饋就是助手的失誤了。
列舉詞槽例子:我想吃711/想吃七十一/想吃seven eleven/想吃關東煮/想吃好燉>>> 我想吃肯德基/想吃KFC/想吃開封菜>>>
筆者的所開發的智能助手有一個【電影票】技能,觀察用戶對話日志時的一些發現。
《速度與激情8》剛剛上映,用戶會表述是我想看速度與激情、速激、速8等等;《魔童哪咤》上映的時候,用戶的表述是,我想看哪咤的電影;《葉問3》上映的時候,用戶的表述會是,葉問。甚至是甄子丹的那個電影;
而AI先提取對應的影片名,然后交給接口方去完成查詢行為,只有正確填充“指定電影的全稱”才能夠可查詢成功,所以此處就需要做映射關系的特殊處理。
在定電影票例子中,是十分考慮場景和時效性,也就是說,用戶在不同的時間點,說我要看《某》系列電影的時候,口語上大概率是絕對不會帶上第幾部的。
這些要求其實都是生活中的一些例子,既然人類可以做到理解,自然AI也理所應當做得更好。
作為從業者,一定要多看自己的公司業務的對話日志后臺,觀察用戶在對話過程中,究竟是如何去使用我們的產品,這個是我們的迭代產品的重要依據,隨時根據用戶實際使用情況,做出完善。
就過往的泛化經驗而言,結構性的句子變化相對較小,而詞語的變化就很多,像分析數據一樣經常看用戶的對話日志,會有很多的積累。
比如阿里巴巴的天貓精靈是具備線上語音購物的能力的,那么眼下的2020春節,相當多的用戶會在我想買口罩這種話術之外,直接表述,我想買3M的口罩甚至會直接問有沒有N95賣,畢竟在眼下的這個語境,N95幾乎就是口罩的代名詞了。
如果這類沒有覆蓋,那你也只能通過版本迭代去訓練,各位AI從業者基于自家產品的版本迭代效率,思考一下差距。
所以“一開始就做好”相比“通過各種渠道反饋發現不好,然后通過迭代去做好”,從產品設計基本功上來看,根本是兩種境界。
所以解決方案是,此處應該是有一個動態熱詞的詞庫,產品設計和運營方式不展開,不在本篇討論范圍內。
在實際的業務中,很多詞匯和句式會被不斷地造出來,至于優先級如何選擇,如何泛化覆蓋詞槽和句式,鑒于文章定位,此處不適合展開。
【意圖理解】(3)反饋準確度/容錯率
考量AI的反饋給用戶的內容是否能夠準確匹配需求,是否具備顯性確認以提升容錯性。各個語音交互設計規范都提及了這一點。
例子:我想聽林志炫的《煙花易冷》>>>如果AI推送的是周杰倫的就不對。
如果沒有資源,也應該處理成,未找到XXX,讓我們來聽YYY方為合理。
而當接口仿真(因為版權)沒有資源時,明確沒有,是一種我聽懂了,但是實在沒有,給你提供替代方案的處理,而如果你不明示沒有,我可能會再追問一句,然后你還是不明示,到底是我沒說明白,還是你沒聽懂呢?
例子:假設現在是1月1日的晚上23點鐘,用戶說“幫我訂一個明天早上7點的鬧鐘” 假設現在是1月2日的凌晨1點鐘,用戶說“幫我訂一個明天早上7點的鬧鐘”
第二種情況,如果按照計算機的邏輯去理解,那1月2日的明天早上則是1月3日的早上了,這種定鬧鐘的方式意味著悲劇。
而基于日常邏輯,兩種情況,都應該提供1月2日,早上7點鐘的鬧鐘方為合理。
邏輯處理完畢后,然后就是話術的處理,回復方式有幾種選擇:
回復1:已經為您設置鬧鐘。回復2:已為您設置明天早上7點鐘的鬧鐘。回復3:已經為您設置明天早上7點的鬧鐘,我將會在6個小時后叫醒你。
如果沒有顯性確認,就沒有容錯性,用戶就會心中不安,一旦被【鬧鐘】服務坑過用戶一回,那么就會惡評如潮。本來用戶就用的低頻,一旦不信任,被打入冷宮再也沒什么機會了。
只要你仔細體驗觀察,相當多的AI語音助手在給予反饋的時候,此類細節處理得不好,容錯率實在是太低了。好的容錯性設計,其實應該是每個AI從業者體內的基因,成為被動技能,天賦一樣的能力。
【意圖理解】(4)模糊/歧義表述處理
GUI的交互意味著輸入可控,CUI/VUI的交互意味著輸入不可控。
這中間相當一部分是人類的表達問題,但是一旦造成的回復不滿意,意味著用戶將花費巨大的成本去再來一次。最后被用戶批評或者被定性為“人工智障”、“就是個能對話的玩具”往往很讓人沮喪。
核心考量點:當用戶使用模糊歧義表述的時候,AI的處理方式。
例子:我明天下午4點要去上海出差。
注意此時至少存在兩處模糊歧義表述, 一是用戶并沒有指定交通工具。二是明天下午4點,指的是4點出發,還是4點到那里。
例子:(假設現在是周一)幫我定下周三去上海的機票。
注意:ASR的轉化是無法翻譯停頓的,到底是幫我訂,下周三的,還是,幫我定下,周三的呢?
在真實的對話中,人們是能夠根據停頓節奏,以及具體的場景猜測到底是如何斷句的。
以上兩個例子是我們業務中反饋的真實案例。
說說我自己處理這類問題的思路,即提前交付結果,等待用戶反饋。
第一個例子,根據用戶的GPS坐標出行便捷程度以及商業訴求進行推薦。火車,飛機,或者是打車均是正確的選擇。
例如可以做出如下回復,“基于天氣情況,建議火車出行,為你找到從XX到上海的火車票,1月3日出發,高鐵二等座,價格……”
第二個例子,根據用戶提出需求的時間,就近選擇結果反饋,并給予顯性確認。
當面對模糊/歧義意圖的時候,一定要有一個處理邏輯,去管理用戶的期望值和服務。
面對模糊/歧義表述的處理方式在行業內通通都是大難題。好的處理方案,能夠判斷用戶的歧義表述,并引導糾錯。
至于處理邏輯是直接給于結果,還是通過追問的形式二次判斷,就是具體業務具體場景的選擇了。
不過多舉例,但是有無處理方案,應該納入進評測點。
【意圖理解】(5)目標達成表現
核心考量點:幫助用戶達成目標中間所花費的成本。
當前市面上幾乎所有的服務類技能,都是AI通過提取用戶表述中的具體信息,填充到指定槽位完成服務的推薦,而當用戶沒有給予主要槽位的時候,是需要引導用戶完成的。
市面上有兩種做法,一種是固定路徑,不可改變的填槽。
比如說【火車票】技能,正常的對話是這樣的。
先問出發地和目的地,然后問出發日期,然后確定車次,中間不能改不能亂,然后方可完成查詢行為。
用戶第一句話:我想買火車票?AI回復,好的,你想從哪里到哪里?用戶第二句話:從北京到上海。AI回復,您想什么時候出發?用戶第三句話:明天下午出發。AI回復,為你找到如下車次,請問你想要第幾個。用戶第四句話:那就第一個吧。AI回復,好的,正在為你下單。
這種我稱之為,固定序不可逆填槽,簡直笨到了極致。
如果你顛倒順序填充槽位,AI很可能就智障掉了。
生活中,我們這邊一個70歲以上的老人,可以在窗口完成火車票購買,(拋開口音的問題)但是無法通過AI助手完成火車票的購買。
為什么呢?很多比較笨的AI,跟圖形界面一樣,要求用戶適應它的邏輯去完成填充。
這種處理方案,簡直違背自然語言處理的這一初衷。
而好的智能助手是可以做到亂序填槽,并且隨意改槽位條件的。
例子:用戶第一句話:我想買一張明天從北京到上海的火車票,我要下午四點出發的,我想要一等座。我們可以根據結果,著AI提取槽位,以及反饋的能力。
用戶第二句話:再幫我看看,后天上午十點出發的,二等座也行。如果AI能夠搞定,那證明可以達到一定的智能化程度了。
以上是應對用戶的表述,而在對話服務過程中,還有一個反向管理,完善槽位的引導。
我們可以做一個簡單的練習,例如在買電影票的場景,從需求到下單至少需要4個核心槽位。A電影名,B電影院,C場次,D幾張票。(選座可以提供默認規則)
想要完成訂單的確認,則成功引導用戶填充ABCD四個槽位即可。好的完善和引導,則是:
如果用戶填充了AB,AI應該追問CD的例子:我想看《魔童哪咤》,幫我在附近找個最近的電影院。此時AI需要展示哪幾個場次可以選擇,然后追問要買幾張票
如果填充了ABC,應該追問D的例子:我想看《魔童哪咤》,附近找個最近的電影院,8點鐘左右開場的。此時AI只需要追問要買幾張票即可。
ABCD四個主槽位,無論用戶的先后順序,先填充哪個槽位,后續能夠完善填充即可。
人類的表述千奇百怪,無論多少個槽位,人類都可以組織語言聯合起來表述。亂序填充槽位才是智能化,自然表述的的基本要求。
Part 3 篇幅所限的階段性結尾
筆者剛進入AI行業NLP領域工作的時候,夢想著有一天能夠做出偉大的產品。
什么算偉大的產品,每個人定義不同。
從業以來,就我們目前技術發展的前提下,能做的真的有限。科幻影視作品里面的超級人工智能,目前來看似乎遙不可及。
遂化為小白用戶,提出一個最為直白的需求。
“我就想要一個聰明且好用的智能助理,能夠滿足我生活中的各種需求。”
所以在當前的技術實現下,輸出了過往在工作中一些評測產品以及處理問題的具體表現。
實際上,原本在意圖理解這個單元模塊,有更多評測點去列舉,但是受限于篇幅以及能力所限,刪掉的一些內容。
用提問的方式,列舉一下我刪除掉的指標
- (6)如何做到個性化/智能化推薦?
- (7)多輪對話中,如何處理‘指示代詞’以及推理?
- (8)對話過程中,如何應對多個話題的來回跳轉?
- (9)如何基于用戶的音色,判斷用戶身份,并設置服務權限?
- (10)如果用戶在描述某個問題表述不清晰,如何處理?
- (11)如果用戶表達的文本過長,意圖過多,如何處理?
- (12)用戶話說到一半,能不能猜測,并提前完成服務?
上述我提到的種種問題,其實都可以設計考核指標。
筆者可以講清楚是什么,解決方案以及思考后續會以獨立文章的形式分享。
既然是評測指標,自然是有權重之分。
有些是可以努力做好的部分,比如前文中就【意圖理解】這個維度提及的5個模塊,各個例子的列舉,都是基于用戶的對話日志后臺,是實際業務中非常高頻的。
而另外的有些是重點加分項,有些是附加加分項來評定。
【意圖理解】越深,越到位,都是讓我們極盡所能,在【意圖理解】這個維度,無限逼近超級人工智能的種種思考。
而筆者的思路是,用戶盡管提要求,余下的盡量去想辦法去實現,如此才能夠盡量去逼近偉大的產品。



















