













輕量級 CMDB,重量級賦能,聊聊 CMDB 建設中的痛點與經驗
備注:本文根據演講者視頻語音速記整理而成,如有圖文不妥,請以視頻為準。
很高興能有機會跟大家一起來交流一下 CMDB 的建設。屏幕前的各位應該都是運維的伙伴,那么大家對于 CMDB 應該都很有了解,我相信有10個人里面有9個人對 CMDB 的理解是不同的,在平日里跟其他同事、同仁交流時,我們都會說 CMDB 可能就是應用關系的一個記錄,一個應用關系的庫;還有就是CMDB ,Configuration Management 就是一個配置管理,那配置到底包含什么關系?是不是需要包含一個全鏈路的東西,比如層應用,應用、數據庫、交換機是不是一個配置?還有物理機、虛擬機等我們是不是把它錄進來。
也有朋友可能會很詫異,現在都已經上云了,云上有這么多的資源管理控制臺,可以在生產虛擬機為這個instant去打標簽,在我們需要用到它的時候,可以通過標簽來搜索和定位應用在哪個服務器上,這些我相信大家說的都是正確的,但隨著業務規模越來越大,CMDB的維度也是越來越多。CMDB可以是一個簡單二維的統計表,也可以是一個多維立體覆蓋的模型,如果一開始沒有一個好的規劃,那做到后面 CMDB 是承受不了這樣的復雜性的。
不知道大家有沒有這樣的感覺,CMDB 剛開始的時候建的非常的順利,不管是從云上,我們把數據拉回來存在本地,還是我們自己拿一些 agent 去采一些虛擬機的數據。但隨著業務規模的不斷增加,隨著不斷把一些模型,比如說把一些關系加到 CMDB 里面去,到了這時會發現,我們的模型非常的復雜,而且根本就沒有辦法維護,這時 CMDB 就變成了一個垃圾場。
今天要跟大家分享的是如何快速的打造一個能夠持久使用的 CMDB。相信聽過今天的三部曲之后,大家會有一個新的認識。
首先我們還是回到概念上來,CMDB 是什么,為什么一定要建 CMDB?大家都知道工具是為了解決同一個反復的問題或反復的場景減少重復勞動提高生產效率的產物,那么 CMDB 也是這樣。
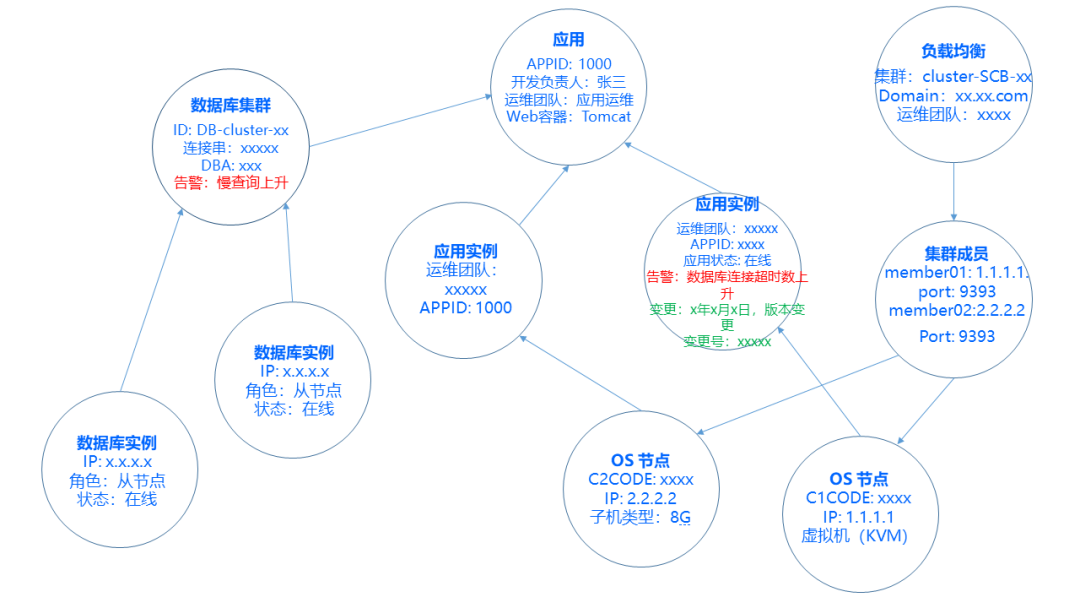
我們來看一張圖,這張圖是我們現在的排障圖,因為銀行有一些規定,沒辦法直接把行內的截圖發出來,所以跟大家手繪一張。
首先從左上角開始,左上角是負載均衡的集群,這也是一個模型,這個負載均衡里面有寫集群的ID、域名以及運維團隊相關負責人,負載均衡下面是集群Member,這里面是集群成員,有端口號、IP,這個 Member 會指到兩個OS節點上,兩個OS就是系統節點,這個節點的數據就記錄著系統IP地址,虛擬化的版本等系統級別的信息。
系統信息級別的上層是應用實例,應用實例會有應用APPID,我們每一個應用都會有獨立的ID,這個ID代表了這個應用的畫像,這個ID是什么容器,是什么外部容器,它的語言、發布版本周期、發布變更窗口等等都是圍繞應用的。
這一層就是我們的應用了,應用的上面,在這個地方就是APPID的模型,針對應用產生兩個實例,它們帶有獨立的IP屬性,這個應用就是我們的應用畫像。
接著這個應用右邊是數據庫集群,在CMDB里面我們作為一個服務對象承載,應用使用服務,這是我們數據庫服務。數據庫服務里面會有集群的ID,數據庫的類型,數據庫的庫名以及維護的團隊DBA,這個集群下掛了兩個數據庫實例,這兩個實例它們的區別是在于有一主一從,如果是MySQL的話,那么它們角色就是主從關系。
在這樣的排障圖情況下,假設今天有一個報警,紅色的地方報了數據庫集群,報了一個警,說這個數據庫集群有一個慢查詢,然后數據庫實例在組節點上面發現了DB的Session異常升高了,與此同時在我們OS的節點上,我們發現主機的 TIME_WAIT 數有增加,那在我們應用實例里面,我們現在通過CAT埋點,我們可以拿到在代碼執行過程當中互相調用鏈的SLA的響應時長,對對方的SLA,在這個地方有一個報警,到現在有調用數據庫TIMEOUT,這是一個告警,告警最底層藍色的字體是CMDB源數據,我們把告警覆蓋上去,今天出來的告警覆蓋到這張圖上面,然后我們與此同時把變更的記錄覆上去,變更記錄是綠色的這邊,我給大家讀一下,變更信息:某年某月某日某個版本發生了變更,變更號。
如果排障的時候如果把這張圖放在外面的話,我們其實是很容易能判定出哪個應用受到了什么影響,并且影響范圍是什么,可能是因為有什么變更導致的。這個就是CMDB典型的場景。CMDB的數據遠遠不止這些,可以通過學習,通過分析,所有的數據都是覆蓋在CMDB之上的,所以CMDB源數據是一個非常重要的基礎數據,那如果說我們今天沒有CMDB,這些東西全部都在腦子里面,我知道某一個應用它下面有幾臺機器,然后這個機器前面掛了一個F5,我知道它連著數據庫是什么,那如果說你所知道的這個東西擴展到一千倍,你還會記得嗎?可能你的當時腦子里是這個樣子的。
一、建模階段
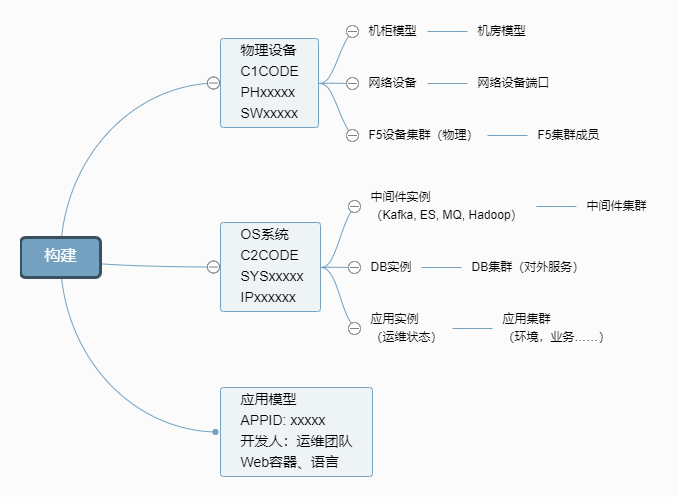
我相信剛剛這張圖已經足以讓大家知道我們的 CMDB 有多大的用途。接下來我來告訴大家說一下CMDB的建設,CMDB的建設分三個階段,第一個階段是建模階段,我們來看一下這個模型,首先我們要確定一下,這個模型相對來說是一個比較簡單的模型,這個有物理設備、OS、應用模型,各自這邊會有物理模型、機柜、機房還有物理設備,網絡接口、網絡設備到物理設備,還有我們F5的集群,集群成員,物理的集群,到網絡設備。
我們剛剛看到這些集群里面,其實并不是所有的信息我們CMDB都會需要,哪些CMDB我們需要,首先第一個我們平時用得到,我們排障用得到的管理信息、狀態信息這部分是不可少,今天有一個報警必須找到,對不對?剛才說到管理信息,狀態信息這個東西也是不可少,因為CMDB本身就是管理配置的生命周期,你所有的主機節點是不是上線、在維護中、帶部署了、在使用中,這些都需要有,是一個虛擬機的生命周期。不單單是虛擬機需要生命周期,包括我們的實例,包括我們的 DB,都可能拉入、拉出、維護或者是帶部署等等狀態,那這些狀態信息用來干什么?是用來告警抑制的時候或者是自動上架,然后還沒有對外提供服務能力的時候,我們可以把這些告警給抑制掉,包括你今天正常計劃的拉入、拉出,這些原本是不需要發出告警的,所以我們要可以通過狀態的變化來把告警浸沒。
然后第二個就是我們是按照一個領域來劃分,我們在看一下這張圖,其實每一條線都是一個領域,所謂的領域就是相對來說,因為這個領域跟我們組織架構有點關系,比如說設備組,它負責的領域就是機房機柜、物理設備;
網絡組負責網絡交換機、防火墻、代理、VPN等等網絡設備,所以它的領域網絡設備和網絡設備的端口,我們ADC的團隊主要負責F5的,那么F5的領域包括物理集群、邏輯集群、member,這些都關聯到物理設備上。
下面是系統節點,系統節點也出現很多領域,比如說中間件的,Hadoop、ES、Kafka,主要是一些指Member等等這些,還有我們DB,DB實例、DB的集群、DB的實體,
最下面是我們的應用,應用運維,有負責應用領域,也有應用實例、應用集群、應用畫像。
大家有沒有看到數據模型領域很多,但是彼此領域之間是沒有交際的,有沒有看到?領域和領域之間不會建立模型不會建立關系,它們的關系永遠都是對應到一個相對集中點,物理設備的,設備組所有領域信息都是歸結到物理設備上,網絡歸結到物理設備上,F5也是歸結到物理設備。
有人問F5的集群里面的Member是主機又不是物理設備,像主機節點我們全部關聯到節點OS上,盡量我們把領域跟領域之間不作為互相交互,他們只關聯具體的三個大的模型上,這個有一個什么好處?我們在剛開始的時候建數據的時候,可能數據量不是很多,服務器數量不是很多,那如果我上報一個虛擬機,我還要把應用關系,還要把F5關系全部報給你可以嗎?可以,但是時間長了,閉環會越來越重,就是越來越吃閉環,如果今天哪個流程出現問題的時候,你的數據就亂了,你根本沒有辦法去治理它,所以保證上傳的數據只是在這個領域內部去做三層的結構。
怎么理解內部做三層結構?我們舉個例子,我們拿網絡來舉例,網絡的是有一個網絡設備端口,網絡的設備端口一定是屬于某一個網絡設備的,那這個網絡設備和這個網絡設備端口是一個1比多對應的集群關系,網絡只需要維護好自己的這一份數據,確保集群每個端口都會對應一個集群,一個集群下就一定會有48個口,交換機48個口,它只要把這層數據關系關聯好,把網絡設備關聯到我們某一個物理設備上,因為這當中是有CI號,每個設備都會有CI號,這是唯一的,所以一定不會關聯錯,這個時候全都上報到CMDB,那CMDB接下來就可以做很多關系,只要有這一份關系,就可以透過這層關系幫你建出你的拓撲。
就是我們剛剛看到這張圖,這張圖片所有的數據關系都是CMDB建出來的,所以在采集數據的時候,它們彼此之間其實是不知道關系的,明白嗎?只有自己的領域之間集群和Member這個之間是自己有關系,但是它不知道對應的應用是什么,F5不知道應用是誰?剛不會知道下面數據庫關系是什么。
這個就是我們說的建模,為了要增大你數據靈活性和拓展性,所以我們必須要把模型變得更簡單,關系變得更簡單,把復雜的邏輯,復雜的數據關系帶到CMDB,這是一個大忌。
二、閉環
第二階段我們建完模之后要先做閉環,我們的閉環數據是非常重要,在CMDB里面沒有閉環這個數據就是不可信的,閉環是保證數據準確性的基礎,閉環的方式可以通過強留層驅動,可以通過服務目錄或者流程引擎。
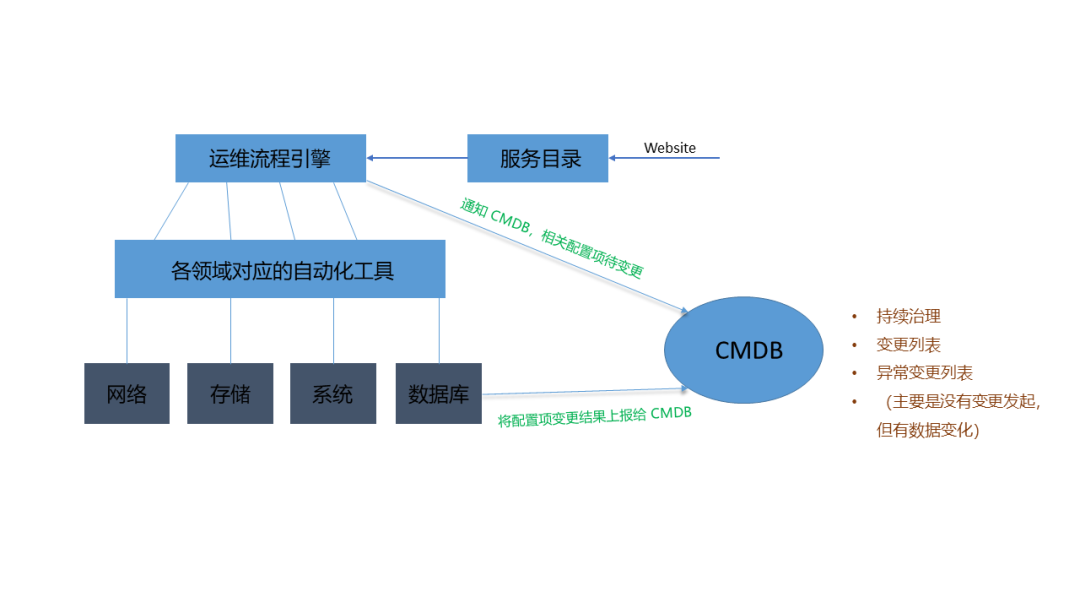
那我們這邊簡單說一下流程引擎的思想,一個用戶在訪問我們服務目錄的時候,會去訪問運維的流程引擎,那之后運維流程引擎下發所有任務讓自動化工具系統去執行,執行完了之后這些工具系統會告訴自己的領域,因為這些工具都是領域內部的自動化工具,自己的領域都會收到相關的一些信息,比如說今天要做一個擴容,虛擬機擴容從2擴變成4擴,那這個流程下去之后就會下發到系統的領域,系統的領域知道我現在某一個虛擬機變成4擴,它記錄數據并且上報,將增量的部分上報給CMDB,告訴CMDB現在我有一臺虛擬機,從2擴變成了4擴了,那么CMDB收到這部分數據的時候,它能不能信?
CMDB 不能隨便的去更改我們庫里面的源數據,必須要有強流程的驅動,所以在流程引擎在執行的時候,會放給CMDB一條信息,告訴CMDB說接下來會有一個什么機器的,它的2擴要變成4擴,這個是通常我們說到CMDB B表,那領域上報就是一個C表,B表跟C表一參照,匹配上就是一個正常變更,我允許你變更數據,如果沒有匹配上,它上報的這條數據將會列入到異常上報數據,這個時候我們可以反過來去推行,說為什么今天2擴會變成4擴,是因為沒有任何的變更驅動來做這個事情了,這樣就形成了一個閉環。
我們先把這種閉環建立起來再去錄入CMDB數據,今天也許有些伙伴說,我今天只是想搜集一下服務器的數據,在云上可能我的拿一個API就把全量的數據拿過來,但是我們有沒有想過你今天拿全量的數據拿過來,接下來你在產一臺機器的時候,你的數據怎樣進來?可能你需要定期不斷去拿API,不斷拿全量的數據,永遠去覆蓋掉你的CMDB完整數據,那我覺得CMDB不應該這樣做,它應該去保留說你的所有變更記錄,CMDB里面的數據每一條變更記錄都是需要被保留審計的。
所以今天在云上面創立主機的時候,你要先想要你今天在創建這個主機的時候,怎么樣讓CMDB先知道這條信息,然后你在通過API的方式去拿到這臺消息上報的時候,那CMDB會對你已經告訴它要更改的數據做一個修改,這個就是閉環。
閉環沒有建立起來,所有的數據都是不可信的,這是我們第二階段的閉環。
三、解決存量
第三階段是解決我們的存量,存量讓我們要改變一些思維的方式,首先,我們要相信領域,我們剛剛說這些搜集的數據,今天我們說按照組織架構,有網絡組,網絡組可以提供權威的領域數據,如果今天團隊規模比較小,沒有,那也沒有關系,我們就把它單獨看作是一個領域上報,這里有一個思維要轉變一下,我們盡量不要CMDB去下探,去拿它的東西,而是作為一個上報的過程,有什么好處?
第一個,你今天下探去拿東西的時候,你未必拿的全,第二個你的拿回來的東西,如果是CMDB去拿,你可能直接就進庫了,如果是上報的方式,你把一個網絡領域單獨獨立出來,你可以對它整個生命周期做管理,因為你第一次拿和第二次拿都在你網絡領域里面已經感知到了,它不會撞了CMDB的數據,哪些東西需要上報到CMDB,是哪些有變化有增量的東西會上報到CMDB里面去,所以這樣的話CMDB就可以做到有一個更簡單、可追溯、可校驗的過程。所有的CMDB變更記錄一定要把它給記錄起來,每一條記錄的變更,誰來變更這些都是一個之后可回溯的關鍵方法。
那么解決存量我們還有一個問題要解決,我的分布是什么,我怎么知道你這個領域里面應該有多少個機器,因為領域上報過來,你作為一個CMDB你接受領域上報的所有數據,你相信它是權威,我相信你的數據,但是我也要幫你做一個交叉比較,那怎么做交叉比較其實很簡單,我們可以放一臺機器,拿一個主機來說,可以在某一個網段放一個機器,去全網掃,整個C端里面去掃所有的端口,去通過端口的特征來判斷它是一個什么樣的主機,是一個什么樣的設備,這是一種方式,還有一種方式我們自建IDC的,我們可以拿到整個交換機 ARP 表,我們銀行現在主要是做TOP的架構,柜頂一個,一行柜,然后會有一個匯聚,多個匯聚形成一個核心,所以我們在每個柜頂上都可以找到ARP表,有了這些ARP表我就知道現在整個生產環境的分布有多大,這是一種探測的方法,不能單單靠我們領域上報過來的數據,我們還需要有自己幫助領域去加強去準確它上報數據的覆蓋度。
那么接下來我們要說一個邏輯的交叉比對,是怎么樣子的?比如說我們今天上報物理機的過程當中,現在有5臺物理機,這5臺物理機都是屬于EXS的系統,那么我要保證這5臺EXS的系統都能被我們虛擬機關聯上,我們云團隊會把所有虛擬機報上來,那所有的虛擬機是不是都落在這5臺上,如果都落在這5臺上沒有問題,如果沒有落上,我們看一看有某些物理機沒有被關聯上是因為它沒有在使用中還是它漏報了,這是一種交叉比對的方式,不管是ARP表的比對還是交叉比對,乃至于今天到生產上找一臺機器,去用 TCPdump 找出上下游的關系,這也是一種方法。
可以找到在生產上所有活躍的IP,這些IP是不是所有活躍在CMDB當中都被落到某一個對象里面去,這樣的方式就可以持續去做,需要有一個報表的體系去推動數據的治理,因為我們都知道 CMDB 這個東西數據準確率是非常重要的一項,如果今天的數據準確率不按照這個報表體系,每天每周去跟進去處理的話,當然你后面還要去建立一些像SLA處理及時率這些東西,來考核每個領域數據的準確性,只有這樣我們的CMDB才能夠持續穩健成長。
那接下來我們要說在我們完成三階段,我們把CMDB建設起來了,但是我們最重要的環節就是剛剛說到,我們把CMDB的數據弄進來之后,只能解決這個每一層的關系,現在還不具備通過一個機柜能夠知道DB相關信息,整天鏈都不知道。
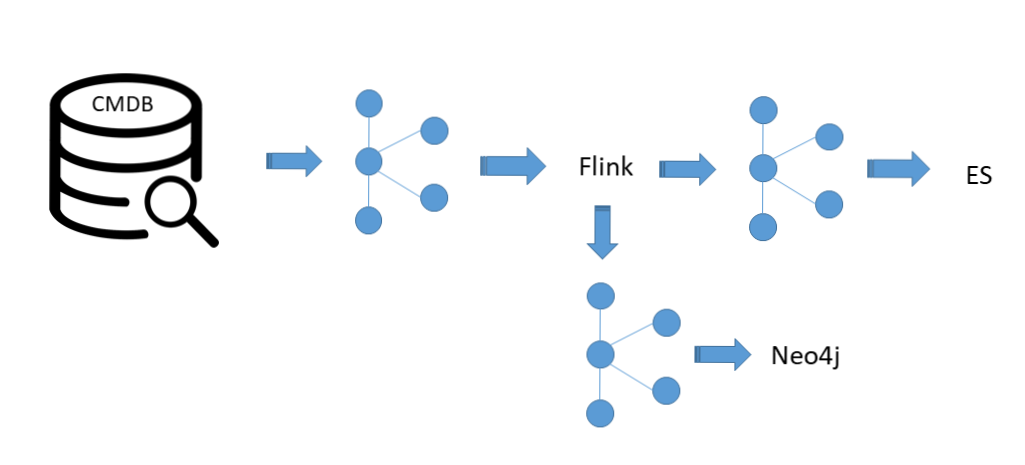
那么接下來就是另外一個,當我們完成 CMDB 構建的時候,接下來要做關系了,如何構建一個復雜的關系實現一個快速的檢索,我們看一下這套架構圖,這個是我么CMDB,我們的源數據在這里,所有變更事件會推到 Kafka 隊列,所有變更事件,比如說今天進來一條數據,這條數據產生變化,會把這些變化推到Kafka,Flink 會經過一段流程處理,然后加工,可以不加工,加工是業務需求,然后在這個當成主要做一些格式,為了更好去檢索使用,然后就推到ES去了。
上面這條路能實現什么,上面這條路能夠實現快速模糊查詢,我們可以輸入一個IP,可以輸入一個APPID,可以輸入一個CICODE,乃至于我今天輸入一個聯系人,我都可以去找到所有相關的信息,它雖然說還無法完成這個圖,但是至少可以有類似于百度的一些信息,你百度一個模糊查詢,我搜索一個人名,我是不是可以搜索到相關的管理員是他所有的模型記錄,在ES里面這個不難做到。
現在 CMDB 的模型大概是在30個左右,導到ES里面也是30張獨立的表,大概的字段是在700接近800個,全面索引,目前這個數據量在二三十萬條記錄這樣子,壓力也沒有壓力,ES集群也是用的虛擬機做的,也沒有什么特別厲害,因為ES就擅長做這件事情。
要實現這張圖,我們還需要借助于優秀的東西叫做NEO4J,NEO4J 這個數據庫最近也是炒得比較火,我們從 Flink 拿一條數據進入到NEO4J,原生的進去,之前是什么關系我還是什么關系進去,不加任何關聯關系,直接把這層的關系直接導入到 NEO4J 通過數據庫去變例出來,去能實現這樣的一張條,這樣藍色部分所有都是NEO4J可以搞定的事情,然后接下來我在把變更記錄往NEO4J里面導,把告警記錄往NEO4J里面導,所做出來就是一層一層帶著告警帶著源數據,帶著變更日志的信息了。
NEO4J 它的處理能力是比較高,處理十多個億這樣的關系節點也是非常的高效,我們的使用來說還是比較小的,也就幾十萬節點而已,大概在30萬關系左右進入NEO4J。
總結
因為時間有限,沒辦法每個地方都展開精細的說明,再回顧一下今天的內容,CMDB首先要有三個階段,第一個階段要建模,建的模型一定要夠簡單,它的關系只關聯到 OS就夠了,領域跟領域之間不要做額外的關聯,關聯 NEO4J 會幫我們輕松的搞定。
第二,要解決閉環的問題,因為閉環是 CMDB 的基礎,必須先要有閉環然后才能得到增量,負責天天全量不行。
第三,是解決存量的問題,解決存量問題的時候,我們要記得一定要交叉比對,要對上報的數據持有懷疑,雖然說它是領域是權威數據,但是 CMDB 一定要對上報數據有懷疑,去發現,去想辦法去探測等等手段去幫助領域上報的數據做到更全、更準。
有了這三步之后我們要持續做報表,將有問題的數據及時的拋出來,因為時間長了之后對數據的治理難度很高,比如你今天做了一個變更,這個變更可能沒有及時更新上 CMDB,CMDB 第二天發現了,如果不報出來,過了三五天之后,這個數據的這條變更沒有人記得,也許它就在我們記錄變更表當中,但是很難去找到它,大家可能想不到,所以要及時去處理,想盡一切辦法去推動這個數據的整改和治理,CMDB建完之后可以通過ES來做檢索,可以通過NEO4J來做拓撲,當中只需要 Kafka 把變更的數據持續往ES里面更新,CMDB進ES的數據,可以原封不動,一張模型一張表這樣導進去,進NEO4J的時候可以把 CMDB 的數據一個一個,原來的模型是怎樣就導進去,不需要增加新的模型,NEO4J會為我們處理拓撲模型。
道家有個說法叫做萬變不離其宗,不管上層的邏輯做的多復雜,CMDB 永遠保存住最原始的關系,這是最好的,這樣能保存它的擴展和復雜度永遠維持在一個相對穩定的水平線上,那《道德經》當中也有一句話也是說過,萬物之始,大道至簡,衍化至繁,咱們CMDB 也是如此。



















