













輕量級模型,重量級性能,TinyLlama、LiteLlama小模型火起來了
當大家都在研究大模型(LLM)參數規模達到百億甚至千億級別的同時,小巧且兼具高性能的小模型開始受到研究者的關注。
小模型在邊緣設備上有著廣泛的應用,如智能手機、物聯網設備和嵌入式系統,這些邊緣設備通常具有有限的計算能力和存儲空間,它們無法有效地運行大型語言模型。因此,深入探究小型模型顯得尤為重要。
接下來我們要介紹的這兩項研究,可能滿足你對小模型的需求。
TinyLlama-1.1B
來自新加坡科技設計大學(SUTD)的研究者近日推出了 TinyLlama,該語言模型的參數量為 11 億,在大約 3 萬億個 token 上預訓練而成。

- 論文地址:https://arxiv.org/pdf/2401.02385.pdf
- 項目地址:https://github.com/jzhang38/TinyLlama/blob/main/README_zh-CN.md
TinyLlama 以 Llama 2 架構和分詞器(tokenizer)為基礎,這意味著 TinyLlama 可以在許多基于 Llama 的開源項目中即插即用。此外,TinyLlama 只有 11 億的參數,體積小巧,適用于需要限制計算和內存占用的多種應用。
該研究表示僅需 16 塊 A100-40G 的 GPU,便可在 90 天內完成 TinyLlama 的訓練。

該項目從上線開始,持續受到關注,目前星標量達到 4.7K。

TinyLlama 模型架構詳細信息如下所示:

訓練細節如下:

研究者表示,這項研究旨在挖掘使用較大數據集訓練較小模型的潛力。他們重點探究在用遠大于擴展定律(scaling law)建議的 token 數量進行訓練時,較小模型的行為表現。
具體來說,該研究使用大約 3 萬億個 token 訓練具有 1.1B 個參數的 Transformer (僅解碼器)模型。據了解,這是第一次嘗試使用如此大量的數據來訓練具有 1B 參數的模型。
盡管規模相對較小,但 TinyLlama 在一系列下游任務中表現相當出色,它的性能顯著優于同等大小的現有開源語言模型。具體來說,TinyLlama 在各種下游任務中都超越了 OPT-1.3B 和 Pythia1.4B 。
此外,TinyLlama 還用到了各種優化方法,如 flash attention 2、FSDP( Fully Sharded Data Parallel )、 xFormers 等。
在這些技術的加持下,TinyLlama 訓練吞吐量達到了每 A100-40G GPU 每秒 24000 個 token。例如,TinyLlama-1.1B 模型對于 300B token 僅需要 3,456 A100 GPU 小時,而 Pythia 為 4,830 小時,MPT 為 7,920 小時。這顯示了該研究優化的有效性以及在大規模模型訓練中節省大量時間和資源的潛力。
TinyLlama 實現了 24k tokens / 秒 / A100 的訓練速度,這個速度好比用戶可以在 8 個 A100 上用 32 小時訓練一個具有 11 億參數、220 億 token 的 chinchilla-optimial 的模型。同時,這些優化也大大減少了顯存占用,用戶可以把 11 億參數的模型塞入 40GB 的 GPU 里面還能同時維持 16k tokens 的 per-gpu batch size。只需要把 batch size 改小一點, 你就可以在 RTX 3090/4090 上面訓練 TinyLlama。


實驗中,該研究主要關注具有純解碼器架構的語言模型,包含大約 10 億個參數。具體來說,該研究將 TinyLlama 與 OPT-1.3B、Pythia-1.0B 和 Pythia-1.4B 進行了比較。
TinyLlama 在常識推理任務上的性能如下所示,可以看出 TinyLlama 在許多任務上都優于基線,并獲得了最高的平均分數。

此外,研究者在預訓練期間跟蹤了 TinyLlama 在常識推理基準上的準確率,如圖 2 所示,TinyLlama 的性能隨著計算資源的增加而提高,在大多數基準中超過了 Pythia-1.4B 的準確率。

表 3 表明,與現有模型相比,TinyLlama 表現出了更好的問題解決能力。

手快的網友已經開始整活了:運行效果出奇得好,在 GTX3060 上運行,能以 136 tok / 秒的速度運行。

「確實是快!」

小模型 LiteLlama
由于 TinyLlama 的發布,SLM(小型語言模型)開始引起廣泛關注。德克薩斯工農大學的 Xiaotian Han 發布了 SLM-LiteLlama。它有 460M 參數,由 1T token 進行訓練。這是對 Meta AI 的 LLaMa 2 的開源復刻版本,但模型規模顯著縮小。
項目地址:https://huggingface.co/ahxt/LiteLlama-460M-1T
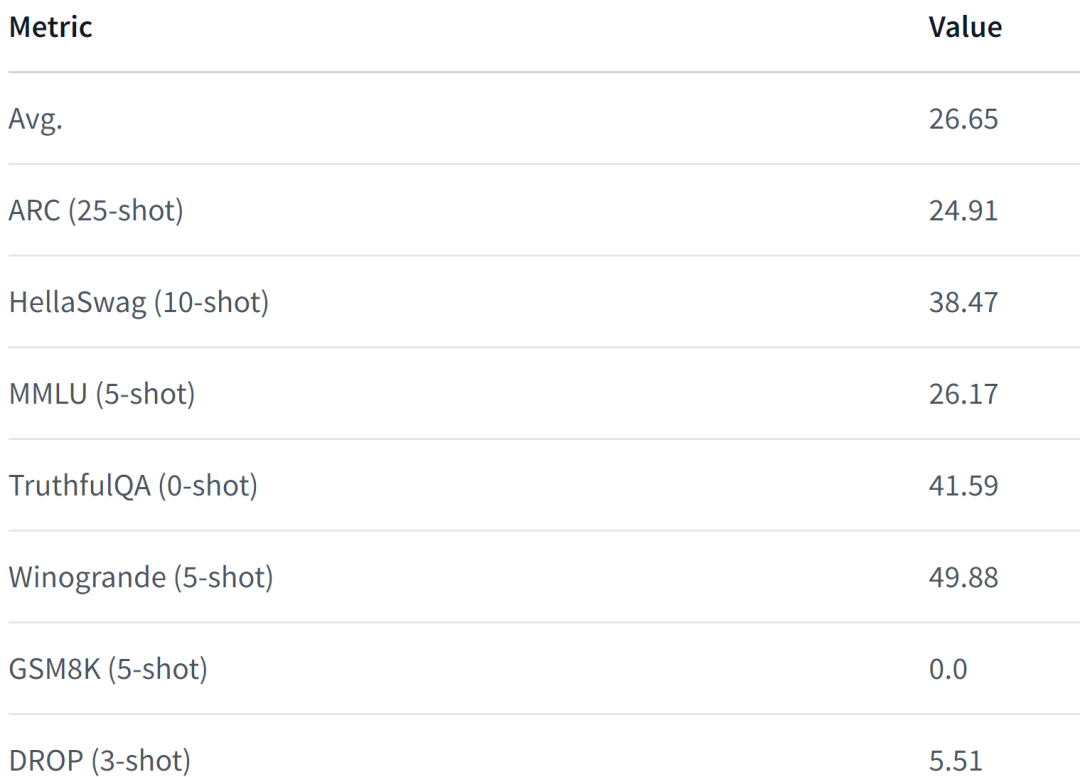
LiteLlama-460M-1T 在 RedPajama 數據集上進行訓練,并使用 GPT2Tokenizer 對文本進行 token 化。作者在 MMLU 任務上對該模型進行評估,結果如下圖所示,在參數量大幅減少的情況下,LiteLlama-460M-1T 仍能取得與其他模型相媲美或更好的成績。

以下為該模型的性能表現,更詳細內容請參閱:
https://huggingface.co/datasets/open-llm-leaderboard/details_ahxt__llama2_xs_460M_experimental
面對規模大幅縮小的 LiteLlama,有網友好奇,它是否能夠在 4GB 的內存上運行。如果你也想知道,不如親自試試看吧。





















