為什么我們選擇了MongoDB?
我司是一家正處于高速發(fā)展,目前擁有數(shù)百萬用戶,年銷售額近五十億的社交電商公司。
公司技術(shù)部建立之初,為了適應(yīng)用戶量的高速增長,與業(yè)務(wù)的不斷變更迭代,在選用數(shù)據(jù)庫的時候,經(jīng)過調(diào)研對比我們選擇了 MongoDB。
是的,你沒看錯,All in MongoDB!
本文將圍繞如下幾個部分進(jìn)行分享:
- 為什么使用 MongoDB(選擇數(shù)據(jù)的時候我們是怎么考慮的?)
- MongoDB 架構(gòu)(99.99% 高可用,晚上安心睡大覺!)
- MongoDB 分片(海量數(shù)據(jù)應(yīng)對之道!)
- MongoDB 文檔模型介紹(靈活!靈活!靈活!)
為什么使用 MongoDB
因為我司主要做社交電商的業(yè)務(wù),所以對數(shù)據(jù)庫的性能有一定的要求,加上商品交易是公司主要盈利來源,所以對數(shù)據(jù)庫的高可用也有一定的要求。
總結(jié)一下我們對數(shù)據(jù)庫的要求:
- 安全,穩(wěn)定
- 高可用
- 高性能
我們在考慮數(shù)據(jù)庫選型的時候主要考慮什么?
- 數(shù)據(jù)規(guī)模
- 支持讀寫并發(fā)量
- 延遲與吞吐量
從數(shù)據(jù)規(guī)模來說訂單和商品 SKU,還有會員信息這些重要的數(shù)據(jù)記錄肯定會隨著時間源源不斷的增長。
所以我們需要的不僅僅是滿足當(dāng)下要求,更需要為半年一年后海量數(shù)據(jù)更為方便的擴(kuò)容做考量!
下面我們從 MongoDB 的架構(gòu),性能,和文檔模型來介紹一下我們選擇 MongoDB 的理由!
MongoDB 架構(gòu)
①關(guān)于高可用
數(shù)據(jù)庫作為系統(tǒng)核心,要保證 99.99% 的可用性,而高可用的保證來自于 MongoDB 冗余數(shù)據(jù)的復(fù)制集模式。
MongoDB 自帶多副本高可用,只需要合理的配置,就能避免單數(shù)據(jù)庫節(jié)點故障導(dǎo)致服務(wù)的不可用。
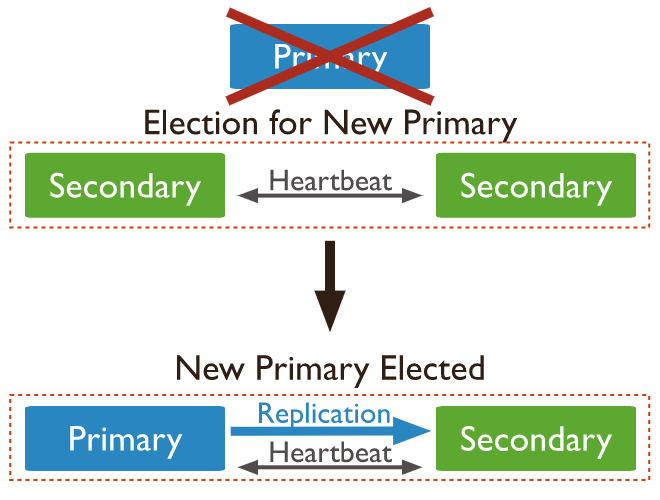
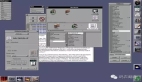
圖例說明:
- 一個 Primary 主節(jié)點,主要接受來自 server 的讀寫。
- 兩個 Secondary 從節(jié)點,用于同步來自 Primary 的數(shù)據(jù)。
關(guān)于高可用:當(dāng)主節(jié)點發(fā)生故障的時候,兩個從節(jié)點會進(jìn)行選舉,投票產(chǎn)生一個新的主節(jié)點,進(jìn)而保證服務(wù)的可用性。
PS:在選舉過程中數(shù)據(jù)不可寫入,但是如果 Secnondary 節(jié)點配置可讀,那么此時是可以讀取數(shù)據(jù)的。
這就是 MongoDB 的高可用,配置簡單,不需要引入額外的中間件或者插件去輔助數(shù)據(jù)庫節(jié)點間的故障轉(zhuǎn)移。
②關(guān)于選舉算法《分布式一致性算法---raft》
raft 協(xié)議是在 leader 節(jié)點發(fā)生故障或者網(wǎng)絡(luò)分區(qū)導(dǎo)致腦裂時如何保證分布式數(shù)據(jù)一致性的一個算法,MongoDB 采用了該算法來保證當(dāng)主節(jié)點故障或者網(wǎng)絡(luò)分區(qū)的情況下,數(shù)據(jù)的一致性。
當(dāng)然 MongoDB 用的和 raft 原版算法肯定會略有不同,MongoDB 會采用 Secondary 向 Primary 拉數(shù)據(jù),而不是 Primary 向 Secondary 推數(shù)據(jù)的方式來減輕 Primary 的壓力等等有利于數(shù)據(jù)庫操作的方式對 raft 進(jìn)行改進(jìn)使用。
raft 算法動畫演示:
- http://thesecretlivesofdata.com/raft/
③關(guān)于超大規(guī)模復(fù)制集(集群)
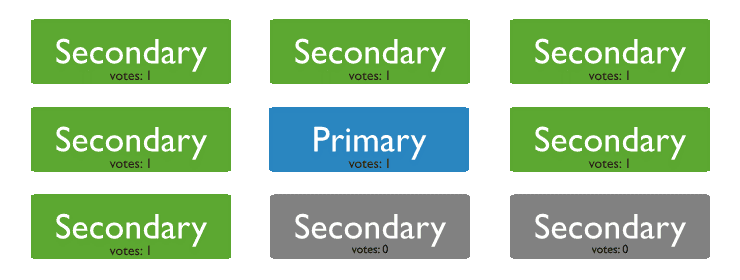
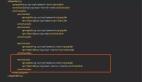
Non-Voting Members
上圖是一個擁有 7 個可投票從節(jié)點,一個主節(jié)點,兩個不可投票從節(jié)點。
- {
- "_id" : <num>,
- "host" : <hostname:port>,
- "arbiterOnly" : false,
- "buildIndexes" : true,
- "hidden" : false,
- "priority" : 0, // 設(shè)置為0
- "tags" : {
- },
- "slaveDelay" : NumberLong(0),
- "votes" : 0 // 設(shè)置為0
- }
MongoDB 最多允許 50 個節(jié)點,但是最多只有 7 個節(jié)點有投票權(quán),一個節(jié)點可以配置 7 個無投票權(quán)的 Non-Voting 節(jié)點,加上一個 Primary 節(jié)點。
為什么只能允許存在 7 個投票節(jié)點呢?參考上節(jié)的 raft 算法,節(jié)點越多,投票時間越長,選舉出來的 Primary 節(jié)點時間也就越長,這個過程中我們是無法進(jìn)行寫操作的,因為沒有主節(jié)點。
那么多非投票節(jié)點有什么用呢?大家應(yīng)該都聽過 MySQL 的讀寫分離吧,利用讀寫分離來提高數(shù)據(jù)庫性能。
MongoDB 這里其實也可以,Primary 用來寫,Secondary 用來讀,可以給 BI 部門一個 Secondary,給財務(wù)部門一個 Secondary,給運營部門一個 Secondary······
④WriteConcern
既然我們的數(shù)據(jù)庫擁有至少超過三個節(jié)點(1Primary+2Secondary),Secondary 通過同步 Primary 的數(shù)據(jù)來保持一致性,那么當(dāng)我們寫操作的時候,如何保證數(shù)據(jù)安全的落盤呢?

有以下幾種情況:
- 寫 Primary 成功,返回客戶端寫成功,Secondary 還未同步 Primary 的時候,Primary 掛了,數(shù)據(jù)丟失!
- 寫 Primary 成功,數(shù)據(jù)同步一個 Secondary 成功,返回客戶端寫成功。此時 Primary 掛了,數(shù)據(jù)不會丟失。但是恰好 Primary 與同步的 Secondary 同時掛了,數(shù)據(jù)丟失!
- 寫 Primary 成功,數(shù)據(jù)同步兩個 Secondary 成功,返回客戶端寫成功。此時 Primary 掛了,數(shù)據(jù)不會丟失。
我們對以上三種情況進(jìn)行分析:
- 第一種情況有風(fēng)險會造成數(shù)據(jù)丟失。
- 第二種情況還是會出現(xiàn)數(shù)據(jù)丟失,但是數(shù)據(jù)丟失的概率大大降低。
- 第三種情況是最安全的做法,但是節(jié)點數(shù)目多了,同步非常耗時,用戶需要等待的時間過長,一般不考慮。
MongoDB 在這里推薦折衷方案就是使用 Write Concern---在數(shù)據(jù)可靠性與效率之間的權(quán)衡!
- db.products.insert(
- { item: "envelopes", qty : 100, type: "Clasp" },
- { writeConcern: { w: "majority" , wtimeout: 5000 } } // 設(shè)置writeConcern為majority,超時時間為5000毫秒
- )
MongoDB 分片
①大規(guī)模數(shù)據(jù)是如何影響數(shù)據(jù)庫效率的?
- 數(shù)據(jù)庫的性能還與數(shù)據(jù)庫本身規(guī)模息息相關(guān)。拿關(guān)系型數(shù)據(jù)庫舉例:
- 查詢百萬表和千萬表甚至過億的表效率相差很大,查詢性能急劇惡化。
插入的時候創(chuàng)建索引可能會引起索引樹的調(diào)整與頁分裂。
②面對海量數(shù)據(jù)如何提升數(shù)據(jù)讀寫效率?
為了在海量數(shù)據(jù)中提升數(shù)據(jù)庫的效率,我們采用分而治之的思想,將大表拆成小表,大庫拆成小庫。
關(guān)系型數(shù)據(jù)庫中我們常用分表分庫來解決:
- 例如將訂單庫分為在線庫和離線庫,近三個月是在線庫,遠(yuǎn)期的訂單數(shù)據(jù)放入離線庫,這樣在線庫的數(shù)據(jù)就大大減少,數(shù)據(jù)庫性能就得到了提升。
- 又例如當(dāng)我們的用戶量過多超過千萬行記錄,單表查詢效率下降,我們將一張用戶表拆成多張用戶表,這個就是水平拆分。
MongoDB 中我們是如何做的呢?
③MongoDBSharding

MongoDB 的分片
通過將同一個集合(Collection1)的數(shù)據(jù)按片鍵(shard keys)分到不同的分片(shard)上面,減少同一個數(shù)據(jù)文件上的數(shù)據(jù)量,已達(dá)到拆分?jǐn)?shù)據(jù)規(guī)模的目的。
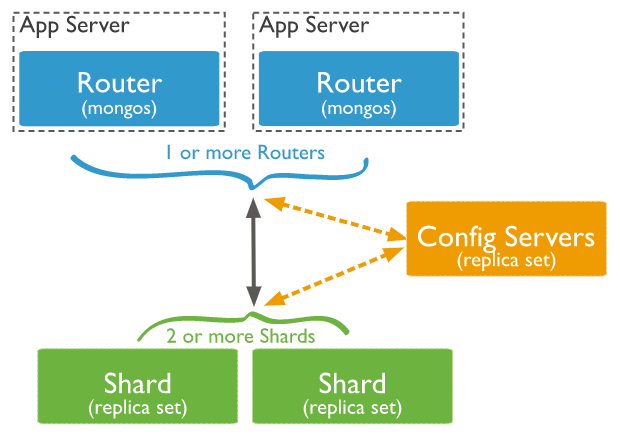
Shard 優(yōu)勢:在線擴(kuò)容,動態(tài)擴(kuò)容
Shard:用于存儲實際的數(shù)據(jù)塊,實際生產(chǎn)環(huán)境中一個 shard server 角色可由幾臺機(jī)器組個一個 replica set 承擔(dān),防止主機(jī)單點故障。
Config Server:配置服務(wù)器 mongodb 實例,存儲了整個集群的元數(shù)據(jù)與配置,其中包括 chunk 信息,在 MongoDB 3.4 中,配置服務(wù)器必須部署為一個副本集。
Mongos:mongos 充當(dāng)查詢路由器,提供客戶端應(yīng)用程序和切分集群之間的接口。
服務(wù)器插入的數(shù)據(jù)通過 Mongos 路由到具體地址,這也是 MongoDB 的便利之處,不需要自己關(guān)注路由,也不需要使用第三方提供的中間件輔助路由,可靠,放心。
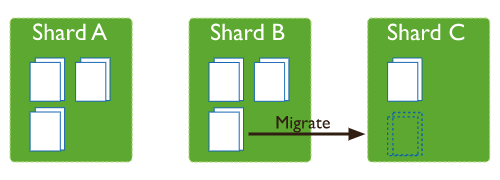
分片的負(fù)載均衡
當(dāng)我們的 MongoDB 副本集變成分片集群后,隨著數(shù)據(jù)量的增長,各個分片也會越來越大。
這里就會出現(xiàn)兩種情況:
- 冷熱數(shù)據(jù),某個分片數(shù)據(jù)量過大。
- 數(shù)據(jù)總量大,分片集群的分片過大。
當(dāng)出現(xiàn)問題(1)的時候,MongoDB 的負(fù)載均衡器(Balancer)會自動將大分片中的數(shù)據(jù)遷往小分片。
注意這并不意味我們可以高枕無憂了,恰恰相反,我們應(yīng)該反思是不是自己片鍵選擇失誤而造成的數(shù)據(jù)不均勻!
因為對分片遷移也是消耗性能的,應(yīng)用服務(wù)器寫一次到 Shard B,然后 Shard B 重寫到 Shard C 無形之中數(shù)據(jù)被寫了兩次,這是極大的浪費!
當(dāng)出現(xiàn)問題(2)的時候,當(dāng)然是給過大的分片集合添加新的分片以此分?jǐn)偡制旱膲毫Α?/p>
注意:MongoDB 分片雖然是可在線的,但是多少都會對正常的讀寫操作性能有一定的影響,建議在非繁忙時間段進(jìn)行分片部署!
MongoDB 文檔模型介紹
數(shù)據(jù)庫建模的挑戰(zhàn)在于平衡應(yīng)用的需要,適合該數(shù)據(jù)庫引擎發(fā)揮的結(jié)構(gòu)以及數(shù)據(jù)的檢索模式。
當(dāng)我們設(shè)計數(shù)據(jù)模型的時候,需要考慮應(yīng)用使用數(shù)據(jù)的情況(查詢,更新,和數(shù)據(jù)處理)以及該數(shù)據(jù)本身的結(jié)構(gòu)。
①靈活的 Schema
在關(guān)系型數(shù)據(jù)庫中,必須按照確定的表結(jié)構(gòu)去插入數(shù)據(jù)。但是,由于 MongoDB 是文檔型數(shù)據(jù)庫,在插入數(shù)據(jù)的時候默認(rèn)并不對此做要求。
其表現(xiàn)在于:
- 同一個集合中不同文檔不一定需要有相同的字段,并且字段類型也可以不同。
- 在集合中改變文檔的結(jié)構(gòu),例如增加一個字段,刪除一個字段,或者改變一個字段的類型,只需要對該文檔更新即可。
②舉例 1:N 模型設(shè)計
在電商業(yè)務(wù)中,一個用戶可能有多個收件人以及收件地址。在關(guān)系型數(shù)據(jù)庫中,我們需要建立聯(lián)系人表,地址表,并且將其關(guān)聯(lián)。但是在 MongoDB 中,我們只需要一個集合就能將此搞定!
數(shù)據(jù)關(guān)系如下:
- // patron document
- {
- _id: "joe",
- name: "Joe Bookreader"
- }
- // address documents
- {
- patron_id: "joe", // reference to patron document
- street: "123 Fake Street",
- city: "Faketon",
- state: "MA",
- zip: "12345"
- }
- {
- patron_id: "joe",
- street: "1 Some Other Street",
- city: "Boston",
- state: "MA",
- zip: "12345"
- }
在 MongoDB 中我們可以這樣進(jìn)行設(shè)計:
- {
- "_id": "joe",
- "name": "Joe Bookreader",
- "addresses": [
- {
- "street": "123 Fake Street",
- "city": "Faketon",
- "state": "MA",
- "zip": "12345"
- },
- {
- "street": "1 Some Other Street",
- "city": "Boston",
- "state": "MA",
- "zip": "12345"
- }
- ]
- }
沒錯,以上就是集合中的一個 document(文檔),是不是感覺很靈活很方便!
你可以在 SKU 集合中添加分類信息,或者商品標(biāo)簽,還可以在庫存集合中冗余 SKU 的基本信息,還可以在訂單集合中冗余部分下單者信息···沒錯,就是這么靈活!
這也是我們選擇 MongoDB 的一個重要原因之一,讓開發(fā)者的心智負(fù)擔(dān)少了很多,不需要成為 SQL 高手,你也能在 MongoDB 中寫出性能優(yōu)異的查詢語句。
當(dāng)然,“冗余一時爽,重構(gòu)火葬場”的段子也不是沒聽過,因為過多的冗余最終會造成數(shù)據(jù)的過于臃腫,性能降低等各種問題,這個要控制住開發(fā)者的冗余沖動,也依賴于團(tuán)隊技術(shù) Leader 對此的把關(guān)。
總結(jié)
互聯(lián)網(wǎng)業(yè)務(wù)不是一成不變的,產(chǎn)品和用戶的需求還有市場都一直在變!我們沒有技術(shù)實力打造一個能夠適應(yīng)靈活多變的業(yè)務(wù)的中臺,但是目前我們可以選擇一個可靠,強(qiáng)大并且靈活的數(shù)據(jù)庫 MongoDB!
作者:唐銀鵬
簡介:開源愛好者、Gopher。從事電商、IM 系統(tǒng)深度研發(fā),MongoDB 愛好者,公眾號《從菜鳥到大佬》作者。
編輯:陶家龍
出處:轉(zhuǎn)載自微信公眾號Mongoing 中文社區(qū)(ID:mongoing-mongoing),本文是唐銀鵬在“青芒話生長”MongoDB征文比賽的獲獎文章。