運維必看:日志標準化必須面對的 4 類問題
作者介紹:
朱林,日志及數據分析專家,《Elasticsearch技術解析與實戰》作者,對安全技術、數據分析有較深的研究,擁有15年數據分析及安全產品開發經驗。
引言
在很多安全分析類產品建設的過程中都會涉及到關聯分析,比如日志分析、soc、態勢感知、風控等產品。之前的文章中闡述過五種最常見的關聯分析模型,在文中也介紹了:要想達到很好的關聯分析效果,前提是對采集過來的日志進行標準化解析。解析的維度越多、內容越準確,對關聯分析的支撐性就越強。下面就來介紹一下日志解析的一些常用內容。
一、概述
很多公司在自己的產品介紹中描述產品有多少種日志解析規則等等,當然,這種內置的解析規則對這類產品發揮了很重要的作用。但這種方式也存在一些問題:
首先,經過時間的推移就會發現,每年市場上都會產生不少的新的安全設備和型號,導致廠家很難實現全部預制好的解析規則;
其次,很多設備會經常升級,升級后會導致日志種類的增加和調整;
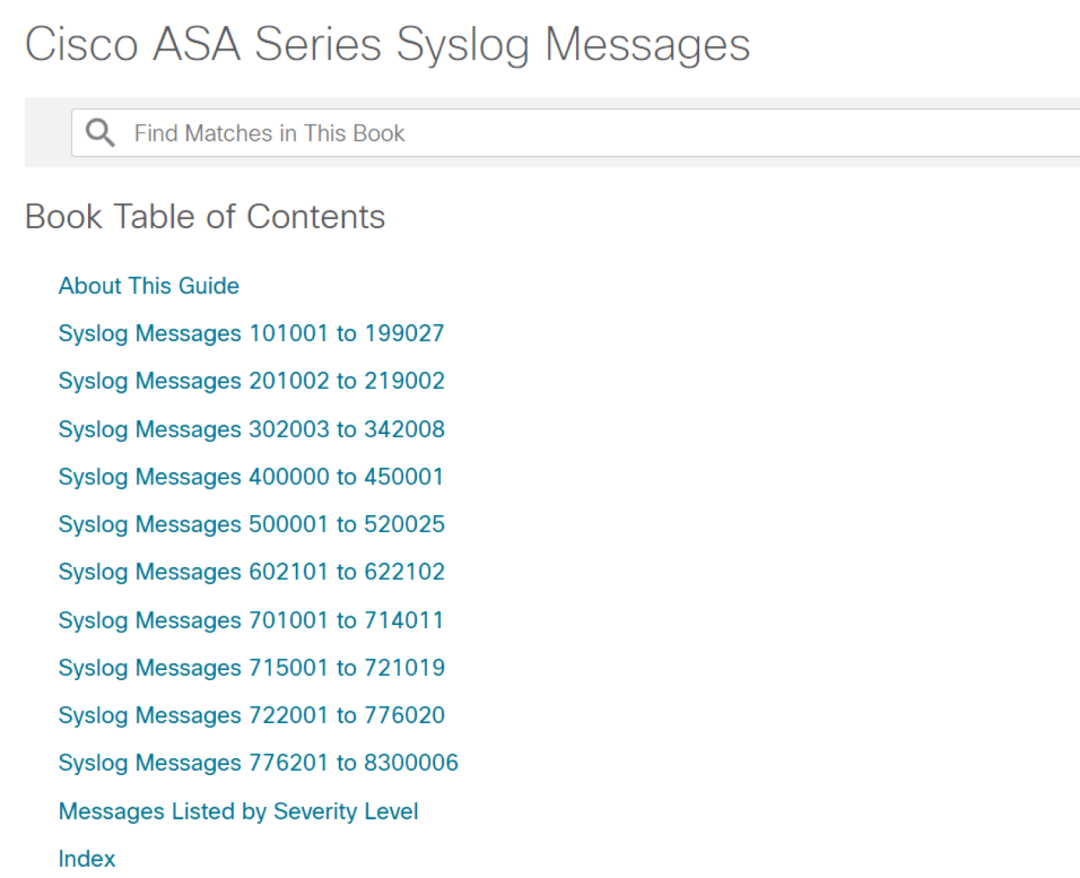
最后,很多設備的日志種類非常之多,如果全部內置到系統中,幾乎是不可能完成的任務。所以大多數的產品,只內置了部分的日志解析規則。比如思科ASA防火墻日志從官網看就有好幾百種日志格式,如果內置都解析,是很大的工作量,何況有時候也沒有必要全部解析。
根據以上分析可以得出,只在產品中內置默認的解析規則是不夠的,在很多時候需要根據客戶的實際環境進行調整。這種情況下,日志解析的靈活性、準確性、擴展性就顯得非常重要了。下面介紹一下日志解析中常用的內容:
二、日志解析關鍵點
標準化解析,也叫范式化解析,解析的目標是把日志中的直接信息和間接信息解析出來,作為單獨的字段進行存儲。對應數據庫中就是“列”的概念。傳統上來說,存儲大多用關系數據庫,比如:oracle、mysql。隨著大數據平臺的發展,最近幾年,存儲都是放在大數據平臺上的,比如:hive、,elasticsearch等。下面舉個linux下一條常用的登錄日志作為例子:
- May 22 17:13:01 10-9-83-151 sshd[17422]: Accepted password for secisland from 129.74.226.122 port 64485 ssh2
從這個日志中就可以看到很多的信息,比如直接信息包括:
- 登錄時間:May 22 17:13:01;
- 主機名:10-9-83-151;
- 進程名:sshd;
- 進程ID:17422;
- 事件類型:登錄(這個是根據內容分析出來的);
- 登錄用戶:secisland;
- 源ip:129.74.226.122;
- 端口:64485;
- 協議:ssh2。
間接信息主要包括:直接信息中體現不出來,但通過客戶環境的其他信息可以得到的信息,比如:
資產信息:通過設備IP地址可以得到設備的網絡域環境、所屬業務系統、部署的機房位置、設備管理人員等信息;
賬號信息:通過登錄賬號信息可以得到這個賬號授權給哪個人、賬號是否有效、賬號創建時間等信息。源ip相關信息:如果是公網,可以得到IP的地理信息,包括國家省市、IP的經緯度、從情報中可以得到這個IP是否是高危IP等;如果這個IP是內網,可以得到這個IP的部署位置、分配給哪個人、網絡域信息、業務信息等。
通過上面分析后,把每個字段存儲到數據庫中,這樣日志的信息就很豐富了,為后面的關聯分析、統計報表等打下了堅實的基礎。
解析的關鍵點如上所述,但在日志解析的實際操作階段有幾個不可回避的問題:
- 預解析和后解析;
- 自定義解析的靈活性;
- 自定義解析支持的靈活性;
- 自定義解析的效率。
2.1 預解析和后解析
預解析的主要含義是,在入庫之前把所有維度的信息預先解析出來,然后進行入庫;后解析的主要含義是反過來的,就是剛開始只入庫原始日志等基本信息,后面需要進行搜索、告警、報表等操作的時候再解析,把需要的維度放在內存中進行分析。
預解析的優勢是預先把維度存儲到數據庫中,使后面的操作更加便捷,劣勢是需要額外占用存儲空間,并且當預先解析內容不準確或者內容有變化的時候,無法進行下一步的分析(比如賬號信息發生了變化);后解析的優缺點正好和預解析相反。目前市場上絕大多數的產品都是預解析,純后解析的產品幾乎沒有。
比較理想的解析方式是預解析和后解析相結合,目前市場上只有少量產品支持這種特性。這種特性結合了兩者的優點,缺點又相對能接受,可以達到一個比較好的平衡。但這種方式為什么市場上用的少呢?據我分析,主要的原因是這種模式過于復雜。
首先是操作復雜,這種模式要求使用者掌握一些相關技能;其次是技術復雜,目前應用較廣的大數據平臺技術,對關聯查詢的支持不是特別理想,比如Elasticsearch目前對關聯查詢就非常繁瑣。但是這種預解析和后解析相結合的方式在應用上優勢明顯,是日志解析未來的發展趨勢。
其他問題可以通過特殊手段來解決,比如:可以把繁瑣的操作封裝在產品中,隱藏在操作的后臺;如果用關系數據庫,倒是容易解決后處理的問題,但是多數關系數據庫的處理能力和目前的大數據平臺還是有較大差距,可以在日志數量不大的時候使用。

2.2 自定義解析的靈活性
通過前面的分析得知,日志標準化解析在這類產品中的地位舉足輕重。如何把日志解析的能力提供出來,就顯得尤為重要,目前自定義解析的方式主要有幾種方式:
- 通過編碼實現。直接在代碼中處理,編譯發布,這種方式對廠家來說最靈活,但對使用者來說最麻煩,因為幾乎沒有辦法進行調整;
- 通過配置文件實現。比如logstash中配置input,filter,output等,這種方式解決了用戶不能直接調整的問題,非常方便。但這種情況只能登錄后臺查看配置文件,如果安裝的比較多,調整修改起來會稍顯繁瑣;
- 通過工具生成。比如之前版本的symantec的ssim平臺,通過他們提供的工具實現進行配置,繼而導出他們產品能識別的安裝包,最后安裝到平臺中。這種方式本質上是前面兩種解析方式的結合,比較靈活。唯一的缺點,是解析查看的時候需要借助工具,如果有修改或者添加的操作,需要重新部署一遍;
- 通過腳本實現。腳本實現其實可以歸于編碼實現的一個特例,只是大多數腳本不用編譯,可以直接運行。這種解析方式的優點是比較靈活,缺點是對使用者要求較高,同樣調整修改起來較為麻煩;
- 通過界面配置的方式實現。就是在平臺上直接進行配置,比如splunk、secilog等,這種方式的優點是比較靈活,從界面上配置非常方便。

根據上面的分析可以得知,通過界面配置的方式最優,其次是通過配置文件,最劣的是通過代碼實現。
2.3 自定義解析支持的靈活性
下面介紹自定義解析的具體關鍵點,主要包括存儲結構、語法支持、函數支持、多為支持、內置分析、字典支持、數據補全、上下文關聯、外接知識庫等內容。
- 存儲結構:
常用的解析語法主要包括XML、配置文件、數據庫存儲,這幾種存儲結構可以滿足大多數的場景需求,提供XML的存儲結構的大多是通過工具進行生成。
- 語法支持:
目前解析語法大多用的是grok或者類似grok語法的結構,大多都支持正則表達式、函數等方式,從大的方面都支持,要對比解析的優劣主要依靠細節。
- 函數支持:
字符串:
字符串提取,比如想在字符串123-445-789-012中提取445-789是否方便;
字符串拼接,比如兩個字段拼接成一個字段,add(sourceIp,eventId);
字符串替換,比如把字符串中的-替換成空格,replaceAll (“-”,””);
IF函數:
比如很多日志中可能是0表示成功,if(“0”,”success”,”fail”);
- 多維度支持:
比如日志源IP信息,在解析的時候需要添加到目標IP和日志源IP中;
- 內置分析:
比如http請求中的useragent,這里面含有大量的信息,是否能把里面的瀏覽器、操作系統、版本等分析出來;
- 字典支持:
在日志中有很多數據是有含義的,尤其是業務日志,但在日志保存的時候很多日志存儲的是編碼,這個時候需要通過字典把編碼對應的名稱添加進來;
- 數據補全:
在日志中有直接含義也有間接含義的數據,比如日志源IP,需要知道這個IP是哪個人在用,屬于哪個部門的;比如日志中有賬號信息,需要了解這個賬號的部門,姓名等信息;
- 上下文關聯:
有很多日志會存在不一致的地方,比如sftp登錄日志中有賬號信息,但操作日志中沒有賬號信息,這個時候需要在操作日志中把登錄的賬號補全進來,這樣才有利于進一步的分析;
- 外接知識庫庫支持:
很多公網IP通過IP知識庫是可以知道國家、省、市、地理信息的,這個在做分析的時候比較有用;如果是內網,可以通過配置國家、省、市、地理信息達到同樣的效果;
- 特殊邏輯處理
比如非上班時間處理的支持:國內有法定假,法定假可能存在調休等,而且每年的法定假都不一樣,所以還要等到年底國家才能頒布下一年的法定休假的方案;很多客戶也有會調班的情況,這種情況的工作日和非工作日就比較特殊。在很多告警規則中都有非上班時間的訴求,比如非上班時間登錄服務器,非上班時間進行了敏感文件操作等,這個時候對非上班能力的支持就很重要。
2.4 自定義解析的效率
日志解析使用不同的技術對效率的影響是不一樣的,目前主流的幾種方式主要有模板方式、正則表達式方式等。這幾種方式的效率有比較大的區別,模板方式的靈活性比正則表達式方式稍微低一些,但從效率上來看,模板方式比正則表達方式高很多。比較理想的方式是大部分解析用模板的方式去實現,少量復雜的解析用正則表達式的方式去實現。這樣就達到了靈活性和效率之間的平衡。
上面列出了日志解析的常用關鍵內容,這些內容支持的靈活性越高越好。在實施SOC、態勢感知等產品的時候,經常會花費大量的時間在解析上面,如果能靈活支持,可以大幅度提高效率和效果。
三、小結
前面介紹的是目前日志標準化解析的一些關鍵內容,可以作為安全分析產品中日志解析靈活性評判的一個參考。提高日志解析的準確性、靈活性也是一個非常復雜的過程,這部分的處理對后續的關聯分析等起到非常重要的作用。日志解析存儲后,如何在海量數據中進行搜索,也是個非常重要的問題。
存儲只是解決了“有”的問題,但如何更高效便捷地從中找到想要的數據,支持什么樣的接口可以讓客戶快速準確地找到想要的內容也是非常重要的,后面有時間再詳細介紹這方面的內容。日志解析本身是一個比較復雜的話題,我盡量保證內容觀點正確,但本人才學疏淺,文中若有不足之處歡迎大家批評指正。