













打破二八法則!每個數據科學家都得會一點SparkMagic
著名的帕累托法則,即80/20定律,告訴我們:原因和結果、投入和產出、努力和報酬之間存在著無法解釋的不平衡。即使是21世紀最具吸引力的工作,數據科學依然逃不脫這一定律。
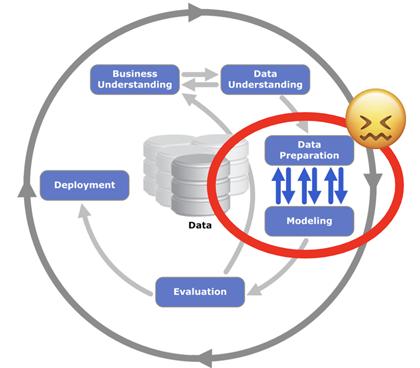
商業數據科學家80%的時間都花在查找、清洗和準備數據上,這是數據科學家工作中效率最低也是最可怕的部分。互聯網為如何打破數據科學的80/20定律提供了許多的意見,但卻收效甚微。
其實,數據科學家生產率低下的主要原因在于數據準備工作的雙重性:
- 快速訪問、合并和聚合存儲在企業數據湖中的大數據
- 探索和可視化數據中具有復雜依賴關系的Python數據包中的數據和統計信息
大數據大多是非結構化的,常常存儲在具有企業管理和安全限制的生產環境中。快速訪問數據需要昂貴的分布式系統,這些系統由IT集中管理,必須與其他數據科學家和分析師共享。
Spark是用于分布式數據湖中處理數據的行業黃金標準。但是,要以經濟高效的方式使用Spark集群,甚至允許多租戶,就很難滿足單個需求和依賴關系。分布式數據基礎架構的行業趨勢是臨時集群,這使得數據科學家更加難以部署和管理他們的Jupyter Notebook環境。
圖源:CC BY-SA 3.0
很多數據科學家都在高規格筆記本電腦上進行本地工作,可以更加輕松地安裝和持久保存Jupyter Notebook環境。那么這些數據科學家們如何將其本地開發環境與生產數據湖中的數據聯系起來?通常,他們使用Spark實現了csv文件,并從云存儲控制臺下載了它們。
從云存儲控制臺手動下載csv文件既不高效,也沒有特別強大的功能。如果能以終端用戶友好且透明的方式無縫地將本地的Jupyter Notebook與遠程集群連接起來,豈不是更好嗎?
學好SparkMagic,打破數據科學二八法則的時間到了!
適用于Jupyter NoteBook的SparkMagic
Sparkmagic是一個通過Livy REST API與Jupyter Notebook中的遠程Spark群集進行交互工作的項目。它提供了一組Jupyter Notebook單元魔術和內核,可將Jupyter變成用于遠程集群的集成Spark環境。

合理使用和公共領域圖標和svg | 圖源:MIT
SparkMagic能夠:
- 以多種語言運行Spark代碼
- 提供可視化的SQL查詢
- 輕松訪問Spark應用程序日志和信息
- 針對任何遠程Spark集群自動創建帶有SparkContext和HiveContext的SparkSession
- 將Spark查詢的輸出捕獲為本地Pandas數據框架,以輕松與其他Python庫進行交互(例如matplotlib)
- 發送本地文件或Pandas數據幀到遠程集群(例如,將經過預訓練的本地ML模型直接發送到Spark集群)
可以使用以下Dockerfile來構建具有SparkMagic支持的Jupyter Notebook:
- FROM jupyter/all-spark-notebook:7a0c7325e470USER$NB_USER
- RUN pip install --upgrade pip
- RUN pip install --upgrade --ignore-installed setuptools
- RUN pip install pandas --upgrade
- RUN pip install sparkmagic
- RUN mkdir /home/$NB_USER/.sparkmagic
- RUN wget https://raw.githubusercontent.com/jupyter-incubator/sparkmagic/master/sparkmagic/example_config.json
- RUN mv example_config.json /home/$NB_USER/.sparkmagic/config.json
- RUN sed -i 's/localhost:8998/host.docker.internal:9999/g'/home/$NB_USER/.sparkmagic/config.json
- RUN jupyter nbextension enable --py --sys-prefix widgetsnbextension
- RUN jupyter-kernelspec install --user --name SparkMagic $(pip show sparkmagic |grep Location | cut -d" " -f2)/sparkmagic/kernels/sparkkernel
- RUN jupyter-kernelspec install --user --name PySparkMagic $(pip show sparkmagic| grep Location | cut -d" " -f2)/sparkmagic/kernels/pysparkkernel
- RUN jupyter serverextension enable --py sparkmagic
- USER root
- RUN chown $NB_USER /home/$NB_USER/.sparkmagic/config.json
- CMD ["start-notebook.sh","--NotebookApp.iopub_data_rate_limit=1000000000"]
- USER $NB_USER
生成圖像并用以下代碼標記:
- docker build -t sparkmagic
并在Spark Magic支持下啟動本地Jupyter容器,以安裝當前工作目錄:
- docker run -ti --name\"${PWD##*/}-pyspark\" -p 8888:8888 --rm -m 4GB --mounttype=bind,source=\"${PWD}\",target=/home/jovyan/work sparkmagic
為了能夠連接到遠程Spark集群上的Livy REST API,必須在本地計算機上使用ssh端口轉發。獲取你的遠程集群的IP地址并運行:
- ssh -L 0.0.0.0:9999:localhost:8998REMOTE_CLUSTER_IP
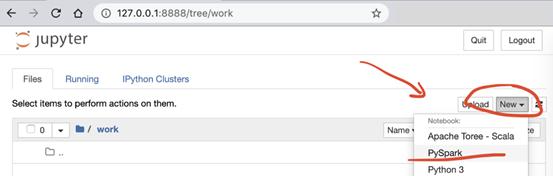
首先,使用啟用了SparkMagic的PySpark內核創建一個新的Notebook,如下所示:
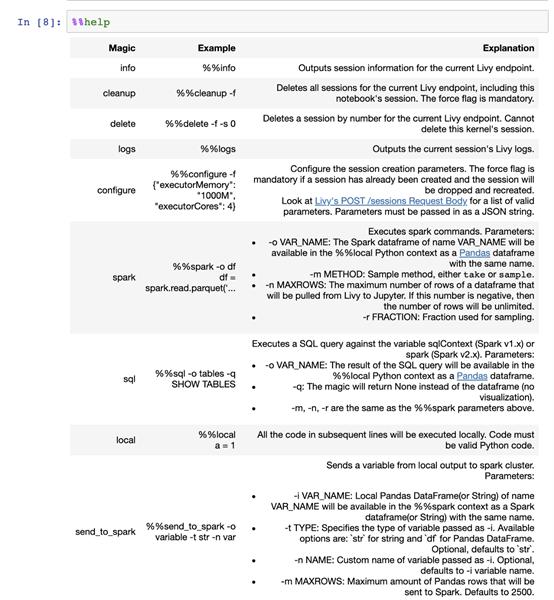
在啟用了SparkMagic的Notebook中,你可以使用一系列單元魔術來在本地筆記本電腦以及作為集成環境的遠程Spark集群中使用。%% help魔術輸出所有可用的魔術命令:
可以使用%%configuremagic配置遠程Spark應用程序:
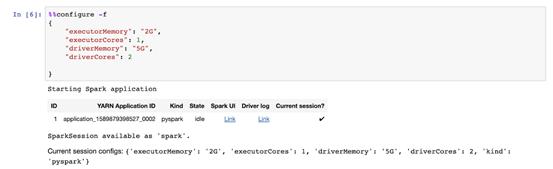
如圖所示,SparkMagic自動啟動了一個遠程PySpark會話,并提供了一些有用的鏈接以連接到Spark UI和日志。
Notebook集成了2種環境:
- %%local,可在筆記本電腦和jupyter docker映像提供的anaconda環境中本地執行單元
- %%spark,通過遠程Spark集群上的PySpark REPL,再通過Livy REST API遠程執行單元
首先將以下code cell遠程導入SparkSql數據類型;其次,它使用遠程SparkSession將Enigma-JHU Covid-19數據集加載到我們的遠程Spark集群中。可以在Notebook中看到remote .show()命令的輸出:
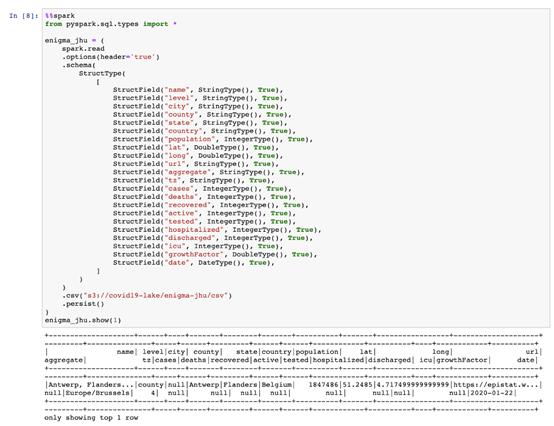
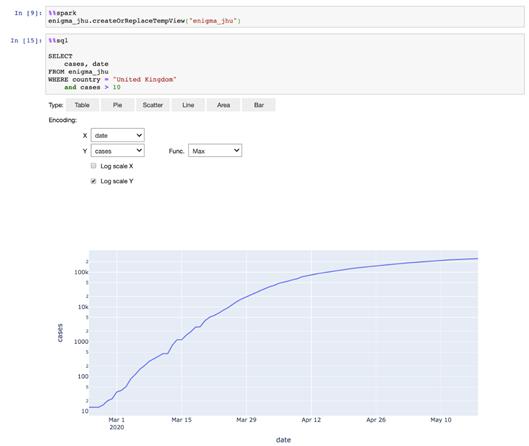
但這就是魔術開始的地方。可以將數據框注冊為Hive表,并使用%%sql魔術對遠程群集上的數據執行Hive查詢,并在本地Notebook中自動顯示結果。這不是什么高難度的事,但對于數據分析人員和數據科學項目早期的快速數據探索而言,這非常方便。
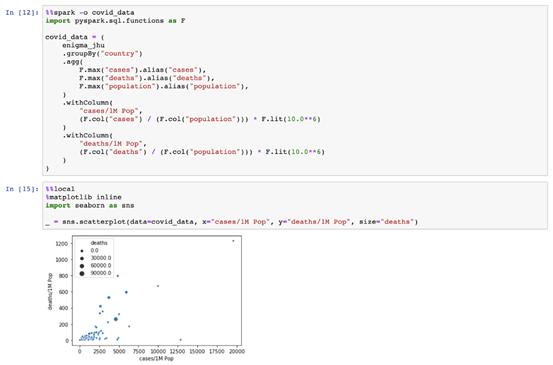
SparkMagic真正有用之處在于實現本地Notebook和遠程群集之間無縫傳遞數據。數據科學家的日常挑戰是在與臨時集群合作以與其公司的數據湖進行交互的同時,創建并保持其Python環境。
在下例中,我們可以看到如何將seaborn導入為本地庫,并使用它來繪制covid_data pandas數據框。
這些數據從何而來?它是由遠程Spark集群創建并發送的。神奇的%%spark-o允許我們定義一個遠程變量,以在單元執行時轉移到本地筆記本上下文。我們的變量covid_data是一個遠程集群上的SparkSQL Data Frame,和一個本地JupyterNotebook中的PandasDataFrame。
使用Pandas在Jupyter Notebook中聚合遠程集群中的大數據以在本地工作的能力對于數據探索非常有幫助。例如,使用Spark將直方圖的數據預匯總為bins,以使用預匯總的計數和簡單的條形圖在Jupyter中繪制直方圖。
另一個有用的功能是能夠使用魔術%%spark-o covid_data -m sample -r 0.5來采樣遠程Spark DataFrame。集成環境還允許你使用神奇的%%send_to_spark將本地數據發送到遠程Spark集群。
圖源:pexels
PandasDataFrames和字符串支持的兩種數據類型。要將其他更多或更復雜的東西(例如,經過訓練的scikit模型用于評分)發送到遠程Spark集群,可以使用序列化創建用于傳輸的字符串表示形式:
- import pickle
- import gzip
- import base64serialised_model = base64.b64encode(
- gzip.compress(
- pickle.dumps(trained_scikit_model)
- )
- ).decode()
但正如你所見,這種短暫的PySpark集群模式有一大詬病:使用Python軟件包引導EMR集群,且這個問題不會隨著部署生產工作負載而消失。
快將自己的生產力從數據準備的低效率中拯救出來吧,用80%中節省出來的時間去創造更多價值。
















