推薦算法集錦(中)—— SVD和CB
原創【51CTO.com原創稿件】
1.導讀
通過上一篇對推薦系統的協同過濾算法進行詳細的介紹后,并且給出模擬推薦案例,相信廣大讀者對于協同過濾算法的原理也有了一個基本的了解,以及對其中的推薦過程和使用該推薦算法的場景和優勢有了一個基本的掌握。在上一篇文章的結尾部分我留了幾個思考,也就是關于協同過濾算法劣勢的研究,用來引出其他的推薦算法。因此在這篇文章中,我會從這些方面出發,實際地去解決這幾點疑慮,并且透徹地去闡述協同過濾算法的劣勢,然后給出相應的解決方案和對應的推薦算法。
2.“巧婦乃為無米之炊”——矩陣稀疏問題
2.1 “米”不夠?
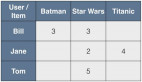
首先對于協同過濾推薦算法,推薦計算過程中涉及到一個關鍵性也是基礎性的參數就是評分矩陣,這就引出了今天我們需要解決的第一個問題:評分矩陣的疏密程度。評分矩陣的疏密程度是選擇對應推薦算法或者處理方法的關鍵。在實際的應用過程中,由于很多用戶在生活中只會對少部分商品進行瀏覽、購買或者評價,對于大部分的商品都會視而不見、置之不理,因此這樣就會導致最終形成的評分矩陣過于稀疏。在設計推薦系統的時候,就會面臨一個挑戰:使用相對較少或者根本不夠的有效評分數據來完成一個相對比較準確的預測。這樣的問題無疑是“巧婦難為無米之炊”,至于選取任何一個推薦算法所帶來的結果并不會有太大區別。就好比你要煮飯,你的米不夠甚至沒有米,即使你用鐵鍋還是銅鍋甚至金鍋也做不出來滿足一家人吃的飯。這里的“米”也就是用戶對于物品的評分,而“鍋”,則就好比推薦系統,鍋的材質也就好比推薦算法。這樣,讀者就能明白其中的含義了,并能夠意識到評分的重要性。
面對這種評分矩陣過于稀疏的問題,最直接的辦法就是利用用戶或者物品的額外屬性數據,對這些數據進行分類和整合操作,來求解相對應的相似用戶或者物品列表。這種方法如果這樣描述,廣大讀者可能并不是能夠很好地理解其中含義,并不會對這種方法產生深刻的印象。因此,我還是用煮飯的例子來解釋下,用戶—物品的評分矩陣過于稀疏時(在這先不考慮評分矩陣為空的情況),也就是煮飯的米不夠,那么采用的方法就是想辦法把米進行分解,也就是把米弄碎,從而得到更多的碎米,利用這些碎米去煮粥就可以滿足一家人的需求了。這種比喻也就是上面說的利用用戶和物品的額外特征屬性數據來進行分類和整合。
2.2 沒有“米”?
當然還存在一種情況就是沒有米的時候,也就是用戶沒有任何評分或者說是新來的用戶,這里不知道讀者有沒有似曾相識的感覺。沒錯,這種情況也就是冷啟動情況,在推薦系統詳解里已經有了相對應的解決辦法,也就是完成一個非個性化推薦。大部分都是使用熱銷物品或者榜單數據來完成推送,或者在首頁彈出窗口來詢問用戶的喜好和興趣,根據用戶點擊的模塊來完成推薦。具體的操作方法詳見我的文稿(推薦系統詳解——個性化推薦與非個性化推薦),在這里就不贅述了。
2.3 基于近鄰算法的短板揭露
回到之前說的利用用戶和物品的額外特征屬性對數據進行分類整合,這種操作相對應的一種算法叫做SVD矩陣因子分解。后面我會講到;除此之外,還可以通過缺省投票的形式來補全物品的評分,原理就是給那些只有一個或者兩個的用戶評價的物品一個缺省值,這種方法類似于隱式評分計算;最后還有一個辦法,當然也是無奈之舉。那就是在沒有評分的用戶和物品旁邊或者近鄰找到有評分的用戶和物品,以它的評分來填充當前的評分,或者用遞增、求均值之類的方法獲取到評分來完成當前用戶和物品評分。因此,現在可以得出CF——基于近鄰推薦算法的全部劣勢或者說是短板了,如下所示:
(1)覆蓋有限:由于計算兩個用戶之間的相似度是基于這些用戶對于相同一類物品的評分的,并且只有對這一類物品進行評分的用戶才可以作為近鄰,也叫對等用戶。但是由于在實際場景中,很多用戶很少對物品進行評分或者沒有評分,但是他們的確又有相同的興趣愛好,這樣就會導致推薦算法的覆蓋范圍受到限制和影響。為解決這一問題,引出了SVD矩陣因子分解推薦算法,它是根據已有用戶對物品的評分情況,分析出評分的用戶對各個物品的因子喜好程度,以及各個物品對于這些因子的包含程度,最后再反過來根據最終的分析結果預測評分。舉個例子來說,在沒有進行SVD矩陣因子分解前,只用戶A和用戶B以及用戶C都喜歡看電影,而且看電影的頻次也相差不大。但是就看了幾部電影,這樣就導致可能就兩三部電影具有用戶們的評分值,這樣的評分數量對于評分矩陣來說無疑是不夠的,也就會造成評分矩陣的稀疏了。但是通過SVD矩陣因子分解后,發現每個電影可以提取到額外的特征屬性因子(有勵志、搞笑、人文、愛情等屬性因素),這樣就可以提取到更多屬性的評分值。通過這種屬性也就會發現用戶A可能跟用戶B喜好相同,可能都喜歡看搞笑或者愛情類的電影,而用戶C可能更喜歡看恐怖或者勵志類的電影。這樣就可以根據用戶B的行為來預測A的行為了。使推薦給A的電影更符合A的口味。因此,通過SVD矩陣因子的方式就可以找出更多影響評分的因子,并且將更多有意義的關聯信息挖掘出來,推薦出符合用戶需求和意愿的物品。
(2)對稀疏數據的敏感:其實這個問題和上面覆蓋有限的問題有些類似。因為評分矩陣的稀疏性是大多數推薦系統的共同問題。主要是看評分舉證的稀疏程度,在上面講的SVD矩陣因子分解算法使用中,如果分解后的物品屬性因子還是不夠稠密,形成的因子評分矩陣依舊稀疏,但是又不是新用戶,還有有一定的歷史購買行為或者瀏覽行為。類似這樣的用戶就不至于采取非個性化推薦了,因為畢竟要考慮到推薦的人性化、智能化,榜單熱銷物品數據不是萬能的,有一定歷史行為的用戶還是要考慮其中的歷史行為因素,爭取做到個性化推薦。目前為了解決這一類問題,可采取基于內容的推薦算法。基于內容的推薦算法是直接根據用戶的歷史偏好來推薦與用戶歷史偏好相關的物品,這樣就兼顧了每個用戶所特有的屬性,完成個性化推薦。
針對上面兩個問題引出來了兩個算法分別是SVD矩陣因子分解算法和基于內容的推薦算法,這兩個算法就是這篇文章的重點。有了這個“引子”,下面就開始燃起這兩個算法的“導火線”了。
3.SVD矩陣因子分解算法
3.1 SVD算法
首先來看下SVD(Singular Value Decomposition)的數學定義:將給定的評分矩陣S分解成為三個矩陣的乘積,其中U和V稱為左、右奇異向量,在本章中可理解為用戶矩陣和物品因子矩陣,對角線上的值稱為奇異值;S為n*m的矩陣,U為n*n矩陣,Q為n*m的矩陣,V為m*m的矩陣;在下面公式中,可以使用k個奇異值來近似地替代R矩陣,因為前1%的奇異值的和就占了全部奇異值和的99%以上,因為除了中間的奇異值之外,其余的奇異值基本都是0。公式如下:

然后需要將U、V矩陣進行轉換得到用戶因子矩陣C和物品因子矩陣P,將奇異矩陣Q開平方分別乘到U和V矩陣,如同將奇異矩陣Q做了一個開方然后乘積的變換。得到用戶因子矩陣C和物品因子矩陣P如下:

最后用戶t對物品i的評分預測就為用戶因子矩陣的第t行乘上物品因子矩陣的第i列(即物品因子矩陣的第i行的轉置),如下所示:
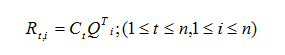
3.2 參數優化
在進行用戶因子矩陣C和物品因子矩陣P的計算時,可以通過SGD隨機梯度下降的方式進行學習來不斷迭代調整更新相關參數。對于沒有評分的情況則不需要計算誤差值,直接令誤差值為0即可。上面提到的SGD隨機梯度下降的方法由于涉及的內容較多,不容易理解,并且怕讀者將SGD隨機梯度下降和SVD矩陣因子分解相互混淆,在這就不再繼續對SDG隨機梯度下降進行原理上的闡述了。我會將SGD隨機梯度下降方法令作一個專題去分析闡述,因為它也涉及到一些人工智能的神經網絡的運用。希望廣大讀者在這就先熟悉適應下公式即可:

3.3 SVD算法缺陷
SVD矩陣因子分解在實際推薦系統中很少使用,因為它很難進行在線計算,以至于不能很好地處理用戶的實時行為反饋,也就沒有實時處理能力。而且對于大型的推薦系統而言,直接進行協同過濾或者SVD矩陣因子分解的話,可能會存在計算的復雜度過高的問題,這個時候就可以考慮K-means聚類算法做處理,將大量的評分數據進行分組,將每一組的所有數據歸為一類或一個因子,然后再進行協同過濾處理,對于K-means算法原理和作用在這就不作贅述。之后這些漏掉的算法原理會以補充篇來專門講述。
4.CB—基于內容的推薦算法
4.1 CB算法及其特點、應用
基于內容的推薦算法(Content-based Recommendations)相比較于協同過濾算法,也是一種工業界或者互聯網業界應用比較廣泛的推薦算法了。這是針對于協同過濾推薦算法中,僅僅基于用戶對商品評分推薦導致的評分矩陣過于稀疏(以至于矩陣因子分解后依舊達不到理想的豐富評分矩陣要求)所提出的推薦算法。這種推薦算法在某種程度上也解決了一部分冷啟動問題(雖然不是進行新用戶推薦)。基于內容的推薦算法可以根據物品的特性或者用戶的歷史行為或者特殊偏好等特征屬性來進行比較直觀的推薦。這種算法僅僅只考慮推薦的用戶,而不去在意其他用戶群以及最近鄰。
CB算法特點:CB—基于內容的推薦算法雖然也需要依賴物品和用戶偏好的額外信息,但是它并不需要太多的用戶評分和對等用戶群的偏好屬性記錄,換句話說,也就是只有一個用戶時,使用基于內容的推薦算法也可以完成推薦功能,并且產生一個物品的推薦列表。而這些是基于協同過濾算法的推薦所辦不到的。
CB算法應用:基于內容的推薦算法起初設計出來時為了推薦用戶感興趣或者有意思的文本文檔,在一些文本文檔推薦中經常可以看到基于內容的推薦算法的“身影”。但是在目前也會開始將該算法應用在其他推薦領域了。基于內容完成推薦在未來也會得到進一步的推廣與應用。
4.2 CB算法 VS 協同過濾算法
下面我們來看下CB(基于內容)和(協同過濾)兩個算法的區別:
CB(基于內容的推薦算法)的推薦系統會根據用戶過去喜歡物品,試圖推薦給用戶過去喜歡的物品的相似替代品,所推薦的物品是跟用戶過去感興趣或者購買過的物品是屬于同一類的,并且CB算法不需要依賴用戶—物品評分矩陣;
CF(協同過濾的推薦算法)的推薦系統則會試圖識別出與當前用戶具有相同興趣愛好的其他用戶,來將這些其他用戶所喜歡過的物品推薦給當前用戶。CF算法則是需要基于用戶—物品評分矩陣來完成推薦的。
4.3 CB算法實現步驟與結構
CB算法實現步驟如下:
(1)Item Representation(對象表示):就是為每一個item(對象)抽取出一些特征屬性出來,也就是結構化物品的操作,相對應的處理過程也叫內容分析;
(2)Profile Learning(特征學習):利用當前用戶的歷史行為信息或者過去喜歡(不喜歡)的item的特征數據信息,來學習當前用戶的喜好特征(Profile),相對應的處理過程叫做Profile Learning;
(3)Recommendation Generation(推薦迭代):通過分析上一步得到的用戶Profile(特征),為該當前用戶推薦一組相關性或者相似度最大的item即可,相對應的處理過程叫做Filtering Component(過濾組件)。
由BC推薦算法的實行步驟不難得出BC推薦算法運行的結構,將BC推薦原理過程繪制成直觀的結構圖如下所示:

4.4 CB—Item Representation
在繪制完BC推薦算法的結構圖后,在這額外補充一點:在對物品特征屬性的挖掘抽取中,也就是Item Representation過程中,主要包括對數值型數據的處理和非數值型數據的處理,這在機器學習中采用的主要處理方式有以下幾種:
(1)數值型數據歸一化:就是將數值型數據統一除以自己數據總和,用每一個數據在數據總和中的占比來表示該數據,使得每個數據的表示范圍都在[0,1]之間,這也是最為簡單的數值型數據歸一化方法;
(2)數值型數據二值化:依據各個數據值來設置一個默認值,設定一個條件規則如數
據值大于等于默認值,則表示為1,小于默認值表示為-1。像這樣的設定限定條件來使每一個數據值都只有兩種值中的一種,也就是所謂的二值化;
(3)非數值型數據轉換成特征向量:將每一個非數值型數據用對應的向量型數值表示;
(4)TF-IDF:一種用于信息檢索與數據挖掘的常用加權技術。TF是詞頻,IDF是逆文本頻率指數,通常用來評估一個字詞對于一個文件集中的一份文件的重要程度。
(5)Word2Vec:一群用來產生詞向量的相關模型,會涉及到神經網絡的訓練。
4.5 CB—Pofile Learning
假設用戶對于某些物品已經有了喜好判斷,喜歡其中一部分的物品,不喜歡另外一部分,那么這個過程其實就是通過用戶過去的喜好來進行判斷,從而構建一個判別模型,最后再根據這個模型來判斷用戶對于一個新的物品是否喜歡。這是一個比較典型的有監督學習問題,在理論上也是可以使用機器學習的分類算法來求解所需要的的判別模型,這也為今后算法的優化提供了研究方向,也就是結合深度學習技術來不斷完善判別模型,使得判別模型更加地貼合用戶興趣。
在這一過程中涉及到的常用算法有最近鄰方法、決策樹方法、線性分類算法、樸素貝葉斯算法等,這些算法都是在人工智能領域或者說是深度學習領域常用的處理數據的算法,由于本文只講推薦算法,涉及到的這些深度學習領域的算法我會在今后介紹深度學習的專題里進行闡述。至于最近鄰方法由于是推薦系統最關鍵、也最常用的算法,我會以補充稿的形式來詳細闡述并更好地進行該推薦算法系列的差缺補漏。通過這些涉及到機器學習的知識不難發現,基于內容推薦其實主要就依賴機器學習算法的基礎上來做的一個推薦。
4.6 CB算法大剖析
通過上述文字,不難知道基于內容的推薦算法(CB)的優缺點,下面我們就展開了解下,
對于CB推薦算法的優點主要有以下幾個:
(1)用戶獨立性:這個性質也脫離了協同過濾算法依賴其他近鄰的特征屬性的限制,真正意義上做到僅有一個用戶也能完成個性化推薦。在構建模型的過程中,CB算法只需要考慮當前推薦用戶的信息就可以了,非常獨立的一種推薦算法;
(2)透明度:通過CB算法的運行結構就可以知道,CB算法通過顯式地列出使得物品出現在推薦列表中的內容特征和描述信息,也就可以很好的、較為明確或者透明地解釋推薦系統是如何工作的了;
(3)新物品性:這個是針對于物品評分沒有的情況下的特性。也就是說,即使當前用戶對這個物品并沒有評分,甚至這個物品沒有任何評分,但是BC算法可以基于當前用戶歷史行為找到與該物品想類似且有用戶評分的物品,那么CB推薦算法就可以將這個沒有任何評分的物品推薦給當前用戶,也就是完成了新物品(沒有任何評分的物品)的推薦。
當然,任何推薦算法都是只能用來解決某一類問題或者處理某一類情況的,因此,CB算法也有它自身難以克服的缺點:
(1)抽取特征難度大(可分析的內容有限):對于當前用戶(物品),如果他的瀏覽歷史(特征屬性)不夠豐富,那么就會導致提取的特征不具備很好的表示能力,對于最終的推薦效果產生負面的影響。這個問題是與推薦對象相關的特征數量和類型有限相關的,并且依賴于領域知識,也就是機器學習算法的好壞;
(2)容易造成長尾效應:長尾效應在之前的文章中已經做過解釋,CB算法推薦很可能會導致長尾效應的出現,以至于無法發現用戶的潛在興趣,造成用戶的興趣過度專一特化。因為CB推薦算法中的推薦結果一直都是和用戶以前喜歡的物品類似的,經過CB算法推薦,用戶始終停留在以前那一塊興趣領域中,無法跨越出來,喜歡上其他領域的物品。但是真實情況是當前用戶肯定不止這一塊領域的興趣愛好,因而CB推薦算法就無法發現該當前用戶可能還喜歡其他領域內容,也就會造成用戶興趣過度專一特化,長尾效應也就出現了;
(3)冷啟動問題:也就是無法為新注冊的用戶產生推薦,因為CB算法依賴的是當前用戶的歷史行為數據,對于一個完全沒有歷史行為數據的新注冊用戶也就不可能為他產生一個比較可靠的推薦結果了。這個問題也是之前協同過濾算法存在的問題,好在已將在之前的文
章中用非個性化推薦解決了這個問題,就不再繼續描述了。
5.總結
SVD算法和CB算法都是作為解決協同過濾算法的用戶—評分矩陣過于稀疏所研究出來的推薦算法,雖然針對于不同的稀疏度有相對于的解決辦法。但是作為SVD和CB算法本事,這兩個推薦算法仍有其自身難以克服的缺點存在。在下一篇文章中,我會把剩下的、相對比較小眾的推薦算法介紹給大家,這樣就可以讓讀者根據自身開發遇到的場景選用合適的算法了,也可以讓讀者較為清晰的了解到推薦算法的輕重級別,對于一些小眾的推薦算法的掌握是可以為自身設計的推薦系統起到錦上添花的效果。
【51CTO原創稿件,合作站點轉載請注明原文作者和出處為51CTO.com】