用deepfake拍電影可以安排了:迪士尼發布高分辨率換臉算法
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
換臉這件事,從未如此高清。

最流行的開源deepfake模型DeepFakeLab,在今年的更新中,最大分辨率也只達到了320×320。
而這只來自迪士尼和ETHZ的全新deepfake,在保持高度流暢這一優良傳統的同時,還一舉把分辨率拉高到了1024×1024的水平。
這也是deepfake的分辨率水平首次達到百萬像素。
這下,換臉之后,每一根眉毛都仍然清晰可見。

動圖畫質略有損失,用靜態圖來感受一下這個清晰度:

難怪網友忍不住驚呼:鵝妹子嚶。
為特效而生的高分辨率deepfake
在此之前,deepfake技術的改進重點主要在平滑換臉效果,而不是提高分辨率。
但320×320這樣的分辨率下,手機上看換臉效果可能行云流水看不出破綻,換到大屏幕上,缺陷就會很明顯。

為了提高分辨率,迪士尼的這項研究主要引入了逐步訓練的多向梳狀網絡,并提出了一個完整的人臉交換管道,包括保留光線和對比度的混合方法,以減少視頻常出現不真實的抖動,生成時間上穩定的視頻序列。
具體而言,分為以下幾個步驟:
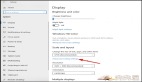
- 首先,對輸入人臉進行裁剪和歸一化預處理,將人臉歸一化為1024×1024分辨率,并保存歸一化參數。
- 而后,預處理過的圖像會被輸入到通用編碼器中,用相應的解碼器Ds進行解碼。
- 最后,用多頻段混合方法來交換目標人臉和源人臉。
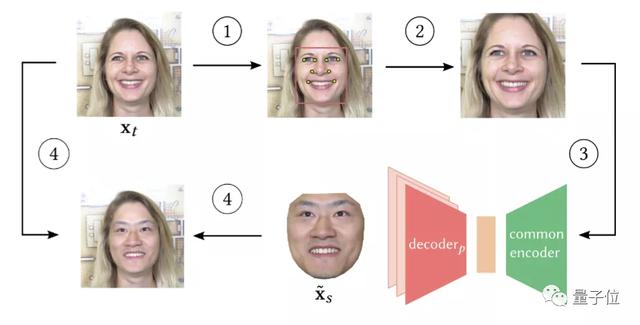
漸進式訓練的多向梳狀網絡
在網絡架構上,迪士尼采用了單個編碼器、多個解碼器的方案,稱作“梳子模型”。
即,網絡的編碼部分是共享的,而解碼路徑則分成P個域。
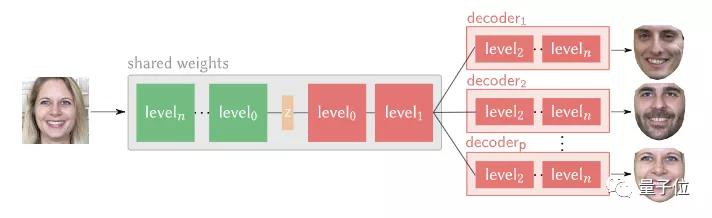
這樣一來,一個模型就能同時處理多個源-目標對。
并且,實驗表明,與雙向模型相比,多向訓練模型可以提高表達的保真度。
由于多向編碼器允許生成不同的輸出,這些輸出既可以對應不同的身份,也可以對應不同照明條件下的同一張臉。
此外,還有一重優勢是,相比于雙向網絡,使用單一網絡的訓練時間能明顯減少。
網絡的訓練,則采取漸進式機制。
首先,對高分辨率輸入數據進行下采樣,形成粗糙的低分辨率圖像,先用這些低分辨率圖像進行訓練。此后,逐步在訓練中加入高分辨率圖像,逐漸擴大網絡的容量。
消除時間偽影
為了消除可見的時間偽影,研究人員還提出了一種穩定標志物定位算法的方法。
具體而言,是對人臉進行初始檢測和對其,并標記人臉邊界框的寬度w 。
然后,通過在圖像平面的不同方向上擾動βw個像素,來重新初始化原始邊界框n次。
研究人員發現,在1024×1024分辨率下,β=0.05和n=9時,可以消除所有可見的時間偽影。
保留光線和對比度的混合方法
不過,即使人臉已經完全對齊,姿勢和面部表情也完全匹配,光度失準等問題,依然會造成換臉效果的不和諧。
比如出現明顯的接縫。

針對這個問題,研究人員采用了保留光線和對比度的多頻段混合方法,并強制要求邊界平滑效果只傳播人臉內部,確保外側的人臉輪廓不會被平滑掉。
與常用的泊松混合(Poisson blending)方法相比,在目標人臉圖像和源人臉圖像光照不同的情況下,該方法消除偽影的效果更好。

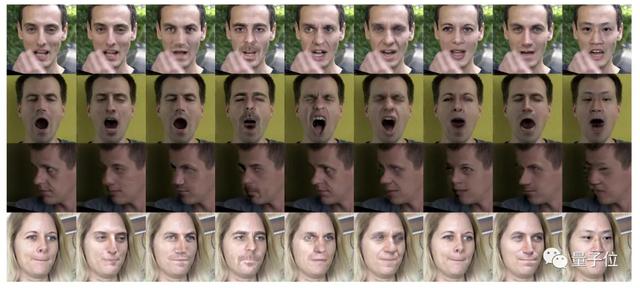
所以,這個高清deepfake的效果應該如何評價?
直接看對比:

deepfake登上大熒幕,指日可待
不過,研究人員也指出,這個高清deepfake仍有局限性。
從展示的示例中可以看出,大部分人臉圖像都是正對鏡頭的。
夸張的表情、極端的角度和光線,仍然會導致模糊和偽影。
但分辨率的提升,依然給deepfake帶來了全新的商業可能性。
迪士尼就曾經在《星球大戰》系列電影《俠盜一號》里,用特效換臉技術讓已故演員Peter Cushing和Carrie Fisher重返熒幕。
不過,采用傳統特效技術,通常要花費數月時間,才能獲得幾秒鐘的畫面,成本十分高昂。
相比之下,構建原始模型之后,deepfake在數小時之內就能完成換臉視頻的制作。
看來,deepfake技術登上大屏幕,或許離實現不遠了。
傳送門
論文地址:
http://studios.disneyresearch.com/2020/06/29/high-resolution-neural-face-swapping-for-visual-effects/