智能標注原理揭秘 一文讀懂人工智能如何解決標注難題
無論是在傳統機器學習領域還是現今炙手可熱的深度學習領域,基于訓練樣本有明確標簽或結果的監督學習仍然是一種主要的模型訓練方式。尤其是深度學習領域,需要更多數據以提升模型效果。目前,已經有一些規模較大的公開數據集,如ImageNet,COCO等。對于深度學習入門者,這些公開數據集可以提供非常大的幫助;但是對于大部分企業開發者,特別在醫學成像、自動駕駛、工業質檢等領域中,他們更需要利用專業領域的實際業務數據定制AI模型應用,以保證其能夠更好地應用在業務中。因此,業務場景數據的采集和標注也是在實際AI模型開發過程中必不可少的重要環節。
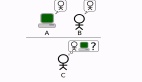
數據標注的質量和規模通常是提升AI模型應用效果的重要因素,然而完全通過人力手動標注數據建立一個高質量、大規模專業領域數據集卻并不容易:標注人員的培訓與手工標注成本高、耗時長。為解決此問題,我們可以利用主動學習的方法,采用“Human-in-the-loop”的交互式框架(圖1)進行數據標注,以有效減少人工數據標注量。
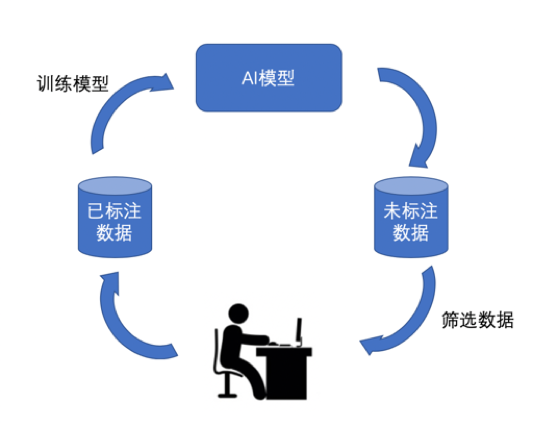
圖1 基于主動學習的“Human-in-the-loop”交互式數據標注框架
主動學習(Active Learning, AL)是一種挑選具有高信息度數據的有效方式,它將數據標注過程呈現為學習算法和用戶之間的交互。其中,算法負責挑選對訓練AI模型價值更高的樣本,而用戶則標注那些挑選出來的樣本。如“Human-in-the-loop”交互式數據標注框架,通過用戶已標注的一部分數據來訓練AI模型,通過此模型來標注剩余數據,再從中篩選出AI模型標注較為困難的數據進行人工標注,再將這些數據用于模型的優化。幾輪過后,用于數據標注的AI模型將會具備較高的精度,更好地進行數據標注。以圖像分類問題舉例,首先,人工挑選并標注一部分圖像數據,訓練初始模型,然后利用訓練的模型預測其余未標注的數據,再通過“主動學習”中的“查詢方法”挑選出模型比較難分辨類別的數據,再人為修正這些“難”數據的標簽并加入訓練集中再次微調(Fine-tuning)訓練模型。“查詢方法”是主動學習的核心之一,最常見的“查詢方法”有基于不確定性的樣本查詢策略和基于多樣性的樣本查詢策略。
基于不確定性的樣本查詢策略可查詢出深度學習模型預測時,靠近決策邊界的樣本。以二分類問題舉例,當一個未標注樣本被預測為任一標簽的概率都是50%時,則該樣本對于預測模型而言是“不確定”的,極有可能被錯誤分類。要注意的是,主動學習是一個迭代過程,每次迭代,模型都會接收認為修正后的標注數據微調模型,通過這個過程直接改變模型決策的邊界,提高分類的正確率。
基于多樣性的查詢策略,可實現對當前深度學習模型下狀態未知樣本的查詢。將通過多樣性查詢挑選出的數據加入訓練集,可豐富訓練集的特征組合,提升模型的泛化能力。模型學習過的數據特征越豐富,泛化能力越強,預測模型適用的場景也越廣。
為解決大數據量標注的痛點,基于主動學習且融合多樣查詢策略的智能標注AI解決方案應運而生。通過EasyDL平臺使用智能標注后,開發者們只需標注數據集中30%左右的數據,即可啟動智能標注在EasyDL后臺自動標注剩余數據,再返回少量后臺難以確定的數據再次進行人工標注,同時提升自動標注的準確性,經過幾輪之后,在實際項目測試中,智能標注功能可以幫助用戶節省70%的數據標注量,極大地減少數據標注中的人力成本和時間成本。
EasyDL零門檻AI開發平臺,面向企業開發者提供智能標注、模型訓練、服務部署等全流程功能,針對AI模型開發過程中繁雜的工作,提供便捷高效的平臺化解決方案。EasyDL面向不同人群提供了經典版、專業版、行業版三種產品形態,其中EasyDL專業版支持深度開發高精度業務模型,內置了豐富的大規模預訓練模型,僅需少量數據即可達到優異的模型效果。目前,EasyDL的智能標注功能已支持計算機視覺CV方向的物體檢測模型、自然語言處理NLP方向的文本分類模型兩大方向的數據標注。選擇EasyDL專業版模型定制,點擊“智能標注“即可進入。使用方法也很簡單,共為三步:
- Step1啟動智能標注
在“數據管理/標注”上傳完訓練數據集后,即可激活“創建智能標注任務”按鈕(圖2),點擊該按鈕后,進入數據集選擇。需要注意的是,系統將自動對選擇的數據集進行校驗。校驗規則如下:
圖像數據集:確保每個標簽的標注框數都超過10個。
文本數據集:數據集中已標注數據量超過600條;每個標注標簽的數據量超過50條;未標注數據的數據量超過600條。
以上圖像和文本數據集之所以采取不同的校驗規則,是因為在實際場景下,文本與圖像的數據集獲取方式及數據規模區別較大,且智能標注后端AI模型訓練的啟動樣本數量不一。
點擊“啟動智能標注”,進入數據校驗階段,若校驗不通過,會出現“智能標注啟動失敗”的提示;若校驗通過,則進入篩選數據階段,用戶需稍作等待。
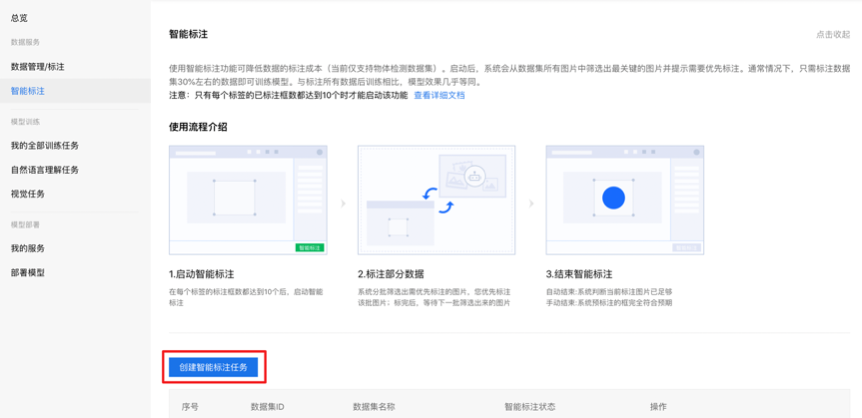
圖2 創建智能標注任務
- Step2標注部分數據
系統會自動從未標注數據集中篩選出最具有代表性、也是最需要優先標注的樣本數據。用戶需要人工標注這些推薦的樣本數據,為了提高標注效率,系統也會提供預標注供用戶修改確認。在圖像智能標注中,用戶勾選右上角的“顯示預標注”開啟該輔助功能(圖3),點擊“滿意預標注結果”即可對預標注結果進行確認;在文本智能標注中,系統會自動顯示預標注標簽,點擊每一條文本右側的“確認”或右上角的“本頁全部確認”對預標注進行確認(圖4)。
確認所有推薦數據的預標注后,用戶可以自主選擇是否進行下一輪數據篩選。圖像智能標注中,若用戶不中止智能標注,則系統會自動進行下一輪;文本智能標注中,由于文本數據集規模一般較大,確認數據預標注的人力成本較高,為了提升用戶體驗,系統不默認進入下一輪迭代,用戶可點擊右上角的“優化智能標注結果”進行下一輪篩選(圖5)。通過多輪篩選,數據預標注準確性也會不斷提升。為了保證數據標注智能,建議用戶至少進行一輪的數據篩選或“優化智能標注”。
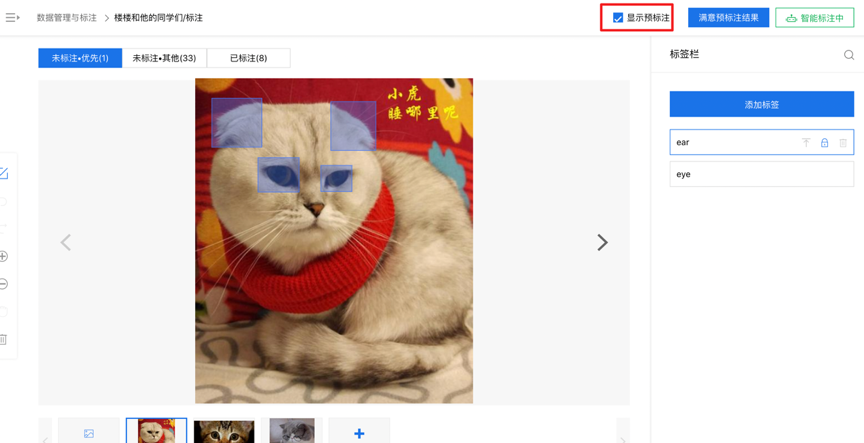
圖3 圖像智能標注
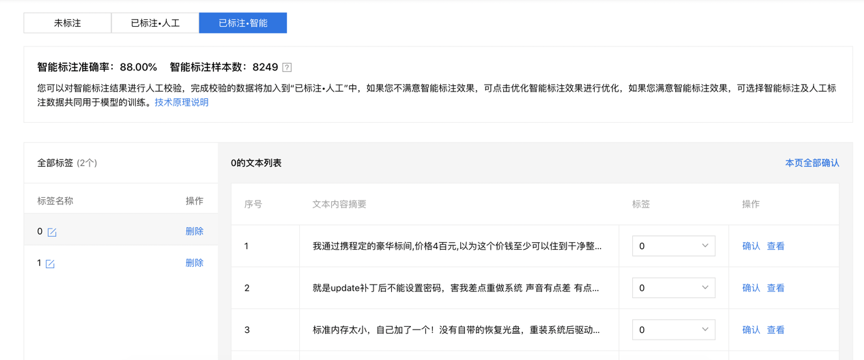
圖4 文本智能標注
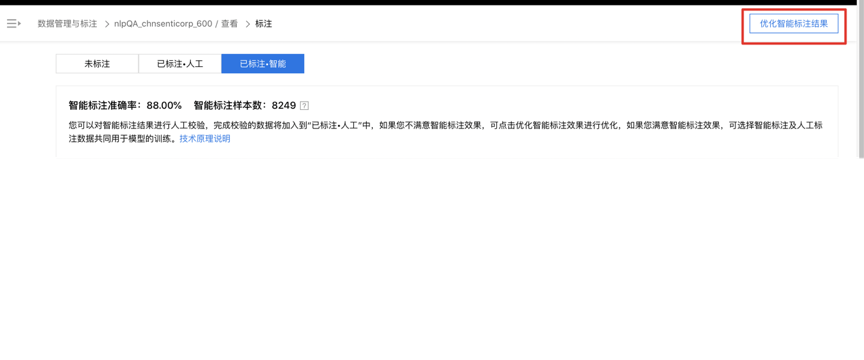
圖5 文本智能標注進入數據篩選優化迭代
- Step3結束智能標注
當用戶覺得當前推薦數據的預標注已足夠準確,不再進行下一輪數據標注推薦篩選,或者系統自動判斷當前標注的數據已足夠時,則進入結束智能標注階段。在圖像智能標注中,系統會彈出提示(圖6),選擇“一鍵標注”系統會自動標注剩余未標注數據,選擇“立即訓練”則停止智能標注,之后可以利用已確認的標注數據去訓練模型;在文本智能標注中,不選擇“優化標注結果”則認為停止智能標注,系統自動標注所有未標注數據,并歸為“已標注·智能”數據集,該類數據與“已標注·人工”均可用于模型訓練。
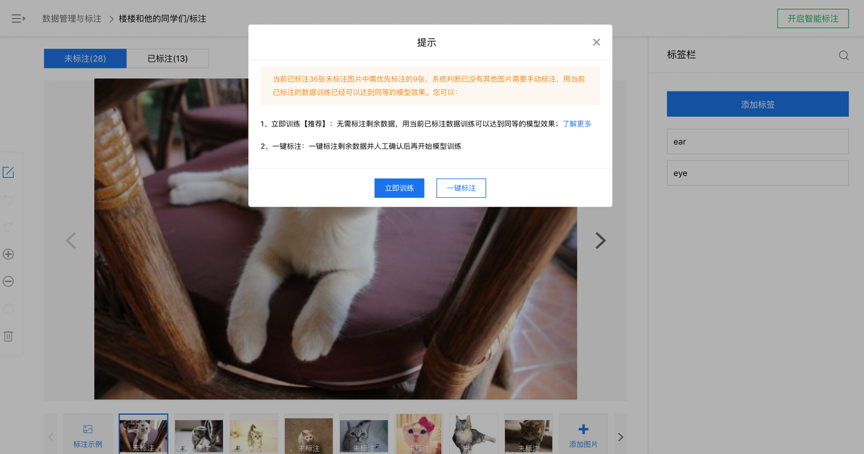
圖6 結束圖像智能標注
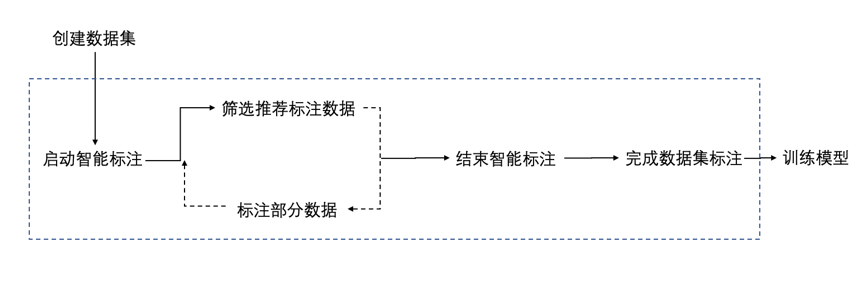
圖7 EasyDL智能標注使用流程圖
在智能標注功能的加持之下,重復枯燥的標注功能都交給AI模型,大大降低了時間與人力成本。在數據方面,EasyDL中的EasyData智能數據服務平臺,提供覆蓋采集、清洗、標注、加工等一站式數據處理功能,并與模型訓練環節無縫對接,通過數據閉環功能支持高效的模型迭代。
百度搜索“EasyDL”或直接訪問:https://ai.baidu.com/easydl/ 體驗智能標注,開發你的高精度業務模型吧!