













“鋼鐵俠”在上周爆了個猛料?別急,咱們先說說L3
話說在上周的世界人工智能大會上
素有硅谷鋼鐵俠之稱的埃隆·馬斯克
可在大會上爆了個猛料
“特斯拉將在今年完成L5的基本功能”
不過他也表示
還有很多細節問題待解決
再來說說國內,2020年3月,中國工信部官網公示了《汽車駕駛自動化分級》推薦性國家標準報批稿,并擬于2021年1月1日開始實施,未來將成為“中國版自動駕駛分級標準”。
這也標志著L3級自動駕駛正式進入了量產的“前夜”。
一邊是L5級別自動駕駛基本完成,另一邊是L3級別自動駕駛即將落地,兩者的巨大差異說明了,從實驗室到真正的落地仍有很長的距離,這是因為需要突破的不僅僅是技術,也有法律法規的逐步完善。
但是不管怎么樣,馬斯克的這番話無疑給整個汽車行業傳遞了明確的信號:
完全自動駕駛汽車的上市
會比我們預計的提前很多
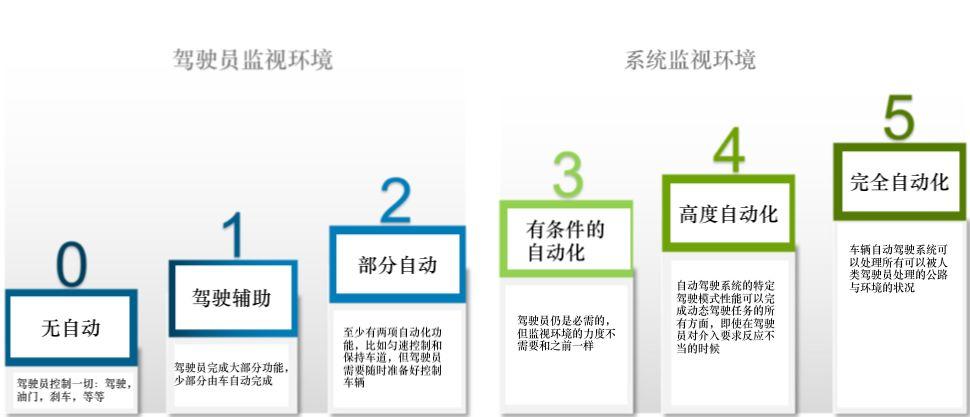
什么是自動駕駛級別?
美國汽車工程師協會(SAE)對汽車自動駕駛技術劃分為Level 0-Level 5共六個級別,其中L1-L2是指智能駕駛輔助系統。在這個階段,人類駕駛員仍然要負責所有駕駛任務;L3則標志著進入自動駕駛范疇,因此也被業內普遍認為是自動駕駛領域的一個重要“分水嶺”。
如今,隨著“新基建”上升為國家戰略,自動駕駛這個新興的領域也正處在5G、AI,以及云計算、大數據中心幾大領域的交匯處,未來有望乘著“新基建”的東風,進一步加速商業化的落地進程。
從這個角度來說,中國汽車產業在大踏步走向自動駕駛后,行業內的競爭激烈程度將急速加劇,而未來誰能最早進入L3級自動駕駛階段,誰就將最大限度獲得新技術帶來的自動駕駛這一全新市場的巨大紅利。那么,汽車行業在自動駕駛新時代即將來臨時,將會遭遇哪些重大的挑戰,并應該采取何種應對的戰略呢?
L3量產前夜新挑戰
事實上,就在今年6月21日,國內首個量產的L3級自動駕駛汽車長安汽車UNI-T就已宣布正式上市,隨著明年年初“中國版自動駕駛分級標準”的實施,越來越多的整車廠都會“標配”L3級自動駕駛,中國汽車行業也有望率先進入自動駕駛的新時代。
可以說,這既是一個充滿挑戰和巨變的新時代,更是一個汽車行業同時間和智慧“賽跑”的新時代,核心的原因就在于,對于整車廠來說,原有的經驗不再有效,汽車最核心的價值不再是曾經熟悉的“三大件”(發動機、變速箱和底盤)系統,而是軟件定義汽車的時代。
數據顯示,目前汽車的車內代碼行數已從上世紀80年代的5萬行,發展到2010年代的約1200萬行,再到2018年的約1.5億行,而2025年則可能會躍升到15億行,如此龐大的代碼量,對整個行業開發人員的能力將形成巨大挑戰,更會帶來前所未有的數據量的激增。
對此,戴爾科技集團售前系統工程部解決方案架構師林小引形容的比喻說:“一般開采出來一噸礦石,才能提煉出幾克黃金。那么要訓練出滿足L3級別的自動駕駛算法,所需要的裸數據則在50-100PB量級,而這個過程始終圍繞著數據展開,并由數據來驅動的。”
更關鍵的是,由自動駕駛所帶來的這種海量非結構化數據如何“存儲、管理、利用和歸檔備份管理”,同樣也是非常具有挑戰的,可以從幾個維度來做觀察:
一是,從高性能看
自動駕駛研發中有大量并行的工作負載,包括:數據上傳、數據預處理、深度學習、模擬仿真、大數據分析、歸檔備份等。這些并行的工作負載需要底層存儲提供極高的吞吐性能,以便讓服務器中的算力快速讀到所需的數據,這樣才能夠大量節約研發人員的工作時間,使得整個自動駕駛的研發周期縮短,加快產品上市時間。
二是,從高可用看
自動駕駛的一些典型的工作場景是需要持續運行數天甚至數周的時間,如深度學習中對模型算法的訓練,軟件在環(SiL)的仿真模擬中對感知決策算法的反復回歸優化等。因此,這也需要底層數據存儲能夠提供企業級的高可用,保障自動研發長周期工作任務的持續運行而不中斷。
三是,從擴展性看
自動駕駛的研發過程中,還需要采集海量的真實數據并配合虛擬仿真引擎來測試和驗證在罕見場景中算法的可靠性。同時,這些數據的積累也是一個線性的過程,甚至有明確的爬坡計劃表。所以,這就需要底層數據存儲能夠以橫向擴展的模式由小到大線性地擴展數據存儲規模,同時做到在擴容過程中對現有研發應用的無影響。
四是,從安全性看
自動駕駛始終是依靠數據來驅動的,保障數據的安全性變得首當其沖。根據《中華人民共和國測繪法》的規定,自動駕駛在公開道路上所采集的數據需要在具有甲級測繪資質的圖商的監管下使用,所有對數據的訪問都需要接受圖商的審計,這也就意味著自動駕駛過程中需要對數據有足夠的、強大的保護機制。
五是,從運維角度
由于數據量巨大,支撐自動駕駛的存儲基礎架構的規模同樣也比較龐大。在這樣的背景下,如何能夠簡單、方便地搭建和管理大規模的存儲設備集群,降低運維成本,把更多的資源投入到自動駕駛的研發上,是整車廠在投入自動駕駛研發之初,就必須重點考量的。
由此可見,自動駕駛的新時代是美好的,但也是挑戰巨大的,采用何種技術戰略和產品方案來化解自動駕駛帶來的海量非結構化數據壓力,并打造出整車廠的新競爭力不僅是大勢所趨,更是迫在眉睫。
加速自動駕駛落地
那么,在L3級自動駕駛即將量產的前夜,汽車整車廠又該如何在自動駕駛領域實現突圍呢?
戴爾科技集團近期正式發布了Dell EMC PowerScale無疑給出了一個新的答案,它通過把戴爾科技強大的橫向擴展文件系統OneFS和卓越的服務器平臺PowerEdge有機結合起來,在延續了Isilon高效地存儲、管理、保護和分析非結構化數據的同時,又通過一系列的技術創新,為自動駕駛提供了更為強大的支持能力,為加速自動駕駛的落地真正打牢了基礎。

首先,在大規模存儲的高性能方面
與傳統的存儲系統只能縱向擴展相比,PowerScale能夠使系統橫向擴展,無縫地將現有文件系統或容量增加到PB級,就能以線性方式提高性能和容量。同時,PowerScale還可以根據文件、目錄級別或者工作負載的不同優化訪問模式,讓單個主機可以快速導入或者讀取數據。
其次,在容量和可伸縮性方面
PowerScale也充分滿足自動就是對于存儲基礎架構的要求,單個文件系統就能夠提供從最小7TB到多PB規模的存儲能力,并支持對數百萬個文件進行操作。
不僅如此,用戶需要的新增容量也可以在幾分鐘內添加到現有的Isilon卷中,沒有停機時間,也不會中斷數據可用性,而且不會降低性能。此外,當面對高度并發的自動計時工作負載時,PowerScale的橫向擴展體系結構和“獨一無二”的OneFS操作系統,還能夠進一步消除傳統存儲解決方案所共有的性能瓶頸。

第三,在存儲可用性和數據歸檔方面
PowerScale具有的CloudPools功能也能夠支持數據分層策略,這個策略決定的自動分層解決方案允許根據自動駕駛項目的不同階段,將數據與極佳價格/性能的存儲層做自動的匹配。
由此帶來的好處體現在:自動分層策略可以讓關鍵的“熱數據”(如正在使用的自動駕駛傳感器數據)保存在更高性能的存儲層上,而“溫數據”或“冷數據”(如已經發布的車輛數據)可以放在更經濟高效和更高密度的歸檔層中。
同時,PowerScale也可以滿足自動駕駛的相關測試數據長期存儲歸檔和安全性的要求,同時也能快速地進行數據恢復和再次進行仿真測試的需求,而無需對現有的策略和流程進行更改。
最后,在數據的流通性方面
PowerScale也具備廣泛的適應性,它不僅支持NAS協議(如NFS3、NFS4、SMB2、SMB3和FTP)來訪問數據,而且還可以通過HDFS協議(Hadoop分布式文件系統)來訪問,通過將高效的存儲平臺與Hadoop集成起來,PowerScale可以讓自動駕駛開發人員能夠加快分析海量數據,并在幾分鐘內獲得結果。內置HDFS支持消除了移動數據文件和Hadoop存儲的時間和開銷。

另外,PowerScale搭載的OneFS 9.0還支持對象存儲訪問協議S3,因此用戶可以把數據更輕松的遷移到云端環境之中,滿足更多的數據流通性的需求。換句話說,這種支持多協議訪問同一數據的特性,既解決了不同用戶的不同訪問方式的需求,也解決了數據在存儲和使用中的一致性和完整性問題,如源數據的存儲訪問,和大數據分析之間數據的差異性問題等。
值得一提的是,全新推出的PowerScale F系列還增加了全閃存和NVMe節點的能力,更加高效和靈活的滿足自動駕駛行業用戶最新的發展需求。例如,在圖商監管領域,目前國內所有的路采數據需要先由圖商進行審查和脫敏處理后才能交由自動駕駛研發商進行后續處理,那么PowerScale F系列就非常適合構建一個高性能的存儲集群,由圖商審查和脫敏處理后使用。
同樣,在自動駕駛的深度學習領域,越來越多的研發團隊都在借助TensorFlow或PyTorch等新的深度學習和機器學習解決方案展開研發工作,而PowerScale F系列也可以為深度學習算法提供高性能的底層存儲,由此加快深度學習訓練的速度并提高GPU的利用率。
不難看出,PowerScale之于自動駕駛研發中面臨的數據和存儲的挑戰,真正做到了“硬件更靈活,成本更節約,生產效率也更高”。其中在數據建模階段,PowerScale可以為一個集群中的每個節點添加容量、性能和彈性,這使得自動駕駛開發團隊能夠利用整個群集的性能,解決大規模數據存儲的高性能難題。
更關鍵的是,在訓練階段,通過將高效的PowerScale存儲平臺與Hadoop集成起來,自動駕駛開發人員還能夠更快的分析海量數據,并在幾分鐘內獲得結果,可以說真正為自動駕駛的研發提供了一個最佳選擇。
背后的底蘊與底氣
毫無疑問,作為中國汽車產業轉型升級的重要新方向,自動駕駛是汽車產業新一輪科技創新的重要載體,也將為更多的整車廠提供巨大的發展空間,而戴爾科技通過不斷的技術創新,可以說為整車廠的自動駕駛研發提供了更加高效和靈活的產品和解決方案,而在這背后正是其構筑的三重優勢,讓它具備了賦能的底蘊和底氣。
投產檢證
戴爾科技在自動駕駛領域的優勢不是“紙上談兵”,而是經過大量整車廠和一級供應商自動駕駛研發/驗證系統的實際投產驗證,證明了其解決方案是穩定、可靠和高效的。
數據顯示,全球超過70%的領先高級駕駛員輔助系統/自動駕駛一級供應商使用OneFS進行ADAS開發;排名前20位的汽車供應商中有70%以上使用由OneFS提供支持的PowerScale存儲系統;同時,戴爾科技高級駕駛員輔助系統/自動駕駛(ADAS/AD)客戶已部署了超過1EB由OneFS支持的PowerScale存儲,用于支持汽車工作流程。
除此之外,目前戴爾科技在全球落地的自動駕駛研發基礎架構案例高達40多個,包括了歐洲著名的Tier-1供應商、國內領先的自主品牌整車廠、日系頭部的整車廠等,還有更多的項目正在“有條不紊”的落地之中。
端到端
戴爾科技為自動駕駛提供的研發/驗證基礎架構,還是端到端的解決方案,包括計算、存儲、網絡、云計算、HPC、AI和大數據等,這種端到端的優勢在于,可以最大化地解決了各個產品模塊之間的兼容性集成問題,縮短自動駕駛項目的集成時間,不僅可以大大降低項目風險,同時也可以提供最佳實踐和成功經驗輸出為項目“保駕護航”。
確實如此,大型集成項目如果分別采用不同的解決方案,那么每一個不同產品的的兼容性驗證將會花費大量的時間。更關鍵的是,自動駕駛的升級速度比每一個產品的兼容性列表升級的速度更快,因此對客戶來說這中間的風險就非常巨大了,而戴爾科技提供的端到端解決方案,最大的優勢就在于可以降低項目的風險和節約項目的時間。
持續創新
戴爾科技在產品和解決方案上的不斷創新,又為自動駕駛項目的加速研發和驗證提供了堅實的基礎。以最新推出的PowerScale為例,它就可以憑借產品的獨特功能特性,大幅節省海量自動駕駛研發數據在研發各個環節中的“數據搬遷”時間,同時配合戴爾科技提供的增值元數據管理平臺DMS,由此可以幫助客戶加速自動駕駛的研發和驗證的過程。
展望未來,林小引表示,自動駕駛的研發是一個投入非常大的項目,而且對大多數國內汽車行業的客戶來說都是新課題,此前并沒有經驗可循。為此,他也向有意加大自動駕駛研發投入的整車廠提出了兩個方面的建議:
❒ 一方面,在自動駕駛領域的基礎架構建設方面,整車廠盡量不要自己從頭搞一遍,因為自動駕駛的試錯成本非常高,因此可以借助該領域具備豐富經驗和產品方案的合作伙伴的助助力;
❒ 另一方面,汽車行業客戶的核心目標是去整合資源把自動駕駛的黃金算法挖掘出來,并不是把自身訓練成一個基礎架構的專家,專業的事情要交給專業的廠商去做,而戴爾科技無論是解決方案還是落地經驗,都可以讓客戶的自動駕駛項目更快、更好地完成。
總 結
受“新基建”、5G以及L3級自動駕駛標準等因素的影響,今年大量的自動駕駛勢必會加速進入到產品落地的新階段,整個自動駕駛領域也會迎來新一輪的爆發期,而戴爾科技借助PowerScale的不斷技術創新和突破,無疑會幫助汽車行業客戶尋找到更多的新模式、新業態和新未來,這是戴爾科技在中國自動駕駛領域能夠不斷賦能的關鍵所在,更是之于整個汽車行業今后轉型升級的新價值所在。
相關內容推薦:「助力新基建發展」戴爾科技集團打出組合拳
相關產品:PowerEdge XR2 工業機架式服務器














