8.6M超輕量中英文OCR模型開源,訓練部署一條龍
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
要說生活里最常見、最便民的AI應用技術,OCR(光學字符識別)當屬其中之一。
尋常到日常辦理各種業務時的身份證識別,前沿到自動駕駛車輛的路牌識別,都少不了它的加持。
作為一名開發者,各種OCR相關的需求自然也少不了:卡證識別、票據識別、汽車場景、教育場景文字識別……
那么,這個模型大小僅8.6M,沒有GPU也能跑得動,還提供自定義訓練到多硬件部署的全套開發套件的開源通用OCR項目,了解一下?
話不多說,先來看效果。


可以看到,無論文字是橫排、還是豎排,這個超輕量模型都有不錯的識別效果。
難度略高,且實際生活當中經常遇到的場景也不在話下:

那么,如果情況更復雜一點,這么小的模型能hold住嗎?
畢竟,在實際應用場景中,圖像中的文字難免存在字符彎曲、模糊等諸多問題。
比如,并不高清的路牌:

主體部分基本都識別無誤,只有英文小字部分因為確實比較模糊,識別效果不太理想。
再看一張文字背景復雜的圖像識別效果:

出現一個錯別字,扣一分。滿分10分的話,可以打個9分了。
其實,在實際OCR項目落地過程中,開發者往往面臨兩個痛點:
1. 無論是移動端和服務器端,待識別的圖像數目往往非常多,都希望模型更小,精度更高,預測速度更快。GPU太貴,最好使用CPU跑起來更經濟。在滿足業務需求的前提下,模型越輕量占用的資源越少。
2. 實際業務場景中,OCR面臨的問題多種多樣,業務場景個性化往往需要自定義數據集重新訓練,硬件環境多樣化就需要支持豐富的部署方式。再加上收集數據之類的dirty work,往往一個項目落地中的大部分時間都用在算法研發以外的環節中,迫切需要一套完整全流程的解決方案,來加快研發進度,節約寶貴的研發時間。
也就是說,超輕量模型及其全流程解決方案,尤其對于算力、存儲空間有限的移動端、嵌入式設備而言,可以說是剛需。
而在這個開源項目中,開發者也貼心提供了直接可供測試的Demo。
在量子位的實際上手測試中,在移動端Demo上這樣一個不到10M的模型,基本上可以做到秒出效果。

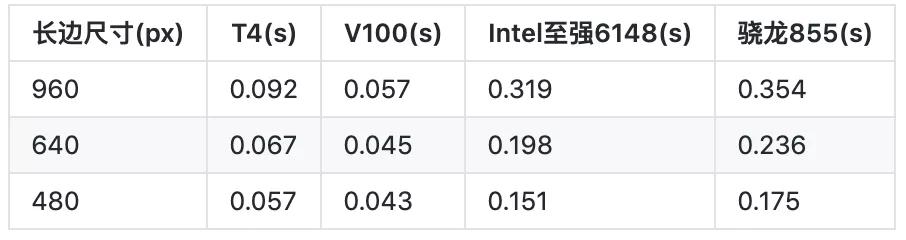
在中文公開數據集ICDAR2017-RCTW上,限定圖片長邊尺寸960px,測試數據與測試條件相同的前提下,將該項目與之前一度登上GitHub熱榜的Chineseocr_Lite(5.1k stars)最新發布的10M模型進行測試對比。在模型大小、精度和預測速度方面,結果如下:
該8.6M超輕量模型,V100 GPU單卡平均預測耗時57ms,CPU平均預測耗時319ms。
而Chineseocr_Lite的10M模型,V100單卡預測速度230ms,CPU平均預測耗時739ms。
當然,這里面模型預測速度的提升不僅是因為模型大小更小了,也離不開算法與框架深度適配優化。
項目中給出的Benchmark如下:
作為一名面向GitHub編程的程序員,頓時感到老板再來各種OCR需求都不方了。
而且這個8.6M超輕量開源模型,背后還有大廠背書。
因為出品方不是別人,是國產AI開發一哥百度,他們把這個最新開源的OCR工具庫取名:PaddleOCR。
GitHub 地址:https://github.com/PaddlePaddle/PaddleOCR
8.6M的通用OCR模型如何煉成
PaddleOCR發布的超輕量模型,主要由4.1M的檢測模型和4.5M的識別模型組成。
其中,檢測模型的Base模型采用DB算法,文本模型的Base模型采用經典的CRNN算法。
鑒于MobileNetV3在端側系列模型中的優越表現,兩個模型均選擇使用MobileNetV3作為骨干網絡,可將模型大小初步減少90%以上。
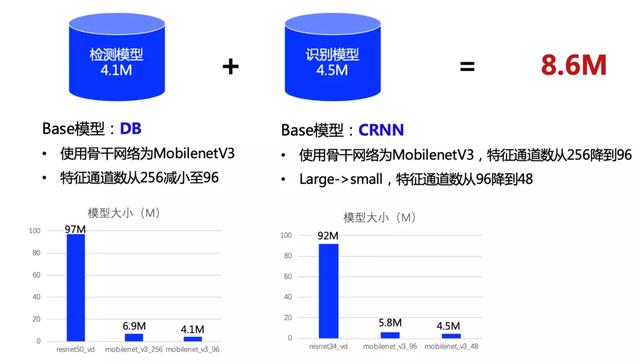
除此之外,開發人員還采用減小特征通道數等策略,進一步對模型大小進行了壓縮。
模型雖小,但是訓練用到的數據集卻一點也不少,根據項目方給出的數據,模型用到的數據量(包括合成數據)大約在百萬到千萬量級。

但是也有開發者可能會問,在某些垂類場景,通用OCR模型的精度可能不能滿足需求,而且算法模型在實際項目部署也會遇到各種問題,應該怎么辦呢?
PaddleOCR從訓練到部署,提供了非常全面的一條龍指引,堪稱「最全OCR開發者大禮包」。
「最全OCR開發者大禮包」

△禮包目錄,堪稱業界最全
支持自定義訓練
OCR業務其實有特殊性,用戶的需求很難通過一個通用模型來滿足,之前開源的Chineseocr_Lite也是不支持用戶訓練的。
為了方便開發者使用自己的數據自定義超輕量模型,除了8.6M超輕量模型外,PaddleOCR同時提供了2種文本檢測算法(EAST、DB)、4種文本識別算法(CRNN、Rosseta、STAR-Net、RARE),基本可以覆蓋常見OCR任務的需求,并且算法還在持續豐富中。
特別是「模型訓練/評估」中的「中文OCR訓練預測技巧」,更是讓人眼前一亮,點進去可以看到「中文長文本識別的特殊處理、如何更換不同的backbone等業務實戰技巧」,相當符合開發者項目實戰中的煉丹需求。
打通預測部署全流程
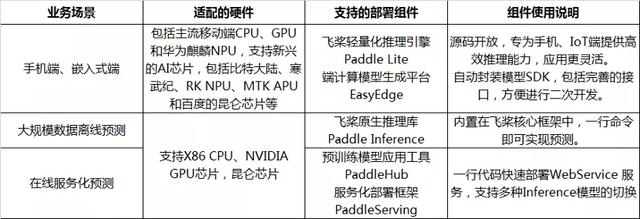
對開發者更友好的是,PaddleOCR提供了手機端(含iOS、Android Demo)、嵌入式端、大規模數據離線預測、在線服務化預測等多種預測工具組件的支持,能夠滿足多樣化的工業級應用場景。
數據集匯總
項目幫開發者整理了常用的中文數據集、標注和合成工具,并在持續更新中。
目前包含的數據集包括:
- 5個大規模通用數據集(ICDAR2019-LSVT,ICDAR2017-RCTW-17,中文街景文字識別,中文文檔文字識別,ICDAR2019-ArT)
- 大規模手寫中文數據集(中科院自動化研究所-手寫中文數據集)
- 垂類多語言OCR數據集(中國城市車牌數據集、銀行信用卡數據集、驗證碼數據集-Captcha、多語言數據集)
還整理了常用數據標注工具(labelImg、roLabelImg、labelme)、常用數據合成工具(text_renderer、SynthText、SynthText_Chinese_version、TextRecognitionDataGenerator、SynthText3D、UnrealText)
并且開源以來,受到開發者的廣泛關注,已經有大量開發者投入到項目的建設中并且貢獻內容。
真·干貨滿滿。
體驗一下?
看到這里,你心動了嗎?如果還想眼見為實,PaddleOCR已經提供了在線Demo,網頁版、手機端均可嘗試。
感興趣的話收好下面的傳送門,親自體驗起來吧~
傳送門:
項目地址:https://github.com/PaddlePaddle/PaddleOCR
網頁版Demo:https://www.paddlepaddle.org.cn/hub/scene/ocr
移動端Demo:
https://ai.baidu.com/easyedge/app/openSource?from=paddlelite