













智源發布全球最大中英文向量模型訓練數據集!規模高達3億文本對
9月15日,北京人工智能產業峰會暨中關村科學城科創大賽頒獎典禮現場,智源研究院發布面向中英文語義向量模型訓練的大規模文本對數據集MTP(massive text pairs)。
這是全球最大的中、英文文本對訓練數據集,數據規模達3億對,具有規模巨大、主題豐富、數據質量高三大特征,進而可以推動解決中文模型訓練數據集缺乏問題。

通用語義向量模型是決定大模型性能的關鍵組件,可以鏈接外模型與外部知識;由「關聯文本」為基本元素的優質訓練數據,是構建通用語義向量模型的核心要素。
本次開源的MTP數據集,正是智源BGE中英文語義向量模型訓練所用中英文數據。
3億中英向量模型訓練數據開放
數據在大模型訓練中至關重要,構建高質量開源數據集,特別是用于訓練基礎模型的開源數據集對大模型發展意義重大,然而中文社區卻鮮少數據開源貢獻者。

本次發布的全球最大語義向量模型訓練數據MTP,具備如下特征:
- 規模巨大:
3億文本對,中文1億,英文2億。
- 主題豐富:
源自海量優質文本數據,涉及搜索、社區問答、百科常識、科技文獻等多種主題。
- 數據質量高:
數據經過必要的采樣、抽取、過濾獲得;由該數據訓練得到的語義向量模型BGE (BAAI General Embedding)性能大幅領先同類別模型。

MTP數據集鏈接:https://data.baai.ac.cn/details/BAAI-MTP
BGE 模型鏈接:https://huggingface.co/BAAI
BGE 代碼倉庫:https://github.com/FlagOpen/FlagEmbedding
鑒于數據的重要性,智源在2021年就推出了全球最大語料庫WuDaoCorpora,開放200GB高質量低風險中文語料,由400余個產學研單位合作,已有770多個研發團隊申請,為微軟、哈佛大學、斯坦福大學、華為、阿里巴巴、騰訊、鵬城實驗室等提供數據服務,有效支撐全球大模型相關研究。
今年開放的最大規模、可商用、持續更新的中文開源指令數據集COIG,由來自全球40余個機構的100多名工程師共同參與,創造了跨越國界、緊密合作的全球數據開源動人故事。
下載達數十萬,廣受歡迎的BGE模型升級更新
BGE 語義向量模型一經發布就備受大模型開發者社區關注,目前Hugging Face累計下載量達到數十萬,且已被LangChain, LangChain-Chatchat, llama_index 等知名開源項目集成。
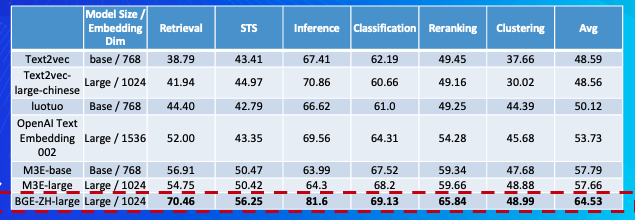
中文語義向量模型評測(C-MTEB)
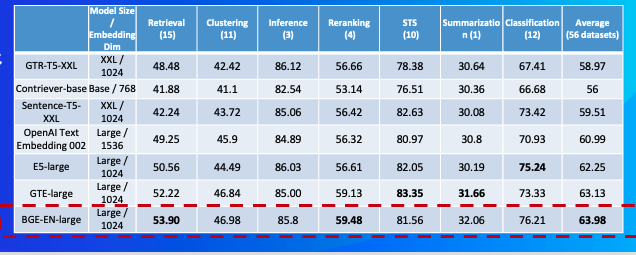
英文語義向量模型評測榜(MTEB)
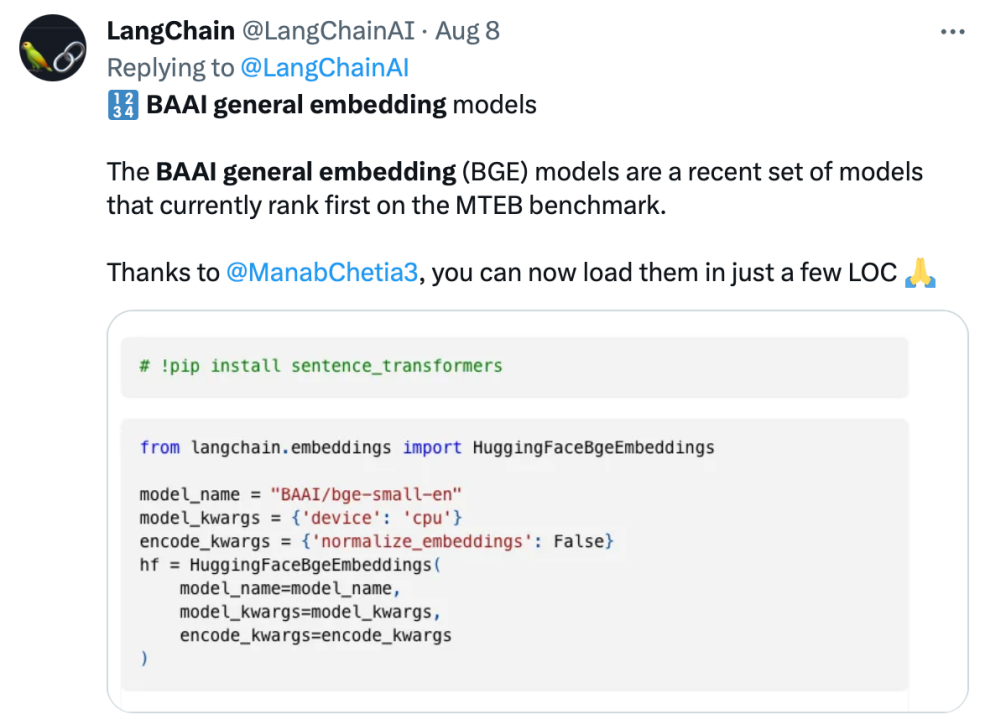
Langchain官方推文:「BGE模型在MTEB基準上排名第一」
LangChain聯合創始人兼首席執行官Harrison Chase推薦
基于社區反饋,BGE進一步優化更新,表現更加穩健、出色。具體升級如下:
- 模型更新:
BGE-*-zh-v1.5緩解了相似度分布問題,通過對訓練數據進行過濾,刪除低質量數據,提高訓練時溫度系數temperature至0.02,使得相似度數值更加平穩 。
- 新增模型:
開源BGE-reranker 交叉編碼器模型,可更加精準找到相關文本,支持中英雙語。不同于向量模型需要輸出向量,BGE-reranker直接文本對輸出相似度,排序準確度更高,可用于對向量召回結果的重新排序,提升最終結果的相關性。
- 新增功能:
BGE1.1增加難負樣本挖掘腳本,難負樣本可有效提升微調后檢索的效果;在微調代碼中增加在微調中增加指令的功能;模型保存也將自動轉成 sentence transformer 格式,更方便模型加載。
值得一提的是,日前智源聯合Hugging Face發布了一篇技術報告,報告提出用C-Pack增強中文通用語義向量模型。

報告地址:https://arxiv.org/abs/2309.07597
構建大模型時代的類Linux生態
伴隨2022年末ChatGPT 橫空出世,全球大模型研發進入如火如荼的爆發期,而激烈的競爭與高昂的成本,也同時推動著開源崛起成為人工智能發展的關鍵推動力量。
標志性的事件是今年5月在全球人工智能圈廣為流傳的一篇Google內部文件,聲稱「開源AI將擊敗谷歌和OpenAI」;來自Meta的代表性開源模型 Llama則對當前產業發展起到至關重要的作用。
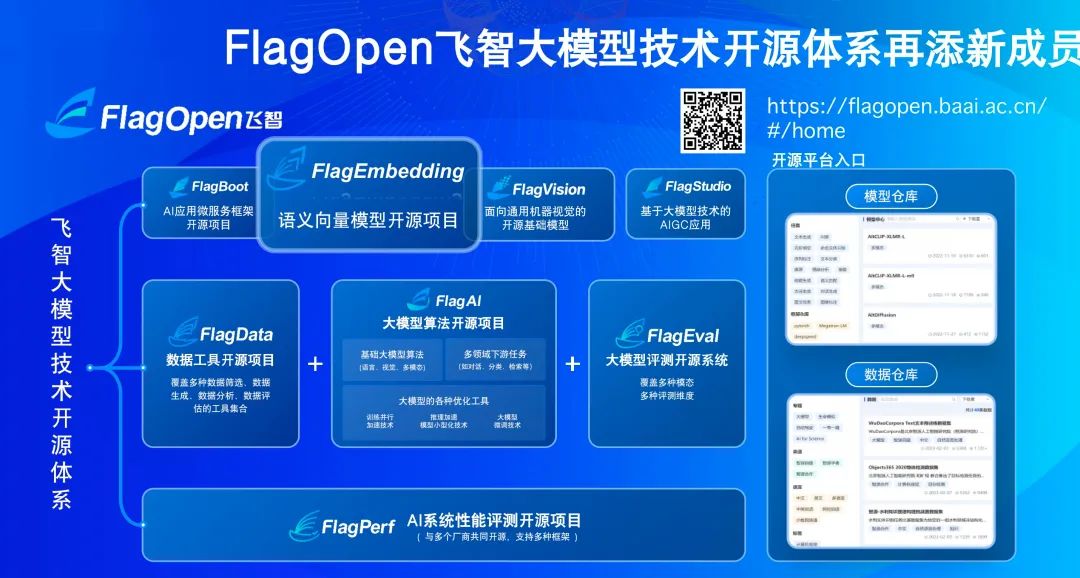
作為中國大模型開源生態圈的代表機構,智源正在著力打造FlagOpen飛智大模型技術開源體系,引領共建共享大模型時代的「類Linux」開源開放生態。
上線于2022年11月,正式發布于2023年2月,FlagOpen大模型技術開源體系先見性地預見大模型開源建設這一大勢所趨。
現在,智源大模型技術開體系 FlagOpen 新增 FlagEmbedding 版塊,聚焦于 Embedding 技術和模型,BGE 是其中首個開源模型。
FlagEmbedding:https://github.com/FlagOpen/FlagEmbedding
在BGE項目之外,FlagOpen還有包括大模型算法、模型、數據、工具、評測等重要組成部分。
其中,FlagEval(天秤)大模型評測體系及開放平臺,構建3維評測體系、覆蓋600余項全面能力評測,旨在建立科學、公正、開放的評測基準、方法、工具集,協助研究人員全方位評估基礎模型及訓練算法的性能。
每月發布的FlagEval大模型評測榜單,對主流模型進行多維評測解讀,打造公正全面金標準,正在愈來愈成為大模型能力評價的風向標。





















