中英文超大AI模型世界紀錄產生,大模型競賽新階段來了
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
超大AI模型訓練成本太高hold不住?連市值萬億的公司都開始尋求合作了。
本周,英偉達與微軟聯合發布了5300億參數的“威震天-圖靈”(Megatron-Turing),成為迄今為止全球最大AI單體模型。
僅僅在半個月前,國內的浪潮發布了2500億參數的中文AI巨量模型“源1.0”。
不到一個月的時間里,最大英文和中文AI單體模型的紀錄分別被刷新。
而值得注意的是:
技術發展如此之快,“威震天-圖靈”和“源1.0”還是沒有達到指數規律的預期。
要知道,從2018年開始,NLP模型參數近乎以每年一個數量級的速度在增長。
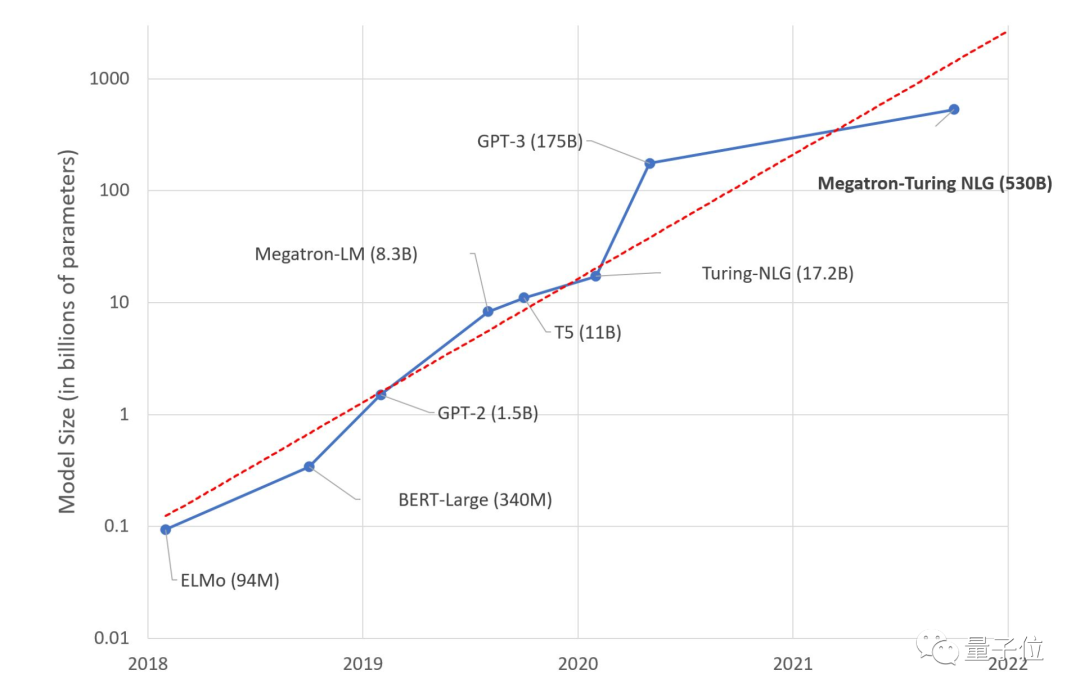
△ 近年來NLP模型參數呈指數級上漲(圖片來自微軟)
而GPT-3出現后,雖然有Switch Transformer等萬億參數混合模型出現,但單體模型增長速度已經明顯放緩。

無論是國外的“威震天-圖靈”,還是國內的“源1.0”,其規模和GPT-3沒有數量級上的差異。即便“威震天-圖靈”和“源1.0”都用上了各自最強大的硬件集群。
單體模型是發展遇到瓶頸了么?
超大模型的三個模式
回答這個疑問,首先得梳理一下近年來出現的超大規模NLP模型。
如果從模型的開發者來看,超大規模NLP模型的研發隨時間發展逐漸形成了三種模式。
一、以研究機構為主導
無論是開發ELMo的Allen研究所、還是開發GPT-2的OpenAI(當時還未引入微軟投資)都不是以盈利為目標。
且這一階段的超大NLP模型都是開源的,得到了開源社區的各種復現與改進。
ELMo有超過40個非官方實現,GPT-2也被國內開發者引入,用于中文處理。

二、科技企業巨頭主導
由于模型越來越大,訓練過程中硬件的優化變得尤為重要。
從2019年下半年開始,各家分別開發出大規模并行訓練、模型擴展技術,以期開發出更大的NLP模型。英偉達Megatron-LM、谷歌T5、微軟Turing-NLG相繼出現。

今年國內科技公司也開始了類似研究,中文AI模型“源1.0”便是國內硬件公司的一次突破——
成就中文領域最大NLP模型,更一度刷新參數最多的大模型紀錄。
“源1.0”不僅有高達5TB的全球最大中文高質量數據集,在總計算量和訓練效率優化上都是空前的。
三、巨頭與研究機構或巨頭之間相互合作
擁有技術的OpenAI由于難以承受高昂成本,引入了微軟10億美元投資。依靠海量的硬件與數據集資源,1750億參數的GPT-3于去年問世。
但是,今年萬億參數模型的GPT-4并沒有如期出現,反而是微軟與英偉達聯手,推出了“威震天-圖靈”。
我們再把目光放回到國內。
“威震天-圖靈”發布之前,國內外涌現了了不少超大AI單體模型,國內就有阿里達摩院PLUG、“源1.0”等。
像英偉達、微軟、谷歌、華為、浪潮等公司加入,一方面是為AI研究提供大量的算力支持,另一方面是因為他們在大規模并行計算上具有豐富的經驗。
當AI模型參數與日俱增,達到千億量級,訓練模型的可行性面臨兩大挑戰:
1、即使是最強大的GPU,也不再可能將模型參數擬合到單卡的顯存中;
2、如果不特別注意優化算法、軟件和硬件堆棧,那么超大計算會讓訓練時長變得不切實際。
而現有的三大并行策略在計算效率方面存在妥協,難以做到魚與熊掌兼得。
英偉達與微軟合體正是為此,同樣面對該問題,浪潮在“源1.0”中也用了前沿的技術路徑解決訓練效率問題。
從“源1.0”的arXiv論文中,我們可以窺見這種提高計算效率的方法。
在對源的大規模分布式訓練中,浪潮采用了張量并行、流水線并行和數據并行的三維并行策略。
“威震天-圖靈”和“源1.0”一樣,在張量并行策略中,模型的層在節點內的設備之間進行劃分。
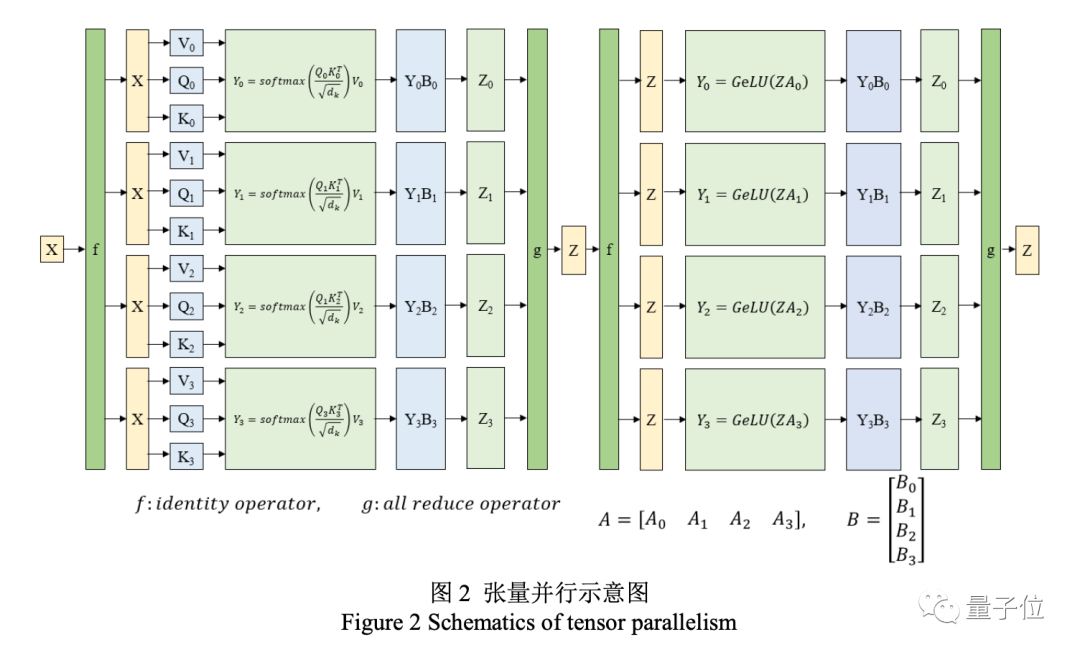
流水線并行將模型的層序列在多個節點之間進行分割,以解決存儲空間不足的問題。
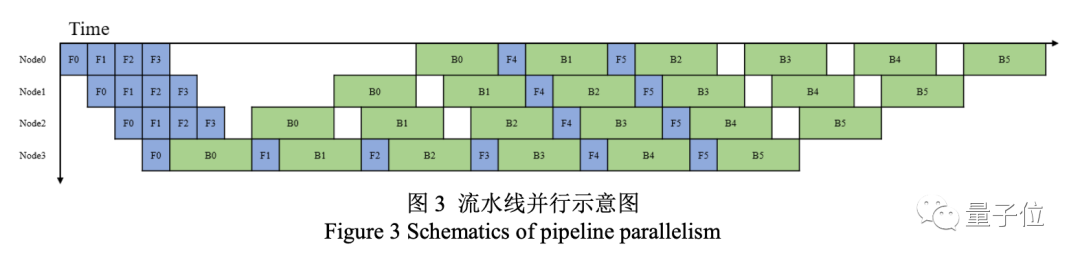
另外還有數據并行策略,將全局批次規模按照流水線分組進行分割。
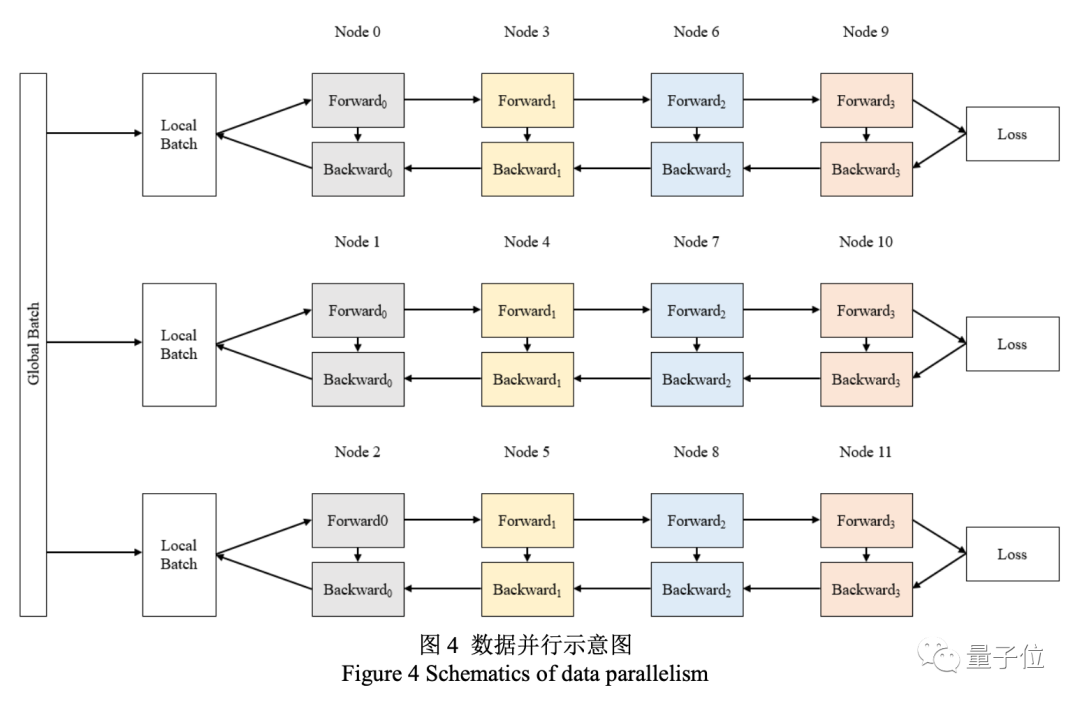
三家公司運用各自的技術,將最先進的GPU與尖端的分布式學習軟件堆棧進行融合,實現了前所未有的訓練效率,最終分別打造出英文領域和中文領域的最大AI單體模型。
訓練超大規模自然語言模型成本升高,技術上殊途同歸,形成研究機構與科技巨頭協同發展,三種探索模式并駕齊驅的局面。
中英AI模型互有勝負
訓練成本趨高,技術趨同,為何各家公司還是選擇獨自研究,不尋求合作?
我們從GPT-3身上或許可見一斑。
去年發布的GPT-3不僅未開源,甚至連API都是限量提供,由于獲得微軟的投資,今后GPT-3將由微軟獨享知識產權,其他企業或個人想使用完整功能只能望洋興嘆。
訓練成本奇高、道德倫理問題以及為了保證行業領先地位,讓微軟不敢下放技術。其他科技公司也不可能將自己的命運交給微軟,只能選擇獨自開發。
尤其對于中國用戶來說,以上一批超大模型都不是用中文數據集訓練,無法使用在中文語境中。
中文語言的訓練也比英文更難。英文由單詞組成,具有天然的分詞屬性。
而中文需要對句子首先進行分詞處理,如“南京市長江大橋”, 南京市|長江|大橋、南京|市長|江大橋,錯誤的分詞會讓AI產生歧義。
相比于英文有空格作為分隔符,中文分詞缺乏統一標準,同樣一個詞匯在不同語境、不同句子中的含義可能會相差甚遠,加上各種網絡新詞匯參差不齊、中英文混合詞匯等情況,要打造出一款出色的中文語言模型需要付出更多努力。
所以國內公司更積極研究中文模型也就不難理解了。
即便難度更高,國內公司還一度處于全球領先,比如數據集和訓練效率方面。
據浪潮論文透露,“源1.0”硬件上使用了2128塊GPU,浪潮共搜集了850TB數據,最終清洗得到5TB高質量中文數據集。
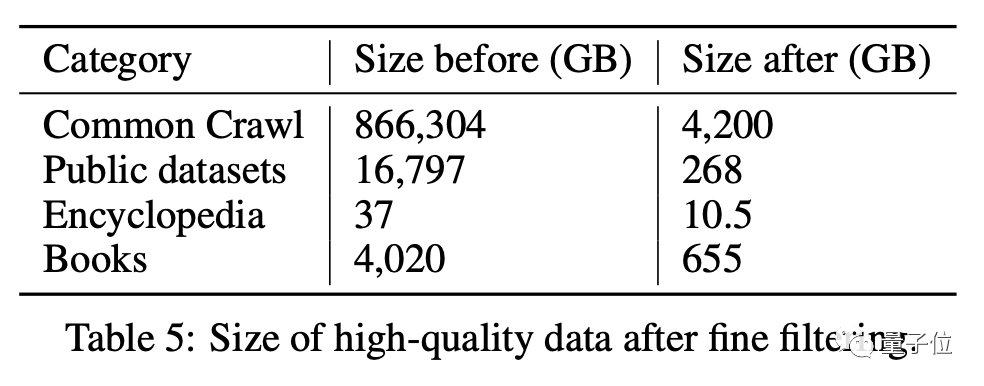
其文字數據體積多于“威震天-圖靈”(835GB),而且中文信息熵大大高于英文,信息量其實更大。
在訓練效率方面,“源1.0”訓練用了16天,“圖靈威-震天”用了一個多月,前者數據量是后者3倍有余,耗時卻只有后者一半——
其專注中文,關注效率努力也可見一斑。
大模型你來我往間能看出,發展已走入百花齊放互不相讓的階段,這給我們帶來新的思考:AI巨量模型既然不“閉門造車”,那如何走向合作?
多方合作可能才是未來
表面上“威震天-圖靈”(Megatron-Turing NLG)是第一次由兩家科技巨頭合作推出超大AI模型。
其背后,雙方不僅組成了“超豪華”硬件陣容,在算法上也有融合。強強聯合成為超大AI模型落地的一種新方式,
國外巨頭開啟先例,那么國內公司的現狀又是如何呢?其實有機構已經邁出合作的第一步。
諸如浪潮的“源1.0”,和當初的“威震天”一樣,也是由硬件廠商主導開發的超大規模自然語言模型。
浪潮透露,實際上9月28日的發布會上,他們邀請了國內的學者和數家科技公司共同探討未來“源1.0”合作的可能性。
在產業界,浪潮早就提出了“元腦計劃”的生態聯盟,“源1.0”未來將向元腦生態社區內所有開發者開放API,所有加入生態的AI技術公司都可以利用“源1.0”進行二次開發,從而制造出更強大的功能。
國內超大規模自然語言模型合作的時代正在開啟。
合作開發巨量模型能帶來什么?李飛飛等知名學者已經給出答案:當數據規模和參數規模大到一定程度時,量變最終能產生質變,GPT-3就是先例。
如今大模型越來越多,但未來關鍵還在于如何縱橫捭闔,打造屬于一套開放合作體系,讓所有技術公司群策群力。
而AI巨量模型在這樣的生態體系下會帶來怎樣的變化,在“源1.0”等一大批模型開放后,應該很快就能看見。