













聊一聊大數據計算框架
前 言
近年來,隨著5G時代的到來以及物聯網和云計算的迅猛發展,人類社會逐漸步入了大數據時代。所謂大數據,是指所涉及的數據量規模巨大,無法通過人工在合理時間內達到截取、管理、處理并整理成為人類所能解讀的信息。大數據在帶來發展機遇的同時,也帶來了新的挑戰,催生了新技術的發展和舊技術的革新。例如,不斷增長的數據規模和數據的動態快速產生要求必須采用分布式計算框架才能實現與之匹配的吞吐和實時性。
1.大數據計算基本概念
1.1 離線計算
大數據離線計算技術應用于靜態數據的離線計算和處理,框架設計的初衷是為了解決大規模、非實時數據計算,更加關注整個計算框架的吞吐量。離線計算的數據量大且計算周期長,是在大量數據基礎上進行復雜的批量運算。離線計算的數據是不再會發生變化,通常離線計算的任務都是定時的,使用場景一般式對時效性要求比較低的。
1.2 實時流式計算
實時流式計算,或者是實時計算,流式計算,在大數據領域都是差不多的概念。那么,到底什么是實時流式計算呢?谷歌大神Tyler Akidau在《the-world-beyond-batch-streaming-101》一文中提到過實時流式計算的三個特征:無限數據、無界數據處理、低延遲:
- 無限數據:指的是一種不斷增長的,基本上無限的數據集,這些通常被稱為“流數據”,而與之相對的是有限的數據集。
- 無界數據處理:是一種持續的數據處理模式,能夠通過處理引擎重復的去處理上面的無限數據,是能夠突破有限數據處理引擎的瓶頸。
- 低延遲:延遲是指數據從進入系統到流出系統所用的時間,實時流式計算業務對延遲有較高要求,延遲越低,越能保證數據的實時性和有效性。
2.離線計算框架:大數據的主場
2.1 MapReduce計算框架
Hadoop是一個分布式系統架構,由Apache基金會所開發,其核心主要包括兩個組件:HDFS和MapReduce,前者為海量存儲提供了存儲,而后者為海量的數據提供了計算。這里我們主要關注MapReduce。以下資料來源于Hadoop的官方說明文檔和論文。
MapReduce是一個使用簡易的軟件框架,基于它寫出來的應用程序能夠運行在由上千個商用機器組成的大型集群上,并以一種可靠容錯的方式并行處理上T級別的數據集。將計算過程分為兩個階段,Map和Reduce,Map階段并行處理輸入的數據,Reduce階段對Map結果進行匯總。
一個MapReduce作業通常會把輸入的數據集切分為若干獨立的數據塊,由Map任務以完全并行的方式處理它們。框架會對Map的輸出先進行排序,然后把結果輸入給Reduce任務。通常作業的輸入和輸出都會被存儲在文件系統中。整個框架負責任務的調度和監控,以及重新執行已經失敗的任務。
通常,MapReduce框架和分布式文件系統是運行在一組相同的節點上的,也就是說,計算節點和存儲節點通常在一起。這種配置允許框架在那些已經存好數據的節點上高效地調度任務,這可以使整個集群的網絡帶寬被非常高效地利用。
MapReduce框架由一個單獨的master JobTracker 和每個集群節點一個slave TaskTracker共同組成。master負責調度構成一個作業的所有任務,這些任務分布在不同的slave上,master監控它們的執行,重新執行已經失敗的任務。而slave僅負責執行由master指派的任務。
應用程序至少應該指明輸入/輸出的路徑,并通過實現合適的接口或抽象類提供map和reduce函數。再加上其他作業的參數,就構成了作業配置。然后,Hadoop的Job Client提交作業和配置信息給JobTracker,后者負責分發這些軟件和配置信息給slave、調度任務并監控它們的執行,同時提供狀態和診斷信息給Job Client。
MapReduce框架運轉在
應用程序通常會通過提供map和reduce來實現 Mapper和Reducer接口,它們組成作業的核心。map函數接受一個鍵值對,產生一組中間鍵值對。MapReduce框架會將map函數產生的中間鍵值對中鍵相同的值傳遞給一個reduce函數。reduce函數接受一個鍵,以及相關的一組值,將這組值進行合并產生一組規模更小的值。如圖1所示,MapReduce的工作流程中,一切都是從最上方的user program開始的,user program鏈接了MapReduce庫,實現了最基本的Map函數和Reduce函數。圖中執行的順序都用數字標記了。
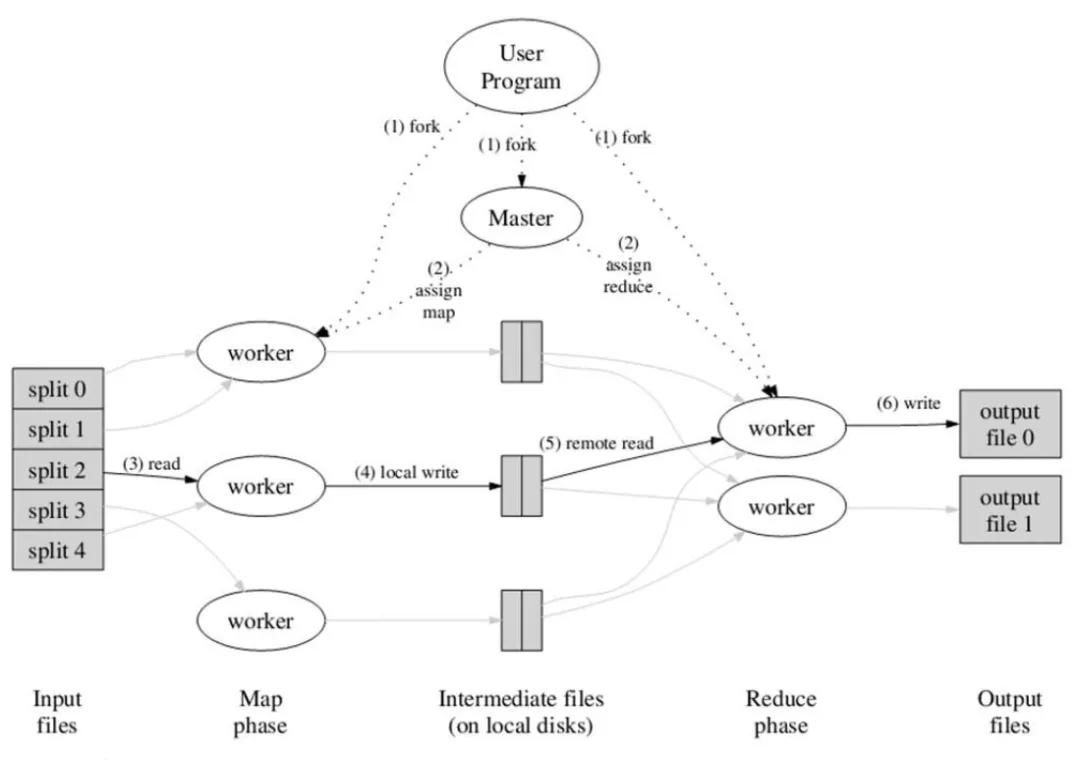
圖1 MapReduce的執行流程
2.2 Spark計算框架
Spark基于MapReduce算法實現的離線計算,擁有Hadoop MapReduce所具有的優點;但不同于MapReduce的是Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的Map Reduce的算法。
Spark中一個主要的結構是RDD(Resilient Distributed Datasets),這是一種只讀的數據劃分,并且可以在丟失之后重建。它利用了Lineage的概念實現容錯,如果一個RDD丟失了,那么有足夠的信息支持RDD重建。RDD可以被認為是提供了一種高度限制的共享內存,但是這些限制可以使得自動容錯的開支變得很低。RDD使用Lineage的容錯機制,即每一個RDD都包含關于它是如何從其他RDD變換過來的以及如何重建某一塊數據的信息。RDD僅支持粗顆粒度變換,即僅記錄在單個塊上執行的單個操作,然后創建某個RDD的變換序列存儲下來,當數據丟失時,我們可以用變換序列來重新計算,恢復丟失的數據,以達到容錯的目的。
Spark中的應用程序稱為驅動程序,這些驅動程序可實現在單一節點上執行的操作或在一組節點上并行執行的操作。驅動程序可以在數據集上執行兩種類型的操作:動作和轉換。動作會在數據集上執行一個計算,并向驅動程序返回一個值;而轉換會從現有數據集中創建一個新的數據集。動作的示例包括執行一個Reduce操作以及在數據集上進行迭代。轉換示例包括Map操作和Cache操作。
與Hadoop類似,Spark支持單節點集群或多節點集群。對于多節點操作,Spark依賴于Mesos集群管理器。Mesos為分布式應用程序的資源共享和隔離提供了一個有效平臺,參考圖2。
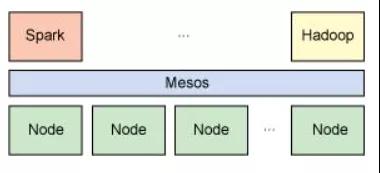
圖2 Spark 依賴于Mesos集群管理器
2.3 Dryad計算框架
Dryad是構建微軟云計算基礎設施的核心技術。編程模型相比MapReduce更具一般性——用有向無環圖(DAG)描述任務的執行,其中用戶指定的程序是DAG圖的節點,數據傳輸的通道是邊,可通過文件、共享內存或者傳輸控制協議(TCP)通道來傳遞數據,任務相當于圖的生成器,可以合成任何圖,甚至在執行的過程中這些圖也可以發生變化,以響應計算過程中發生的事件。圖3給出了整個任務的處理流程。Dryad在容錯方面支持良好,底層的數據存儲支持數據備份;在任務調度方面,Dryad的適用性更廣,不僅適用于云計算,在多核和多處理器以及異構集群上同樣有良好的性能;在擴展性方面,可伸縮于各種規模的集群計算平臺,從單機多核計算機到由多臺計算機組成的集群,甚至擁有數千臺計算機的數據中心。Microsoft借助Dryad,在大數據處理方面也形成了完整的軟件棧,部署了分布式存系統Cosmos,提供DryadLINQ編程語言,使普通程序員可以輕易進行大規模的分布式計算。

圖3 Dyrad計算框架的任務處理流程
3.實時流計算框架:大數據的未來
如果遇到時效性更敏感的業務需求,我們需要用到哪些實時計算引擎?目前有很多專業的實時流計算框架,較為知名的包括Apache Storm、Spark Streaming、LinkIn Samza、Apache Flink和Google MillWheel等,但是其中最主流的無疑是Storm、Spark Streaming、Flink和Samza。
3.1 Storm計算框架
Hadoop提供了Map和Reduce原語,使得對數據進行批處理變得非常簡單和優美。同樣,Storm也對數據的實時計算提供了簡單的Spout和Bolt原語。Storm集群表面上看和Hadoop集群非常像,但Hadoop上面運行的是MapReduce的Job,而Storm上面運行的是Topology,它們非常不一樣,比如一個MapReduce Job最終會結束,而一個Storm Topology永遠運行。Storm的集群架構如圖4所示。
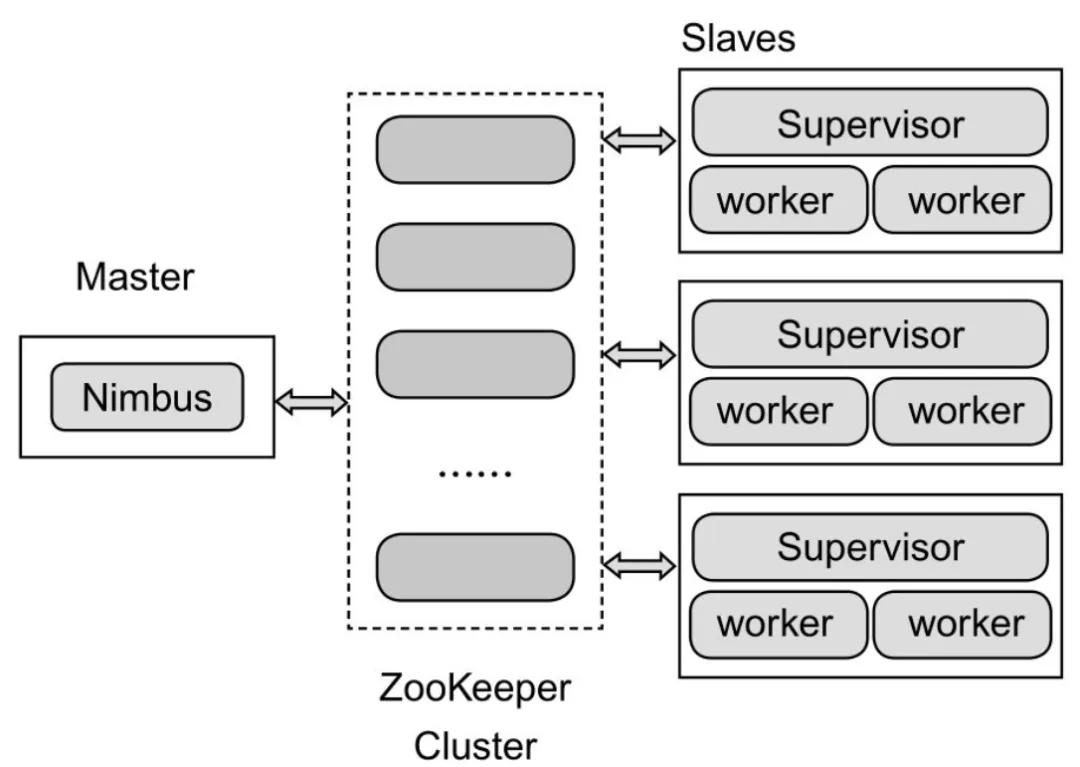
圖4 Storm的集群架構
在應用Storm過程中會碰見Topology、Tuple、Spout、Bolt、流和流分組這些概念。其中Topology是一個實時應用程序,Tuple是處理的基本消息單元,Spout是Topology的流的來源,是一個Topology中產生源數據流的組件,Topology中的所有處理邏輯都在Bolt中完成。一個流由無數個元組序列構成,這些元組并行、分布式的被創建和執行,流分組是用來定義一個Stream應該如何分配數據給Bolts上的多個任務。
早期的Storm無法提供exactly once的語義支持,后期Storm引入了Trident高級原語,提供了exactly once的語義支持。然后提出了流計算中的反壓概念,指的是Storm中的一個拓撲處理數據的速度小于數據流入的速度時的處理機制,通常來說,反壓出現的時候,數據會迅速累積,如果處理不當,會導致資源耗盡甚至任務崩潰。這在流處理過程中非常常見,通常是由于源頭數據量突然急劇增加所導致的,比如電商的大促、節日活動等。新的Storm自動反壓機制通過監控Bolt中的接收隊列的情況來實現,當超過高水位值時,專門的線程會將反壓信息寫到ZooKeeper, ZooKeeper上的Watch會通知該拓撲的所有Worker都進入反壓狀態,最后Spout降低Tuple發送的速度。
3.2 Spark Streaming計算框架
Spark Streaming是Spark核心API的擴展,用于處理實時數據流。Spark Streaming處理的數據源可以是Kafka,Flume,Twitter,HDFS或者Kinesis,這些數據可以使用map,reduce,join,window方法進行處轉換,還可以直接使用Spark內置的機器學習算法,圖算法包來處理數據。最終處理后的數據可以存入HDFS,Database或者Dashboard中,數據庫。相比于Storm原生的實時處理框架,Spark Streaming是基于微批處理,微批處理是一種組織獨立數據操作的方法,術語中的微,更具體的說來,就是指在內存中進行處理。術語中的批處理指的是Spark Streaming中數據處理的單位是一批而不是一條,Spark會等采集的源頭數據累積到設置的間隔條件后,對數據進行統一的批處理。這個間隔是Spark Streaming中的核心概念和關鍵參數,直接決定了Spark Streaming作業的數據處理延遲,當然也決定著數據處理的吞吐量和性能。
Spark Streaming提供了一個叫做DStream的抽象概念,表示一段連續的數據流。在Spark Streaming內部中,DStream實際上是由一系列連續的RDD組成的。每個RDD包含確定時間間隔內的數據,這些離散的RDD連在一起,共同組成了對應的DStream。Spark Streaming的架構如下圖5所示。

圖5 Spark Streaming的架構
3.3 Flink計算框架
Storm延遲低但是吞吐量小,Spark Streaming吞吐量大但是延遲高,那么是否有一種兼具低延遲和高吞吐量特點的流計算技術呢?答案是有的,就是Flink。實際上,Flink于2008年作為柏林理工大學的一個研究性項目誕生,但是直到2015年以后才開始逐步得到認可和接受,這和其自身的技術特點契合了大數據對低實時延遲、高吞吐、容錯、可靠性、靈活的窗口操作以及狀態管理等顯著特性分不開,當然也和實時數據越來越得到重視分不開。阿里巴巴啟動了Blink項目,目標是擴展、優化、完善Flink,使其能夠應用在阿里巴巴大規模實時計算場景。
Flink的整體結構如下圖6所示。部署:Flink 支持本地運行(IDE 中直接運行程序)、能在獨立集群(Standalone模式)或者在被 YARN、Mesos、K8s 管理的集群上運行,也能部署在云上。內核:Flink 的核心是分布式流式數據引擎,意味著數據以一次一個事件的形式被處理。API:包含了DataStream、DataSet、Table和SQL等API。庫:Flink還包括用于CEP(復雜事件處理)、機器學習、圖形處理等場景。
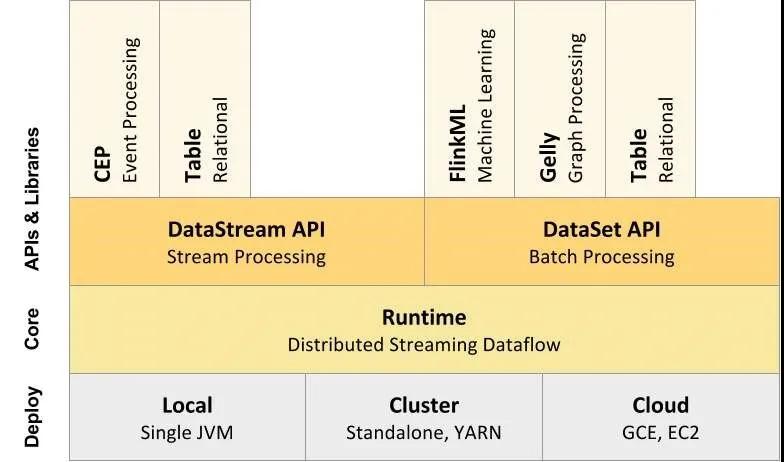
圖6 Flink的整體結構
Flink的容錯機制核心是分布式數據流和狀態的快照,為了保證失敗時從錯誤中恢復,因此需要對數據對齊。Flink采用了單機性能十分優異的RocksDB作為狀態的后端存儲,但單機是不可靠的,所以Flink還對將單機的狀態同步到HDFS上以保證狀態的可靠性。另外,對于從RocksDB到HDFS上checkpoint的同步,Flink也支持增量的方式,能夠非常好地提高checkpoint的效率。Flink相比其他流計算技術的一個重要特性是支持基于Event Time的窗口操作。但是Event Time來自于源頭系統,網絡延遲、分布式處理以及源頭系統等各種原因導致源頭數據的事件時間可能是亂序的,即發生晚的事件反而比發生早的事件來得早,或者說某些事件會遲到。Flink參考Google的Cloud Dataflow,引入水印的概念來解決和衡量這種亂序的問題。并且在實時計算的某些場景,需要撤回之前的計算結果進行,Flink提供了撤回機制。
Storm是通過監控process bolt中的接收隊列負載情況來處理反壓,如果超過高水位值,就將反壓信息寫到ZooKeeper,由ZooKeeper上的watch通知該拓撲的所有worker都進入反壓狀態,最后spout停止發送tuple來處理的。而Spark Streaming通過設置屬性“spark.streaming.backpressure.enabled”可以自動進行反壓處理,它會動態控制數據接收速率來適配集群數據處理能力。對于Flink來說,不需要進行任何的特殊設置,其本身的純數據流引擎可以非常優雅地處理反壓問題。
3.4 Samza計算框架
Samza是Linkedin開源的分布式流處理框架,其架構如圖8所示,由Kafka提供底層數據流,由YARN提供資源管理、任務分配等功能。圖7也給出了Samza的作業處理流程,即Samza客戶端負責將任務提交給YARN的資源管理器,后者分配相應的資源完成任務的執行。在每個容器中運行的流任務相對于Kafka是消息訂閱者,負責拉取消息并執行相應的邏輯。在可擴展性方 面,底層的Kafka通過Zookeeper實現了動態的集群水平擴展,可提供高吞吐、可水平擴展的消息隊列,YARN為Samza提供了分布式的環境和執行容器,因此也很容易擴展;在容錯性方面,如果服務器出現故障,Samza和YARN將一起進行任務的遷移、重啟和重新執行,YARN還能提供任務調度、執行狀態監控等功能;在數據可靠性方面,Samza 按照Kafka中的消息分區進行處理,分區內保證消息有序,分區間并發執行,Kafka將消息持久化到硬盤保證數據安全。另外,Samza還提供了對流數據狀態管理的支持。在需要記錄歷史數據的場景里,數據實時流動導致狀態管理難以實現,為此,Samza提供了一個內建的鍵值數據庫用來存儲歷史數據。
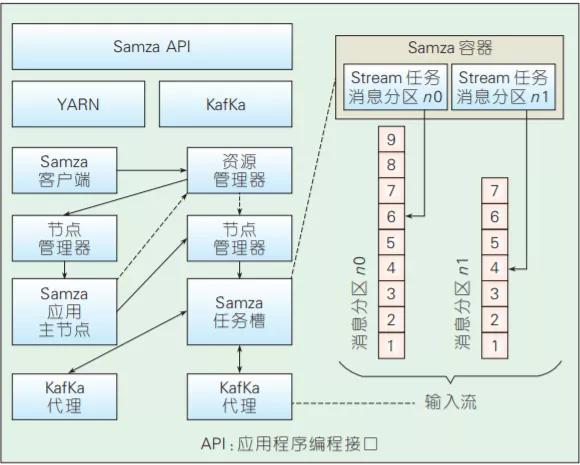
圖7 Samza的整體架構
4.總 結
大數據計算框架的應用推進了技術的發展和革新,目前業界在不斷提高大數據計算框架的吞吐量、實時性、可擴展性等特性以應對日益增長的數據量和數據處理需求,大數據計算框架依然是現在以及未來一段時間內的研究熱點。未來的發展趨勢是:隨著商業智能和計算廣告等領域的發展,更強調實時性的流計算框架將得到更加廣泛的關注。總之,應用的推動和技術的進步將會產生新的問題。作為大數據應用的核心,對于挖掘數據價值起著重要作用的計算框架將會面臨更多的挑戰,亟待解決。本文參考了一些文獻和網絡資源,他們的觀點和技術對本文做出的貢獻表示感謝。
參考文獻
[1] 李川,鄂海紅,宋美娜.基于Storm的實時計算框架的研究與應用[J].軟件,2014,35(10):16-20.
[2] https://izualzhy.cn/dataflow-reading
[3] https://juejin.im/post/5d49830cf265da03f3333b4c#heading-11
[4] Wenhong Tian, Yong Zhao, in Optimized Cloud Resource Management and Scheduling[M], 2015
[5] https://greeensy.github.io/2014/06/15/Batch-Computing/























