













MIT警告深度學習正在逼近計算極限,網友:放緩不失為一件好事
MIT 的一項研究認為,深度學習正在逼近算力極限。
深度學習需要大量數據和算力,這二者的發(fā)展是促進這一次人工智能浪潮的重要因素。但是,近期 MIT 的一項研究認為,深度學習正在逼近算力極限。
這項研究由 MIT、MIT-IBM Watson AI 實驗室、延世大學安德伍德國際學院和巴西利亞大學的研究人員開展,他們發(fā)現深度學習的進展「極大地依賴」算力增長。他們認為,深度學習要想繼續(xù)進步,需要更加計算高效的深度學習模型,這可以來自于對現有技術的更改,也可以是全新的方法。

論文鏈接:https://arxiv.org/pdf/2007.05558.pdf
該研究作者表示:「我們發(fā)現,深度學習計算成本高昂并非偶然,而是從設計之時就注定了。靈活性可以使深度學習很好地建模不同現象并超越專家模型,但也帶來了昂貴的算力成本。盡管如此,我們發(fā)現深度學習模型的實際計算負載要比理論極值擴展得更加迅速,這意味著可能出現顯著改進。」
深度學習是機器學習的子領域,其算法受到大腦結構和功能的啟發(fā)。這類算法——通常叫做人工神經網絡,包含函數(神經元),網絡層負責將信號傳遞給其他神經元。信號也就是網絡輸入數據的產物,它們在層與層之間流動,并緩慢地「調優(yōu)」網絡,從而調整每個連接的突觸強度(權重)。神經網絡最終通過提取數據集特征、識別跨樣本趨勢來學習執(zhí)行預測。

研究人員分析了 1058 篇來自 arXiv 等來源的論文,試圖理解深度學習性能和計算之間的聯系,尤其是圖像分類、目標檢測、問答、命名實體識別和機器翻譯領域。
他們執(zhí)行了兩項對算力要求的分析:
-
每個神經網絡遍歷(network pass)所需算力,或單次遍歷所需的浮點運算數;
-
訓練模型所用的硬件負載,即硬件算力,這里以處理器數量乘以計算速率和時間來進行計算。
研究作者表示,在使用算力幾乎相同的情況下,除了英德機器翻譯任務以外,在所有基準上都出現了「具備高度統(tǒng)計學意義」的曲線和「強大的解釋能力」。
尤其是,目標檢測、命名實體識別和機器翻譯在輸出結果改進相對較小的情況下硬件負載出現大幅增長,算力對模型在 ImageNet 基準數據集上的圖像分類準確率承擔了 43% 的貢獻。
研究人員估計,三年的算法改進等于算力的 10 倍增長。「我們的研究結果表明,在深度學習的多個領域中,訓練模型所取得的進展依賴于所用算力的大幅增長。另一種可能性是算法改進本身需要算力的補充。」
在研究過程中,研究人員還推斷了模型在不同理論基準上打破記錄所需的算力、經濟成本和環(huán)境成本。
據最樂觀的估計,降低 ImageNet 圖像分類誤差也需要 105 倍的算力增長。
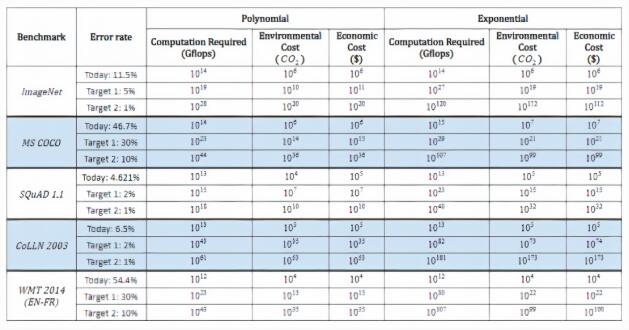
去年六月,機器之心發(fā)布的報告估計,華盛頓大學的 Grover 假新聞檢測模型訓練兩周所需成本為 2.5 萬美元。前不久發(fā)布的 OpenAI GPT-3 模型訓練成本飆升到 1200 萬美元,谷歌 BERT 的訓練成本約為 6,912 美元。
去年六月來自美國馬薩諸塞大學阿默斯特分校的研究者發(fā)現,訓練和搜索特定模型所需算力會排放 62.6 萬鎊二氧化碳,約等于美國汽車平均一生排放量的五倍。
「我們無法預測這些目標的計算要求…… 硬件、環(huán)境成本和金錢成本將會高昂到難以承受。以更經濟的方式達成目標需要更加高效的硬件和算法或其他改進。」
研究人員注意到,深度學習在算法層面上的改進有過先例。例如,谷歌 TPU、FPGA 和 ASIC 等硬件加速器的出現,以及通過網絡壓縮和加速技術降低計算復雜度。
研究人員還引用了神經架構搜索和元學習,它們利用優(yōu)化找出擅長解決某類問題的架構,進而試圖實現計算高效的方法。
OpenAI 的一項研究指出,自 2012 年以來,訓練 AI 模型達到 ImageNet 圖像分類任務相同性能所需要的算力每 16 個月減少 1/2。此外,谷歌 Transformer 架構超越了先前的 SOTA 模型 seq2seq(也由谷歌開發(fā)),它比 seq2seq 推出晚了三年,計算量是后者的 1/64。
研究人員在論文最后寫道:「深度學習模型所需算力的爆炸式增長結束了 AI 寒冬,并為更廣泛任務上的計算性能制定了新的基準。但是深度學習對于算力的巨大需求限制了以目前形式提升性能的路徑,特別是在這樣一個硬件性能放緩的時代。」
因此,研究人員認為,算力極限可能促使機器學習轉向比深度學習計算效率更高的新技術。
reddit 熱議
這一話題以及相應論文在 reddit 等社交網站上引發(fā)熱議,擁躉者有,但質疑聲也很多。
有網友表示,關于深度學習算法復雜性的討論雖未成為當前主流,但很快會成為焦點話題。發(fā)帖者也對這種說法表示認同,并認為過去幾年得益于計算能力的顯著提升,機器學習領域取得了諸多突破。盡管如此,人們可能會很快關注可持續(xù)性和算法效率。
與此同時,更多的網友對研究中的一些細節(jié)問題展開了討論。
下面這位網友對論文中的「硬件性能的提升正在放緩」這一說法提出了疑問:「事實真的如此嗎?特別是從 USD/TFLOPS 和 Watts/TFLOPS 的角度來看。」
發(fā)帖者也對這位網友的疑問進行了回復,他表示這似乎是作者的論點。論文作者在文中還寫道:「深度學習模型所需算力的爆炸式增長結束了 AI 寒冬,并為更廣泛任務上的計算性能制定了新的基準。」但遺憾的是,論文作者的這些說法并沒有提供參考文獻。
更有網友毫不客氣地表示:「雖然這是一個越來越重要的討論話題,但我并沒有從這項研究中看到任何『新』見解。事實上,自 2012 年以來,我們都清楚一些歷時 10-30 年之久的舊方法之所以依然能夠運行,主要還是得益于算力。」
在他看來,眾多深度學習方法面臨的計算限制是顯而易見的。可以想象到,如果有人將 GPT-3 的計算增加 100 倍,則會得到 GPT-4。現在,很多科研實驗室面臨著另一個更大的限制,受制于種種客觀因素,它們無法獲取更大的算力。
最后,有網友認為,無論是從理論基礎,還是社會影響等多方面來看,機器學習領域「放緩腳步」不失為一件好事。
















