Kubernetes和大數據:入門介紹
Kubernetes是什么?
在過去的幾年中,Kubernetes一直是DevOps和Data Science社區中令人興奮的話題。 它已經連續發展成為開發云原生應用程序的首選平臺之一。 由Google作為開放源代碼平臺構建的Kubernetes可以處理將容器調度到計算集群上的工作,并管理工作負載以確保它們按預期運行。
但是,有一個陷阱:這意味著什么? 當然,有可能對Kubernetes進行其他研究,但是假設大多數讀者已經對技術基礎有所了解,那么Internet上的許多文章都是用專業術語和復雜術語充斥的高級概述。
在這篇文章中,我們試圖提供對Kubernetes架構及其在大數據中的應用的易于理解的解釋,同時澄清繁瑣的術語。 但是,我們假設我們的讀者已經對應用程序開發和編程領域有所了解。 我們希望到本文結尾時,您已經對該主題有了更深入的了解,并準備進行更深入的研究。
什么是微服務?
為了了解Kubernetes的工作原理以及我們為什么需要它,我們需要研究微服務。 對于微服務,尚無公認的定義,但簡單地說,微服務是較小的,是執行特定任務的較大應用的分離組件。 這些組件通過REST API相互通信。 這種架構使應用程序可擴展和可維護。 這也使開發團隊的工作效率更高,因為每個團隊都可以專注于自己的組件,而不會干擾應用程序的其他部分。
由于每個組件或多或少地獨立于應用程序的其他部分運行,因此有必要擁有可以管理和集成所有這些組件的基礎架構。 該基礎結構將需要保證在生產中部署時所有組件都能正常工作。
容器與虛擬機(VM)
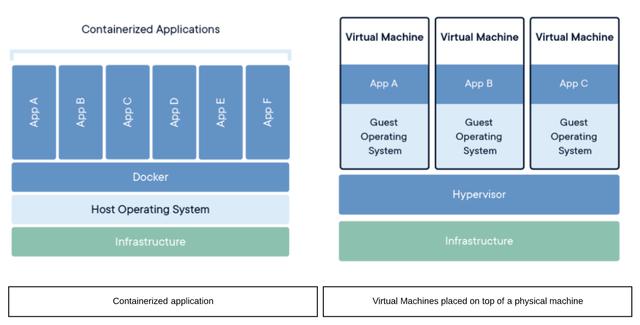
每個微服務都有其依賴性,并且需要其自己的環境或虛擬機(VM)來承載它們。 您可以將VM視為計算機中的一個"巨型"進程,它的存儲量,進程和網絡功能與計算機分開。 換句話說,VM是物理硬件之上的軟件加硬件抽象層,用于模擬完整的操作系統。
可以想象,虛擬機是一個消耗資源的過程,耗盡了計算機的CPU,內存和存儲空間。 如果您的組件很小(很常見),那么您的VM中會剩下大量未充分利用的資源。 這使得托管在VM上的大多數基于微服務的應用程序維護起來既費時又費錢。

容器,就像現實生活中的容器一樣,將東西容納在里面。 容器打包了運行微服務所需的代碼,系統庫和設置,從而使開發人員更容易知道他們的應用程序將運行,無論其部署在何處。 大多數可用于生產環境的應用程序由多個容器組成,每個容器運行應用程序的單獨部分,同時共享操作系統(OS)內核。 與VM不同,容器僅需最少的資源即可在生產中可靠運行。 因此,與VM相比,容器被認為是輕量級的,獨立的和可移植的。
深入Kubernetes
我們希望您仍然在旅途中! 經歷了容器和微服務之后,了解Kubernetes應該會更容易。 在生產環境中,您必須管理容器化應用程序的生命周期,以確保沒有停機時間并有效利用系統資源。 Kubernetes提供了一個框架來自動彈性地管理分布式系統中的所有這些操作。 簡而言之,它是集群的操作系統。 群集由網絡中連接在一起的多個虛擬機或真實機組成。 正式而言,這是在官方網站上定義Kubernetes的方式:
" Kubernetes是一個可移植的,可擴展的開源平臺,用于管理容器化的工作負載和服務,可促進聲明性配置和自動化。 它擁有一個龐大且快速增長的生態系統。 Kubernetes的服務,支持和工具廣泛可用。"
Kubernetes是一個可擴展的系統。 它通過利用模塊化架構來實現可伸縮性。 這意味著您的應用程序的每個服務都由定義的API和負載平衡器分隔。 負載平衡器是一種機制,系統可以確保每個組件(無論是服務器還是服務)都在利用最大可用容量來執行其操作。 擴展應用程序僅僅是更改配置文件中復制容器的數量的問題,或者您可以簡單地啟用自動擴展功能。 這特別方便,因為將系統擴展的復雜性委托給Kubernetes。 自動擴展是通過諸如內存消耗,CPU負載等實時指標來完成的。在用戶端,Kubernetes會自動在群集中的復制容器之間平均分配流量,從而保持部署的穩定。
Kubernetes可以實現更好的硬件利用率。 生產就緒型應用程序通常依賴于必須在多臺服務器之間部署,配置和管理的大量組件。 如上所述,Kubernetes大大簡化了根據資源可用性標準(處理器,內存等)確定必須在其中部署某個組件的服務器的任務。
Kubernetes的另一個很棒的功能是它可以自我修復,這意味著它可以自動從故障中恢復,例如重新生成崩潰的容器。 例如,如果容器由于某種原因而失敗,Kubernetes將自動比較正在運行的容器的數量與配置文件中定義的數量,并根據需要重新啟動新的容器,以確保最小的停機時間。
現在我們已經解決了這個問題,現在該看看構成Kubernetes的主要元素了。 我們將首先解釋下層的Kubernetes Worker節點,然后解釋上層的Kubernetes Master。 工人節點是運行容器的奴才,而主節點是監督系統的總部。
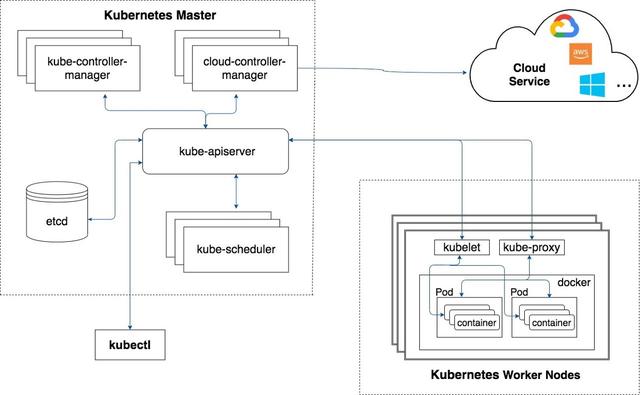
Kubernetes工作節點組件
Kubernetes工作者節點(也稱為Kubernetes奴才)包含與Kubernetes Master(主要是kube-apiserver)通信并運行容器化應用程序的所有必需組件。
Docker容器運行時Kubernetes需要一個容器運行時才能進行編排。 Docker是一個常見的選擇,但也可以使用其他替代方案,例如CRI-O和Frakti。 Docker是一個用于構建,交付和運行容器化應用程序的平臺。 Docker在每個工作程序節點上運行,并負責運行容器,下載容器映像和管理容器環境。
PodA pod包含一個或多個緊密耦合的容器(例如,一個用于后端服務器的容器,另一個用于輔助服務的容器,例如上載文件,生成分析報告,收集數據等)。 這些容器共享相同的網絡IP地址,端口空間甚至卷(存儲)。 此共享卷具有與容器相同的生命周期,這意味著如果除去容器,該卷將消失。 但是,Kubernetes用戶可以設置持久卷以將其與Pod分離。 然后,卸下吊艙后,已安裝的卷仍將存在。
kube-proxy kube-proxy負責路由每個節點上的傳入或傳出網絡流量。 kube-proxy還是一個負載均衡器,可跨容器分布傳入的網絡流量。
kubelet kubelet從kube-apiserver獲取一組pod配置,并確保定義的容器正常運行。
Kubernetes主組件
Kubernetes Master管理Kubernetes集群并協調工作節點。 這是大多數管理任務的主要切入點。
etcd etcd是Kubernetes集群的重要組成部分。 它是一個鍵值存儲,用于共享和復制所有配置,狀態和其他群集數據。
kube-apiserver幾乎所有Kubernetes組件之間的通信以及控制集群的用戶命令都是使用REST API調用完成的。 kube-apiserver負責處理所有這些API調用。
kube-scheduler kube-scheduler是Kubernetes中的默認調度程序,可為新創建的Pod查找最佳工作節點。 如果需要,您還可以創建自己的自定義計劃組件。
kubectl kubectl是一個客戶端命令行工具,用于通過kube-apiserver通信和控制Kubernetes集群。
kube-controller-manager kube-controller-manager是一個守護程序(后臺進程),它嵌入了一組Kubernetes核心功能控制器,例如端點,名稱空間,復制,服務帳戶等。
cloud-controller-managercloud-controller-manager運行與基礎云服務提供商進行交互的控制器。 這使云提供商可以將Kubernetes集成到他們正在開發的云基礎架構中。 諸如Google Cloud,AWS和Azure之類的云提供商已經提供了其Kubernetes服務版本。
Kubernetes大數據
開發大數據解決方案的主要挑戰之一是定義正確的體系結構,以在生產系統中部署大數據軟件。 顧名思義,大數據系統是處理在線和批處理數據的指數級增長的大規模應用程序。 因此,需要一個可靠,可擴展,安全且易于管理的平臺來彌合要處理的大量數據,軟件應用程序和底層基礎結構(內部部署或基于云)之間的差距。
Kubernetes是在大型基礎架構中部署應用程序的優秀選擇之一。 使用Kubernetes,可以處理需要的所有在線和批處理工作負載,例如分析和機器學習應用程序。
在大數據世界中,Apache Hadoop一直是用于部署可擴展和分布式應用程序的主導框架。 但是,云計算和云原生應用程序的興起削弱了Hadoop的普及程度(盡管像AWS和Cloudera這樣的大多數云供應商仍提供Hadoop服務)。 Hadoop基本上提供了三個主要功能:資源管理器(YARN),數據存儲層(HDFS)和計算范例(MapReduce)。 所有這三個組件都已被更現代的技術所取代,例如用于資源管理的Kubernetes,用于存儲的Amazon S3和用于分布式計算的Spark / Flink / Dask。 此外,大多數云供應商都提供自己的專有計算解決方案。
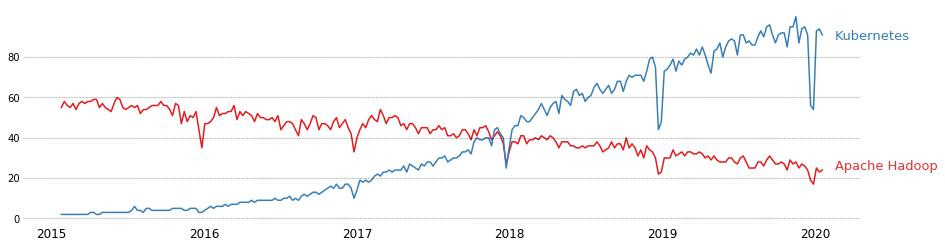
我們首先需要澄清的是,Hadoop或大多數其他大數據堆棧與Kubernetes之間沒有"一對一"的關系。 實際上,人們可以在Kubernetes上部署Hadoop。 但是,Hadoop是在與當今時代截然不同的環境中構建和成熟的。 它是在網絡延遲成為主要問題的時代構建的。 企業被迫擁有內部數據中心,以避免為了數據科學和分析目的而不得不移動大量數據。 話雖如此,希望擁有自己的數據中心的大型企業將繼續使用Hadoop,但是由于更好的替代方案,采用率可能仍然很低。
如今,在云存儲提供商和云原生解決方案的主導下,企業內部進行了大量的計算操作。 此外,許多公司選擇在內部部署自己的私有云。 由于這些原因,Hadoop,HDFS和其他類似產品已經失去了對更新,更靈活,最終更優秀的技術(例如Kubernetes)的吸引力。
大數據應用程序是使用Kubernetes架構的良好候選者,因為Kubernetes集群具有可伸縮性和可擴展性。 最近發生了一些重大運動,將Kubernetes用于大數據。 例如,Apache Spark是處理大量數據的繁重運算的"海報子",它正在努力添加本機Kubernetes調度程序以運行Spark作業。 谷歌最近宣布,他們將用Kubernetes替換YARN,以安排其Spark工作。 電子商務巨頭eBay已部署了數千個Kubernetes集群來管理其Hadoop AI / ML管道。
那么Kubernetes為什么適合大數據應用呢? 以兩個Apache Spark作業A和B在計算機上進行一些數據聚合為例,并說一個共享依賴項已從版本X更新到Y,但是作業A需要版本X,而作業B需要版本Y。 ,作業A將無法運行。
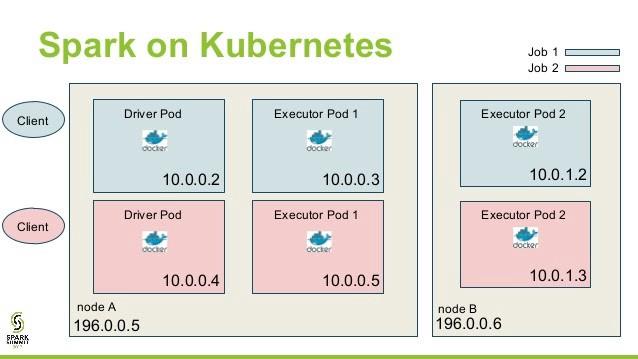
在Kubernetes集群中,每個節點將在其各自的驅動程序和執行程序容器上運行隔離的Spark作業。 這種設置將避免依賴項互相干擾,同時仍保持并行化。
在部署大數據堆棧時,Kubernetes仍然有一些主要的痛點。 例如,由于容器是為短壽命的無狀態應用程序設計的,因此對于在Kubernetes上運行的大數據應用程序來說,缺乏可以在不同作業之間共享的持久性存儲是一個主要問題。 其他主要問題包括調度(Spark的上述實施仍處于試驗階段),安全性和網絡連接。
考慮以下情況:節點A運行的作業需要讀取群集中位于節點B上的數據節點上HDFS中存儲的數據。 這將大大增加網絡延遲,因為現在不像YARN,而是通過此隔離系統的網絡發送數據以進行計算。 盡管嘗試解決這些數據局部性問題,但Kubernetes仍然有很長的路要走,才能真正成為部署大數據應用程序的可行和現實的選擇。
盡管如此,開源社區仍在不懈地致力于解決這些問題,以使Kubernetes成為部署大數據應用程序的實用選擇。 每年,Kubernetes由于其固有的優勢(如彈性,可伸縮性和資源利用率),越來越接近成為分布式大數據應用程序的實際平臺。
在本文中,我們僅介紹了Kubernetes的表面,功能和在大數據中的應用。 作為一個不斷發展的平臺,Kubernetes將繼續發展成為一種應用于眾多技術領域的技術,尤其是在大數據和機器學習中。 如果您想了解有關Kubernetes的更多信息,請在"外部鏈接"部分下找到一些有關主題的建議。 我們希望您喜歡我們有關Kubernetes的文章,并且讀起來很有趣。