詳解大數據開發-HDFS入門
今天帶來的是全新的章節,大數據開發-HDFS,作為Hadoop生態系統的一個重要組成部分,其存在不可或缺,基礎的才是最重要的,而HDFS就是這樣一個存在。下面就開始HDFS的學習。
一、 HDFS介紹
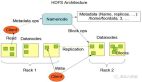
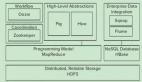
HDFS(Hadoop Distributed File System)是hadoop生態系統的一個重要組成部分,是Hadoop中的的存儲組件,在整個Hadoop中的地位非同一般,也是最基礎的一部分,因為它涉及到數據存儲,MapReduce等計算模型都要依賴于存儲在HDFS中的數據。HDFS是一個分布式文件系統,以流式數據訪問模式存儲超大文件,將數據分塊存儲到一個商業硬件集群內的不同機器上。HDFS在最開始是作為Apache Nutch搜索引擎項目的基礎架構而開發的。HDFS是Apache Hadoop Core項目的一部分。
分布式文件系統解決的問題就是大數據存儲。它們是橫跨在多臺計算機上的存儲系統。分布式文件系統在大數據時代有著廣泛的應用前景,它們為存儲和處理超大規模數據提供所需的擴展能力。
二、HDFS設計理念
硬件出現故障是常態,而HDFS由成百上千的服務器組成,每一個組成部分都有可能出現故障。因此故障的檢測和自動快速恢復是HDFS的核心架構目標。與一般的應用不同,HDFS上的應用主要是以流式讀取數據HDFS被設計成適合批量處理,而不是用戶交互式的。相較于數據訪問的反應時間,實際上更注重數據訪問的高吞吐量。典型的 HDFS文件大小是GB到TB的級別。所以,HDFS被調整成支持大文件。它應該提供很高的聚合數據帶寬,一個集群中支持數百個節點,一個集群中還應該支持千萬級別的文件。
大部分 HDFS 應用對文件要求的是 write-one-read-many訪問模型。一個文件一旦創建、寫入、關閉之后就不需要修改了。這一假設簡化了數據一致性問題,使高吞吐量的數據訪問成為可能。
移動計算的代價比之移動數據的代價低。一個應用請求的計算,離它操作的數據越近就越高效,這在數據達到海量級別的時候更是如此。將計算移動到數據附近,比之將數據移動到應用所在顯然更好。
在異構的硬件和軟件平臺上的可移植性,這將推動需要大數據集的應用更廣泛地采用 HDFS 作為平臺。
三、概念介紹
以下有幾個較為重要的概念需要介紹下
(1)超大文件。目前的hadoop集群能夠存儲幾百TB甚至PB級的數據。
(2)流式數據訪問。HDFS的訪問模式是:一次寫入,多次讀取,更加關注的是讀取整個數據集的整體時間。
(3)商用硬件。HDFS集群的設備不需要多么昂貴和特殊,只要是一些日常使用的普通硬件即可,正因為如此,hdfs節點故障的可能性還是很高的,所以必須要有機制來處理這種單點故障,保證數據的可靠。
(4)不支持低時間延遲的數據訪問。hdfs關心的是高數據吞吐量,不適合那些要求低時間延遲數據訪問的應用。
(5)單用戶寫入,不支持任意修改。hdfs的數據以讀為主,只支持單個寫入者,并且寫操作總是以添加的形式在文末追加,不支持在任意位置進行修改。
四、為什么我們需要HDFS?
1.數據量巨大,磁盤開始很糾結的處理我們需要的海量信息。所以需要文件系統有大規模數據分布存儲能力。
2.讀取一塊磁盤的所有數據需要很長時間,寫入更是需要更長時間(寫入時間一般是讀取時間的3倍)即使有文件為1ZB,或者小點10EB時,這樣的磁盤也無法做到隨讀隨取。所以需要文件系統有高并發訪問能力。
3.當數據集的大小超過一臺獨立物理計算機的存儲能力時,就有必要對它進行分區并存儲到若干臺單獨的計算機上。
4.從概念圖上看,分布化的文件系統會因為分布后的結構不完整,導致系統復雜度加大,并且引入的網絡編程,同樣導致分布式文件系統更加復雜。所以需要強大的容錯能力。
5.HDFS解決以上方案是分片冗余,本地校驗,需要數據塊存儲模式數據冗余式存儲,直接將多份的分片文件交給分片后的存儲服務器去校驗。冗余后的分片文件還有個額外功能,只要冗余的分片文件中有一份是完整的,經過多次協同調整后,其他分片文件也將完整。
經過協調校驗,無論是傳輸錯誤,I/O錯誤,還是個別服務器宕機,整個系統里的文件是完整的。
6.分布后的文件系統有個無法回避的問題,因為文件不在一個磁盤導致讀取訪問操作的延時,這個是HDFS現在遇到的主要問題。
現階段,HDFS的配置是按照高數據吞吐量優化的,可能會以高時間延時為代價。但萬幸的是,HDFS是具有很高彈性,可以針對具體應用再優化。
總結就是:可以實現負載均衡、提高響應效率,因為多個服務器可以同時服務,提高了效率。
以上就是本期的所有內容了,Hadoop在大數據開發的學習當中,占據著相當重要的地位,相關知識點也會比較多,所以關于HDFS一定要好好理解,以免在后面學習Hadoop造成更多的困難。