卷積神經網絡中的參數共享/權重復制
參數共享或權重復制是深度學習中經常被忽略的領域。但是了解這個簡單的概念有助于更廣泛地理解卷積神經網絡的內部。卷積神經網絡(cnn)能夠使那些通過網絡饋送的圖像在進行仿射變換時具有不變性。 這個特點提供了識別偏移圖案、識別傾斜或輕微扭曲的圖像的能力。
仿射不變性的這些特征是由于CNN架構的三個主要屬性而引入的。
- 局部感受領域
- 權值共享(參數共享)
- 空間的采樣
在本文中,我們將探索權值共享,并了解它們的用途以及它們在CNN架構中的優勢。本文針對從事機器學習或更具體地說是深度學習的各個層次的人。
介紹
讓我們首先在腦海中演示CNN中的一個卷積層。。
CNN中的卷積層(conv層)包含一組單元,這些單元也可以稱為神經元。
conv層還包括層內的幾個過濾器,這是一個預定義的超參數。
一個層內過濾器的數量表示激活/特征映射的輸出量的深度維度,該映射由conv層創建,作為下一層的輸入。
每一個濾波器都有一個設定的寬度和高度,對應于層內單個單元的局部接收場。作用于輸入數據的濾波器產生一個卷積層的輸出,即特征映射。
在CNN的訓練階段,可以學習過濾器中的權重值。卷卷積層的輸出維數有一個深度分量,如果我們對輸出的每一段進行分割,我們將得到一個二維平面的特征映射。在單個二維平面上使用的過濾器包含一個權重,該權重在同一平面上使用的所有過濾器之間共享。
這樣做的好處是,我們在輸入數據的另一部分與輸入數據的另一部分保持相同的特征檢測器。
卷積層的輸出是一組特征圖,其中每個特征圖是單元內固定權重參數與輸入數據之間的卷積運算結果。
卷積神經網絡層的一個基本特征是它的特征映射能夠反映對輸入圖像所做的任何仿射變換,而這些仿射變換是通過輸入層輸入的。
因此,對輸入數據進行任何偏移、傾斜或定向,特征映射都將提供一個輸出,該輸出將根據輸入數據所受的量進行偏移、傾斜或定向。
將理論付諸實踐
本節的目的是揭示卷積神經網絡中發生的權值共享的好處。
我們將在兩種流行的CNN架構(LeNet和AlexNet)的第一個卷積層中得出不同權值共享和權值共享的可訓練權重的數量。
以下是要采取的步驟:·
1. 獲取conv 層的輸出寬度
(輸入大小的寬度-過濾器大小+(2 * Padding)/步幅)+1 =卷積層的輸出寬度
- 計算conv層中神經元/單位的數量
- 計算沒有使用權值共享的訓練參數的數量(包括偏差)
- 計算使用權值共享的訓練參數(包括偏差)的數量
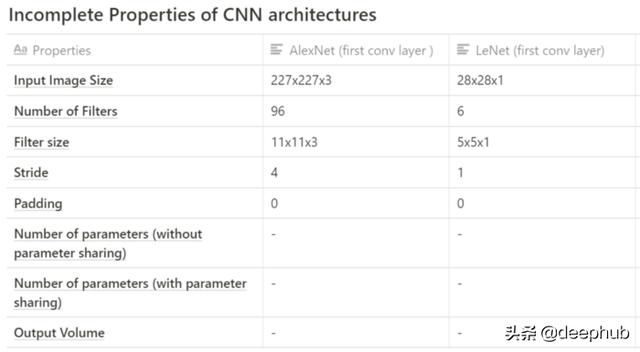
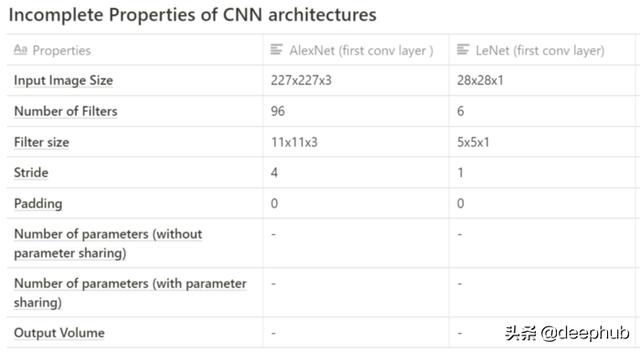
下表描述了來自AlexNet和LeNet CNN架構的信息,這些信息將用于得出卷積層內訓練參數/權重的數量。
AlexNet
- conv層的輸出寬度:=((227-11)/ 4)+1= 55(conv層輸出寬度)
- conv層中神經元/單位的數量=輸出高度*輸出寬度*特征圖的數量= 55*55*96(轉換輸出量)= 290,400單位
- conv層內的訓練參數或權重數(不使用權值共享)= 290400 *((11* 11 * 3)+ 1偏差)=105,415,600
- 使用權值共享的訓練參數或權重的數量= 96 *((11 * 11 *3)+1個偏差)= 34944
LeNet
- conv層的輸出寬度:=(((28–5)/ 1)+1= 24(conv層輸出寬度)
- conv層中神經元/單位的數量=輸出高度*輸出寬度*特征圖的數量= 24*24*6(轉換輸出量)= 3,456單位
- conv層內的訓練參數或權重數(不使用權值共享)= 3456 *((5 * 5 * 1)+ 1偏差)=89,856
- 使用權值共享的訓練參數或權重的數量= 6 *((5 * 5 * 1)+1偏差)= 156
總結
顯然,通過參數共享,我們可以減少conv層中的權重數量。
參數共享用于網絡中的所有conv層。
參數共享減少了訓練時間; 這是減少反向傳播過程中必須進行的權重更新次數的直接好處。
重申一下,當根據過濾器與卷積層中某個平面內某個單元的輸入數據之間的卷積結果生成特征圖時就會產生參數共享。 此層平面內的所有單元共享相同的權重;因此稱為權重/參數共享。