幾行代碼實現強化學習
在過去的一年中,強化學習已經取得了重大進步,最新技術每兩個月發布一次。 我們已經看到AlphaGo擊敗了世界冠軍圍棋選手Ke Jie,Multi-Agents玩了捉迷藏,甚至AlphaStar在星際爭霸中也擁有自己的實力。
實施這些算法可能會非常具有挑戰性,因為它需要對深度學習和強化學習都有很好的理解。 本文的目的是讓您快速使用一些簡潔的程序包,以便您可以輕松地開始學習強化學習。
有關如何實施SOTA深度強化學習算法的深入教程,請參閱此內容。 強烈推薦您仔細閱讀!

一、環境
在開始實現這些算法之前,我們首先需要創建一個工作環境,即游戲。 對于算法而言,重要的是要了解什么是動作和觀察空間。 為此,我們將介紹幾個可用于選擇有趣環境的軟件包。
1. Gym
Gym是用于開發和比較強化學習算法的工具包。 它通常用于實驗和研究目的,因為它提供了一個易于使用的界面來處理環境。
只需使用以下命令安裝軟件包:
- pip install gym
之后,您可以使用以下代碼創建環境:
- import gym
- env = gym.make(‘CartPole-v0’)
在 CartPole 環境中,您的任務是防止頭連接到推車的電線桿掉落。
env變量包含有關環境(游戲)的信息。 要了解CartPole的操作空間是什么,只需運行env.action_space即可產生Discrete(2)。 這意味著可能有兩個離散的動作。 要查看觀察空間,請運行env.observation_space,它產生Box(4)。 此框代表 n(4)個封閉間隔的笛卡爾積。
要渲染游戲,請運行以下代碼:
- import gym
- env = gym.make('CartPole-v0')
- obs = env.reset()
- while True:
- action = env.action_space.sample()
- obs, rewards, done, info = env.step(action)
- env.render()
- if done:
- break
我們可以看到,如果我們選擇采取隨機行動,則小車車一直在失敗。 最終,目標將是運行強化學習算法,該算法將學習如何解決此問題。
有關Gym中環境的完整列表,請參閱此。
注意:如果您在運行atari(阿塔利)游戲時遇到問題,請參見內容:https://github.com/openai/gym/issues/1726。
2. Retro
創建有趣的環境的另一個選項是使用Retro。 該軟件包由OpenAI開發,可讓您使用ROMS來模擬Airstriker-Genesis之類的游戲。
只需使用以下命令安裝軟件包:
- pip install gym-retro
然后,我們可以使用以下方法創建和查看環境:
- import retro
- env = retro.make(game='Airstriker-Genesis')
同樣,要渲染游戲,請運行以下代碼:
- import retro
- env = retro.make(game='Airstriker-Genesis')
- obs = env.reset()
- while True:
- action = env.action_space.sample()
- obs, rewards, done, info = env.step(action)
- env.render()
- if done:
- break
要安裝ROMS,您需要找到相應的.sha文件,然后運行:
- python3 -m retro.import /path/to/your/ROMs/directory/
注意:有關易于使用的環境的完整列表,請運行:
- retro.data.list_games()
3. Procgen
強化學習的一個典型問題是,生成的算法通常可以在特定環境下很好地工作,但無法學習任何可通用的技能。 例如,如果我們要改變游戲的外觀或敵人的反應該怎么辦?
為了解決這個問題,OpenAI開發了一個名為Procgen的軟件包,該軟件包允許創建過程生成的環境。 我們可以使用此軟件包來衡量強化學習代理學習通用技能的速度。
渲染游戲非常簡單:
- import gym
- param = {"num_levels": 1, "distribution_mode": "hard"}
- env = gym.make("procgen:procgen-leaper-v0", **param)
- obs = env.reset()
- while True:
- action = env.action_space.sample()
- obs, rewards, done, info = env.step(action)
- env.render()
- if done:
- break
這將生成可在其上訓練算法的單個級別。 有幾個選項可用于以程序方式生成同一環境的許多不同版本:
- num_levels-可以生成的唯一級別數
- distribution_mode-使用哪種級別的變量,選項為"easy簡單","hard難","extreme極致","memory記憶","exploration探索"。 所有游戲都支持“易”和“難”,而其他選項則取決于游戲。
二、強化學習
現在,終于是時候進行實際的強化學習了。 盡管有許多可用的軟件包可用于訓練算法,但由于它們的可靠實現,我將主要研究“穩定Baselines ”。
請注意,我不會在此帖子中解釋RL算法的實際工作方式,因為這本身就需要一個全新的帖子。 有關最新算法(例如PPO,SAC和TD3)的概述,請參見內容:
https://github.com/dennybritz/reinforcement-learning。
1. 穩定的基線(穩定Baselines)
穩定基準(SB)是基于OpenAI基準的,旨在使研究社區和行業更容易復制,改進和識別新想法。 他們在“基線”上進行了改進,使之成為一個更穩定,更簡單的工具,使初學者可以嘗試進行“強化學習”,而不會陷入實施細節中。
SB之所以經常使用,是因為它可以輕松,快速地應用最新的強化學習算法。 此外,創建和訓練RL模型只需要幾行代碼。
安裝可以簡單地通過以下方式完成:pip install stable-baselines。 然后,為了創建和學習RL模型(例如PPO2),我們運行以下代碼行:
- from stable_baselines import PPO2
- from stable_baselines.common.policies import MlpPolicy
- model = PPO2(MlpPolicy, env, verbose=1)
- model.learn(total_timesteps=10_000, log_interval=10)
有些事情可能需要一些解釋:
- total_timesteps:要訓練的樣本總數
- MlpPolicy:實現actor-critic的Policy對象。 在這種情況下,將使用2層64層的多層感知器。還有視覺信息策略,例如CnnPolicy甚至CnnLstmPolicy
為了將此模型應用于CartPole示例,我們需要將環境包裝在Dummy中,以使其可供SB使用。 然后,在CartPole環境中訓練PPO2的完整示例如下:
- from stable_baselines.common.policies import MlpPolicy
- from stable_baselines.common.vec_env import DummyVecEnv
- from stable_baselines import PPO2
- import gym
- env = gym.make('CartPole-v0')
- env = DummyVecEnv([lambda: env])
- model = PPO2(MlpPolicy, env, verbose=1)
- model.learn(total_timesteps=50_000, log_interval=10)
- obs = env.reset()
- while True:
- action, _states = model.predict(obs)
- obs, rewards, dones, info = env.step(action)
- env.render()
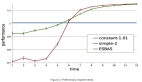
如上圖所示,PPO2僅用50,000步就設法找到一種保持極點穩定的方法。 這只需要幾行代碼和幾分鐘的處理!
如果要將其應用于Procgen或Retro,請確保選擇一個允許基于卷積的網絡的策略,因為觀察空間很可能是環境當前狀態的圖像。
最后,CartPole示例非常簡單,僅需訓練50,000步即可。 大多數其他環境在顯示出顯著改進之前通常需要執行幾千萬步。
注意:《穩定基準》的作者警告初學者在產品中使用該軟件包之前,對強化學習要有很好的了解。 強化學習有許多關鍵組成部分,如果其中任何一個出現錯誤,該算法將失敗,并且可能會留下很少的解釋。
2. 其他軟件包
還有其他一些常用于應用RL算法的軟件包:
- TF-Agents-比穩定基線需要更多的編碼,但通常是強化學習研究的必備軟件包。
- MinimalRL-在Pytorch中以非常少的代碼實現的最新RL算法。 它絕對有助于理解算法。
- DeepRL-Pytorch的另一種實現,但是此版本還具有實現要使用的其他環境。
- MlAgents-一個開放源代碼的Unity插件,使游戲和模擬可用作培訓代理的環境。
三、結論
強化學習可能是一個棘手的課題,因為很難調試代碼中是否以及何時出現問題。 希望這篇文章可以幫助您開始進行強化學習。