強(qiáng)化學(xué)習(xí)與多任務(wù)推薦

一、短視頻推薦兩階段約束強(qiáng)化學(xué)習(xí)算法

首先介紹的一項(xiàng)快手自研的 WWW 2023 Research Track 工作,主要解決短視頻推薦場景下的帶約束多目標(biāo)優(yōu)化問題。
在短視頻推薦單列場景中,用戶通過上下滑形式和系統(tǒng)進(jìn)行交互,觀看多個(gè)視頻。用戶對每個(gè)視頻反饋 2 種信號,播放時(shí)長以及互動(關(guān)注、點(diǎn)贊、評論、收藏、分享等)。由于播放時(shí)長稠密與留存和 DAU 相關(guān)度高,短視頻推薦系統(tǒng)主優(yōu)化目標(biāo)是提升總觀看視頻時(shí)長,這一問題可以由強(qiáng)化學(xué)習(xí)方法有效解決;另一方面,由于互動指標(biāo)能一定程度地反應(yīng)用戶滿意度,和留存有相關(guān)性,我們希望算法也能夠滿足互動指標(biāo)約束,
因此本文將短視頻推薦建模成一個(gè)約束強(qiáng)化學(xué)習(xí)問題(CMDP),目標(biāo)是在滿足互動指標(biāo)約束情況下最大化視頻播放時(shí)長。然而現(xiàn)有約束強(qiáng)化學(xué)習(xí)算法由于以下原因并不適用:第一單一 Critic 模型聯(lián)合預(yù)估時(shí)長將會主導(dǎo)互動;第二短視頻推薦系統(tǒng)存在多個(gè)約束目標(biāo),直接優(yōu)化約束強(qiáng)化學(xué)習(xí)對偶問題需要對拉格朗日超參進(jìn)行搜索,這會帶來極大的搜索成本。
我們提出 Two-Stage Constrained Actor-Critic(TSCAC)算法:
- 第一階段:對于每個(gè)互動輔助信號,學(xué)習(xí)不同 policy 優(yōu)化對應(yīng)的信號;
- 第二階段,學(xué)習(xí) policy 優(yōu)化播放時(shí)長目標(biāo),同時(shí)滿足和第一階段學(xué)習(xí)到的 policy 的距離約束。我們在理論上得到了第二階段問題的最優(yōu)解并提出新的優(yōu)化 loss。通過在 KuaiRand 數(shù)據(jù)集的離線評估和快手 App 在線 A/B 測試,我們證明 TSCAC 顯著優(yōu)于 Pareto 優(yōu)化以及 State of the Art 約束強(qiáng)化學(xué)習(xí)算法。TSCAC 算法已經(jīng)在快手 App 全量。
1、問題建模

我們把短視頻推薦系統(tǒng)看作 agent,用戶視為環(huán)境,每當(dāng)用戶打開 App,開啟一個(gè) session,一個(gè) session 包括多次請求。每次請求是一個(gè) step,推薦系統(tǒng)(agent)根據(jù)當(dāng)前用戶的 state,返回一個(gè) action(視頻)給用戶。用戶看到視頻后反饋多個(gè) reward 信號(觀看時(shí)長,點(diǎn)贊、關(guān)注、評論、轉(zhuǎn)發(fā)等互動信號)。用戶離開 App 這個(gè) session 結(jié)束。推薦系統(tǒng)目標(biāo)為最大化 session 累計(jì)觀看時(shí)長,同時(shí)滿足互動約束。推薦系統(tǒng)的優(yōu)化目標(biāo)為學(xué)習(xí)一個(gè)推薦策略(policy), 求解以下 program。

2、TWO-STAGE CONSTRAINED ACTOR-CRITIC 算法
為了解決上述挑戰(zhàn),我們提出兩階段約束強(qiáng)化學(xué)習(xí)算法(Two-stage constrained actor-critic, TSCAC),我們針對不同的反饋信號,采取不同的 Critic 模型進(jìn)行預(yù)估。策略優(yōu)化方面,第一階段分別學(xué)習(xí)策略優(yōu)化相應(yīng)的輔助目標(biāo),第二階段我們最大化主目標(biāo)時(shí)長,并且增加第一階段預(yù)訓(xùn)練得到策略的距離約束。
- Stage One: Policy Learning for Auxiliary Response
我們對于每個(gè)目標(biāo)分別用不同的策略進(jìn)行學(xué)習(xí),用 Temporal Difference(TD) loss 的形式來訓(xùn)練 Critic:

我們采用 Actor-Critic 算法常用的 advantage-based loss 來訓(xùn)練 Actor:

- Stage Two: Softly Constrained Optimization of the Main Response
第二階段我們需要最大化主目標(biāo)時(shí)長收益,但是也需要兼顧輔助目標(biāo)。基于第一階段學(xué)習(xí)到的輔助策略隱含了輔助目標(biāo)信息的假設(shè),我們學(xué)習(xí)策略最大化主目標(biāo),同時(shí)約束主策略和其他輔助策略不會距離太遠(yuǎn),即:

然而這個(gè)問題需要加很多 KL 約束不好直接優(yōu)化策略,我們可以證明(5)對偶問題存在以下最優(yōu)解形式:

因此我們學(xué)習(xí)策略最小化和最優(yōu)解的 KL 距離:

這個(gè) loss 的動機(jī)在于輔助策略 \pi_{\theta_i}提供了 action 的重要性,如果輔助策略覺得這個(gè) action 很差,那么這個(gè) action 的樣本重要性會很低。\lambda_i 代表了約束強(qiáng)弱,值越大提供約束越強(qiáng),極端情況為 0 時(shí)意味著不加任何約束,公式(7)和直接優(yōu)化主目標(biāo)等價(jià)。實(shí)際應(yīng)用時(shí)候我們設(shè)置所有輔助目標(biāo)都采用的超參值,有效地縮減搜索空間。
3、離線實(shí)驗(yàn)
我們將 TSCAC 算法在 KuaiRand 公開數(shù)據(jù)集進(jìn)行驗(yàn)證,對比了 BC(Behavior Cloning)Wide&Deep、DeepFM 監(jiān)督學(xué)習(xí)算法,State of the Art 約束強(qiáng)化學(xué)習(xí)方法 RCPO,以及 Pareto 優(yōu)化推薦算法。

表 2 結(jié)果證明,TSCAC 方法不僅在主目標(biāo) WatchTime 顯著優(yōu)于其他算法,并且在Click,Like,Comment 等指標(biāo)也取得了最好的效果。注意到 Pareto 優(yōu)化方法沒有主次之分,學(xué)到降低 Hate 的一個(gè) pareto 最優(yōu)點(diǎn),但是主目標(biāo)相比 BC 算法負(fù)向。
4、在線實(shí)驗(yàn)
我們在快手短視頻推薦系統(tǒng)進(jìn)行在線 A/B 實(shí)驗(yàn),基線為 Learning to Rank 算法,實(shí)驗(yàn)組為 TSCAC、RCPO 以及只學(xué)習(xí)互動的 Actor-Critic 算法(Interaction-AC)。

表 3 展示了算法收斂后,不同指標(biāo)的百分比提升對比。可以發(fā)現(xiàn) TSCAC 算法相比 RCPO 不僅主目標(biāo)更好(0.1% 的 watchtime 就視為統(tǒng)計(jì)顯著),并且輔助目標(biāo)也是全面正向,對比 Interaction-AC 算法的互動指標(biāo)也非常接近。下圖展示了 TSCAC 算法訓(xùn)練到收斂每天的效果變化。

二、基于強(qiáng)化學(xué)習(xí)的多任務(wù)推薦框架
下面介紹第二個(gè)工作,同樣也是強(qiáng)化學(xué)習(xí)在多任務(wù)優(yōu)化上的應(yīng)用。這篇工作是快手和香港城市大學(xué)的合作項(xiàng)目,是一個(gè)典型的多任務(wù)優(yōu)化問題。

1、摘要
近年來,多任務(wù)學(xué)習(xí)(MTL)在推薦系統(tǒng)(RS)應(yīng)用中取得了巨大的成功。然而,目前大部分基于 MTL 的推薦模型往往忽略了用戶與推薦系統(tǒng)互動的會話(session)模式,因?yàn)樗鼈冎饕且罁?jù)基于單個(gè) item 的數(shù)據(jù)集而構(gòu)建。平衡多個(gè)輸出目標(biāo)一直是該領(lǐng)域的一個(gè)挑戰(zhàn)。為了解決這個(gè)問題,我們提出了一個(gè)基于強(qiáng)化學(xué)習(xí)(RL)的 MTL 框架,即 RMTL 。該框架使用動態(tài)權(quán)重來平衡不同推薦任務(wù)的損失函數(shù)。具體來說,RMTL 結(jié)構(gòu)可以通過以下方式解決上述兩個(gè)問題:
- 從 session 尺度構(gòu)建 MTL 環(huán)境。
- 訓(xùn)練多任務(wù) actor-critic 網(wǎng)絡(luò)結(jié)構(gòu),并能與現(xiàn)有的基于 MTL 的推薦模型兼容。
- 使用 critic 網(wǎng)絡(luò)生成的權(quán)重來優(yōu)化和微調(diào) MTL 損失函數(shù)。
在基于 KuaiRand 等多個(gè)公開數(shù)據(jù)集的實(shí)驗(yàn)證明了 RMTL 的有效性,其 AUC 顯著高于 SOTA 基于 MTL 的推薦模型。我們還驗(yàn)證 RMTL 在各種 MTL 模型中的表現(xiàn),證明其具有良好的兼容性和可轉(zhuǎn)移性。
2、問題建模
我們構(gòu)建基于 session 的 MDP 用于 RL 訓(xùn)練,以此來提高 MTL 模型的性能。經(jīng)典的 MTL 方法通常面臨將序列性的用戶行為引入建模的困難,因?yàn)橛脩粜袨榈臅r(shí)間戳高度相關(guān),而建立在 MDP 序列之上的強(qiáng)化學(xué)習(xí)可以解決這個(gè)問題。對于每個(gè)會話 session,狀態(tài)轉(zhuǎn)移記錄是由原始數(shù)據(jù)集中存儲的時(shí)間戳分隔的。這種構(gòu)造可以生成按順序組織的 session MDP 序列,具有整體損失權(quán)重更新的優(yōu)點(diǎn)。馬爾科夫過程由狀態(tài)(state),動作(action),獎勵函數(shù)(reward function),轉(zhuǎn)移函數(shù)(transition function)組成。狀態(tài)空間 S 是狀態(tài)的集合,其中包含 user-item 組合特征。行動空間 A 是連續(xù)動作的集合,其中每個(gè)元素在 A 中表示 CTR 和 CTCVR 的預(yù)測值。為了與 BCE 損失的定義保持一致,我們使用負(fù) BCE 值定義每個(gè)步驟的獎勵函數(shù)。
3、算法
我們提出 RMTL 框架:使用狀態(tài)表示網(wǎng)絡(luò)將數(shù)據(jù)特征轉(zhuǎn)換為狀態(tài)信息。Actor 網(wǎng)絡(luò)可以是任何基本的 MTL 模型,輸出特定的動作向量。Critic 網(wǎng)絡(luò)用來提高 Actor 網(wǎng)絡(luò)的性能,并為特定任務(wù)生成自適應(yīng)調(diào)整的損失權(quán)重。

其中狀態(tài)表示網(wǎng)絡(luò)是由嵌入層和多層感知機(jī)組成的,以提取 user-item 特征。分類特征首先被轉(zhuǎn)換為二進(jìn)制向量,然后輸入到嵌入層中。此外,數(shù)值特征通過線性變換轉(zhuǎn)換為相同的維度。以上過程轉(zhuǎn)化得到的特征將被合并并進(jìn)一步作為另一個(gè) MLP 網(wǎng)絡(luò)的輸入。
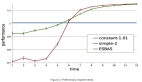
在強(qiáng)化學(xué)習(xí)的框架下,Actor 網(wǎng)絡(luò)可以被稱為策略代理。以 ESMM 為例:共享底層被移除,我們使用兩個(gè)平行的神經(jīng)網(wǎng)絡(luò),由 ??1 和 ??2 進(jìn)行參數(shù)化,分別表示兩個(gè)任務(wù)的 Tower 層。每個(gè) Tower 層的輸出是確定性的動作值,代表特定任務(wù)的預(yù)測值。在 MDP 序列的訓(xùn)練過程完成后,本文基于加權(quán) BCE loss 計(jì)算總體的損失函數(shù),以解決收斂問題。

本文提出了一種 Multi-critic 結(jié)構(gòu),其中有兩個(gè)并行的 MLP 網(wǎng)絡(luò)共享一個(gè)底層網(wǎng)絡(luò)。Critic 網(wǎng)絡(luò)的第一部分是一個(gè)共享的底層網(wǎng)絡(luò),它同時(shí)轉(zhuǎn)換 user-item 特征和 Action 信息。然后將用戶 item 特征和 Action 信息組合為兩個(gè)可微的行動價(jià)值網(wǎng)絡(luò)的輸入,這些網(wǎng)絡(luò)由????參數(shù)化并輸出估計(jì)的 Q 值,并且本文計(jì)算平均 Temporal Difference(TD)誤差 ??以更新 critic 網(wǎng)絡(luò)。目標(biāo)損失函數(shù)的權(quán)重沿著 Q 值方向反向調(diào)整,以此來改善 actor 網(wǎng)絡(luò)的優(yōu)化過程。

整體算法過程如下:給定 user-item 組合特征,狀態(tài)表示網(wǎng)絡(luò)生成基于輸入特征的狀態(tài)。然后,我們從 Actor 網(wǎng)絡(luò)中提取狀態(tài)信息獲取動作。動作值和 user-item 組合特征經(jīng)過 MLP 層和嵌入層進(jìn)一步處理,作為 Critic 網(wǎng)絡(luò)的輸入,計(jì)算每個(gè)任務(wù) ??的 Critic 網(wǎng)絡(luò) ?? 值。最后,可以根據(jù)每個(gè)任務(wù)的 BCE 損失和適應(yīng)權(quán)重估計(jì)多任務(wù)的整體損失函數(shù) L。
4、實(shí)驗(yàn)
本文主要在兩個(gè)基準(zhǔn)數(shù)據(jù)集,RetailRocket 和 Kuairand 上進(jìn)行實(shí)驗(yàn)。評估指標(biāo)是 AUC 分?jǐn)?shù),logloss 和 s-logloss(定義為所有會話的平均 Logloss)。由于本文的 RMTL 結(jié)構(gòu)修改了 MTL 目標(biāo)損失函數(shù),因此選擇了具有其默認(rèn)損失函數(shù)和一個(gè)基于 RL 的模型作為基線。本文總共進(jìn)行了3 個(gè)實(shí)驗(yàn):整體效果、可轉(zhuǎn)移性研究和消融實(shí)驗(yàn),以說明該方法的有效性。
在整體性能和比較方面,本文比較了五個(gè)基準(zhǔn)多任務(wù)學(xué)習(xí)模型和 RMTL 模型在兩個(gè)不同數(shù)據(jù)集上 CTR/CTCVR 預(yù)測任務(wù)的性能。在大多數(shù)情況下,PLE 模型在所有多任務(wù)學(xué)習(xí)基準(zhǔn)模型中表現(xiàn)最好,這證明 PLE 基準(zhǔn)模型可以提高任務(wù)之間信息共享的效率,以實(shí)現(xiàn)更好的預(yù)測性能。本文提出的 RMTL 模型的每個(gè)版本都在兩個(gè)數(shù)據(jù)集上表現(xiàn)出優(yōu)于相應(yīng)的非 RL 版本基準(zhǔn)模型的結(jié)果。特別是在 RetialRocket 數(shù)據(jù)集上,RMTL 模型的 AUC 增益約為 0.003-0.005,比相應(yīng)的基準(zhǔn)模型高。通過利用強(qiáng)化學(xué)習(xí)框架的序列特性,RMTL 能夠處理基于會話的推薦數(shù)據(jù),并通過自適應(yīng)調(diào)整損失函數(shù)權(quán)重在 CTR/CTCVR 預(yù)測任務(wù)中取得顯著改進(jìn)。

RMTL 方法在 RetialRocket 數(shù)據(jù)集上的轉(zhuǎn)移性研究中,本文試圖弄清楚從不同的策略學(xué)習(xí)到的 critic 網(wǎng)絡(luò)是否可以應(yīng)用于同一 MTL 基準(zhǔn)模型并提高預(yù)測性能。例如,“mmoe-ESMM”表示應(yīng)用從 MMoE 結(jié)構(gòu)訓(xùn)練的 critic 網(wǎng)絡(luò)的 ESMM 模型。可以看出:
- 三個(gè) MTL 模型的預(yù)訓(xùn)練 critic 網(wǎng)絡(luò)可以顯著提高每個(gè)基準(zhǔn)模型的 AUC。
- 三個(gè) MTL 模型的預(yù)訓(xùn)練 critic 網(wǎng)絡(luò)可以顯著降低每個(gè)基準(zhǔn)模型的 Logloss。
總的來說,預(yù)訓(xùn)練的 ciritc 網(wǎng)絡(luò)能夠提高大多數(shù) MTL 模型的預(yù)測性能。

實(shí)驗(yàn)的最后一部分是對于 RetailRocket 數(shù)據(jù)集上 PLE 模型的剖析研究,本文改變了原有設(shè)定中的一些部分,并定義了以下三個(gè)變體:
- CW: 表示對整體損失函數(shù)應(yīng)用恒定權(quán)重,并且不對 actor 網(wǎng)絡(luò)進(jìn)行梯度策略更新,從而消除了 critic 網(wǎng)絡(luò)的貢獻(xiàn)。
- WL: 表示損失權(quán)重受到 session 行為標(biāo)簽的控制。
- NLC: 不對損失權(quán)重執(zhí)行線性變換,而是直接將負(fù) Q 值分配給損失權(quán)重。
可以觀察到:
- CW 在兩個(gè)預(yù)測任務(wù)的 AUC 和 logloss 指標(biāo)上表現(xiàn)最差。
- WL 和 NLC 在本研究中的表現(xiàn)幾乎相同,優(yōu)于 CW 變體,AUC 提高了 0.002-0.003。
使用本文提出的總損失設(shè)置的 RMTL-PLE 在兩個(gè)任務(wù)上均取得了最佳表現(xiàn),說明了該線性組合權(quán)重設(shè)計(jì)的有效性。


最后總結(jié)一下 RMTL 和 MTL 的一些經(jīng)驗(yàn)。
推薦系統(tǒng)在長期優(yōu)化的時(shí)候,尤其是在長期優(yōu)化復(fù)雜指標(biāo)的時(shí)候,是非常典型的強(qiáng)化學(xué)習(xí)和多任務(wù)優(yōu)化場景。如果是主副目標(biāo)聯(lián)合優(yōu)化,可以通過 soft-regularization 去約束目標(biāo)學(xué)習(xí)。多目標(biāo)聯(lián)合優(yōu)化時(shí),考慮到不同目標(biāo)的動態(tài)變化,也能夠提升它的優(yōu)化效果。除此之外也有一些挑戰(zhàn),比如在強(qiáng)化學(xué)習(xí)不同模塊結(jié)合時(shí),會對系統(tǒng)的穩(wěn)定性帶來很多挑戰(zhàn)。這時(shí)對數(shù)據(jù)質(zhì)量的把控以及 label 的準(zhǔn)確性的把控,和模型預(yù)估的準(zhǔn)確率的監(jiān)督是非常重要的途徑。另外,推薦系統(tǒng)和用戶因?yàn)槭侵苯咏换ィ煌繕?biāo)在反映用戶體驗(yàn)的時(shí)候,僅僅是片面的反應(yīng),所以得到的推薦策略也會非常的不同。在不斷變化的用戶狀態(tài)下,還要聯(lián)合優(yōu)化,提升用戶的全面體驗(yàn),這在未來肯定是非常重要的課題。
三、問答環(huán)節(jié)
Q1:快手的時(shí)長信號和互動信號一般用的是什么 loss?是分類還是回歸?互動目標(biāo)和觀看目標(biāo)離線評估一般看哪些指標(biāo)?
A1:時(shí)長指標(biāo)是最典型的回歸任務(wù)。但是我們同樣也注意到,時(shí)長的預(yù)估是和視頻本身的長度強(qiáng)相關(guān)的。比如短視頻和長視頻的分布就會非常不一樣。所以在預(yù)估時(shí)要先對其做分類處理,然后再做 regression。
最近在 KDD 也有一篇文章,用樹方法去拆分時(shí)長信號預(yù)估。可以把時(shí)長分成長視頻和短視頻,各有各自的預(yù)估范圍,然后可以用樹的方法進(jìn)行更細(xì)致的劃分。長視頻可以分成中視頻和長視頻,短視頻也可以分成超短視頻和短視頻。整體效果上來看,目前還是在分類的框架下,然后再做 regression,效果會稍微好一點(diǎn)。其他的互動指標(biāo)預(yù)估,和現(xiàn)有的預(yù)估方法類似。
離線評估一般會同時(shí)關(guān)注 AUC 和 GAUC。時(shí)長我們主要看的是 online 的指標(biāo)。離線和線上的評估也存在差異。如果離線的評估沒有 significant 的 improvement 的話,那線上一般也不一定能看到對應(yīng)的提升效果。
Q2:是否遇到過數(shù)據(jù)特別稀疏,或者要調(diào)的某個(gè)目標(biāo)本身特別稀疏的情況?如果基于線上數(shù)據(jù)調(diào)參,那反饋周期可能較長,這樣調(diào)參效率會不會比較低?這種情況下有什么解決辦法?
A2:我們最近也有一些工作去討論這種極其稀疏的情況,甚至是幾天才會有反饋信號。其中最典型的就是用戶的留存。因?yàn)橛脩艨赡茈x開之后,過幾天才會回來。拿到信號的時(shí)候,模型已經(jīng)更新過好幾天了。解決這類問題有一些折中的方案,可以去分析一下實(shí)時(shí)的指標(biāo),或者實(shí)時(shí)的反饋信號有哪些和這種極其稀疏的信號有相關(guān)性。然后可以通過優(yōu)化這些實(shí)時(shí)的信號去間接地優(yōu)化長期信號。
以留存為例。我們發(fā)現(xiàn)它和用戶的實(shí)時(shí)觀看時(shí)長是強(qiáng)正相關(guān)的。一般用戶觀看時(shí)長增長,就代表了用戶對系統(tǒng)的粘度提高。這樣基本上能夠保證用戶留存的下界。我們?nèi)?yōu)化留存的時(shí)候,一般會使用一些其他相關(guān)的指標(biāo)去優(yōu)化留存。
Q3:快手的多目標(biāo)融合用強(qiáng)化學(xué)習(xí)這種方式的時(shí)候,一般會使用哪些優(yōu)化特征?是不是會存在一些很精細(xì)的特征,比如用戶的 ID?會不會導(dǎo)致模型收斂非常困難?
A3:User ID 其實(shí)還好,我們的 User 特征,除了有 ID 特征以外,還會有一些統(tǒng)計(jì)特征。除此之外在推薦鏈路上,RL 在我們的應(yīng)用模塊是處于比較靠后的階段,比如精排和重排階段。在前面的一些階段也會給出一些預(yù)估和模型的排序信號。這些都有一些用戶的信號在里面。所以目前推薦的強(qiáng)化學(xué)習(xí),在推薦的場景下拿到的User 側(cè)的信號還是很多的,基本上不會出現(xiàn)只用 User ID 的這種情況。
我們發(fā)現(xiàn)如果不用 User ID 的話,對個(gè)性化影響比較大。如果只用一些用戶的統(tǒng)計(jì)特征,有的時(shí)候不如 User ID 的提升效果那么大。如果讓 User ID 的影響占比太大的話,會有波動性的問題。