揭開深度強化學習的神秘面紗
譯文【51CTO.com快譯】

深度強化學習是人工智能最令人關注的分支之一。它是人工智能領域一些技術最顯著成就的背后支撐,包括在棋盤和電子游戲、自動駕駛汽車、機器人和人工智能硬件設計方面中擊敗人類冠軍。
深度強化學習利用深度神經網絡的學習能力來解決傳統 RL 技術無法解決的復雜問題。深度強化學習比機器學習的其他分支復雜得多,在這篇文章中,將在不涉及技術細節的情況下揭開它的神秘面紗。
狀態、獎勵和行動
每個強化學習問題的核心都是一個 agent (代理)和一個環境。環境提供是有關系統狀態的信息。代理是用來觀察這些狀態并通過執行操作與環境進行交互,其動作可以是離散的(如撥動開關)或連續的(如轉動旋鈕)。這些操作會促使環境過渡到一個新狀態。并且根據新狀態是否與系統目標相關,代理將獲得獎勵(如果將代理遠離其目標,獎勵也可以為零或負)。
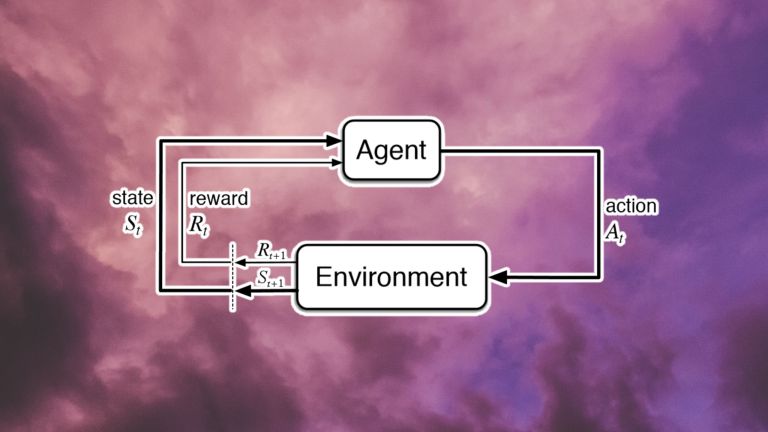
狀態-動作-獎勵循環圖
狀態-動作-獎勵的每一個循環都稱為一個步驟。強化學習系統繼續循環迭代,直到達到所需的狀態或達到最大步驟數為止。這一系列的步驟稱為一集。在每一片段開始時,環境被設置為初始狀態,代理的獎勵重置為零。
強化學習的目標是訓練代理采取行動,以其回報最大化,且代理的動作生成功能被稱為策略。一個代理通常需要很多情節來學習一個好的策略。對于簡單的問題,幾百個情節可能足以讓代理學習一個不錯的策略。對于更復雜的問題,代理可能需要數百萬次訓練才可以實現。
強化學習系統有更微妙的細微差別。例如,RL 環境可以是確定性的或非確定性的。在確定性環境中,多次運行一系列狀態-動作對總是會產生相同的結果。相比之下,在非確定性 RL 問題中,環境狀態可能會因代理行為以外的事物(例如,時間的流逝、天氣、環境中的其他代理)而發生變化。
強化學習應用

為了更好地理解強化學習的組成部分,通過下面幾個例子進行講解。
國際象棋:在這里,環境就是棋盤,環境的狀態是棋子在棋盤上的位置。RL 代理可以是其中一名玩家(或者,兩名玩家可以是在同一環境中分別訓練的RL 代理)。每一盤棋都是一集,這一集從初始狀態開始,黑板和白板的邊緣排列著黑色和白色的棋子。在每一步中,代理都會觀察棋盤(狀態)并移動其中的一個部分(采取行動),從而將環境轉換為新狀態。該代理會因達到將死狀態而獲得獎勵,否則將獲得零獎勵。國際象棋的一個關鍵挑戰是,棋手在將對手將死之前不會得到任何獎勵,這使得機器學習變得很困難。
Atari Breakout: Breakout 是一款玩家控制球拍的電子游戲。有一個球在屏幕上移動,每次擊中球拍,它就會反彈到屏幕的頂部,那里排列著一排排的磚塊。每次球拍碰到磚塊時,磚塊就會被破壞,隨之球會反彈回來。在 Breakout 中,環境就是游戲屏幕。狀態是球拍和磚塊的位置,以及球的位置和速度。代理可以執行的操作有向左移動、向右移動或著不移動。每次球擊中磚塊時,代理都會收到正獎勵,如果球越過球拍并到達屏幕底部,則代理會收到負獎勵。
自動駕駛汽車:在自動駕駛中,代理就是汽車,環境就是汽車行駛的空間。RL 代理通過攝像頭、激光雷達和其他傳感器觀察環境狀態。代理可以執行導航操作,例如加速、剎車、左轉或右轉等。RL 代理會因為保持正常駕駛、避免碰撞、遵守駕駛規則和遵守交通路線而獲得獎勵。
強化學習功能
基本上,強化學習的目標是以最大化獎勵的方式將狀態映射到動作。但是 RL 代理究竟學習了什么?
RL 系統有三種學習算法:
基于策略的算法:這是最常見的優化類型。策略將狀態映射到操作。學習策略的 RL 代理可以創建從當前狀態到目標的動作軌跡。
例如,實現一個正在優化策略以通過迷宮導航并到達出口的代理。首先,它進行隨機移動,但不會收到任何獎勵。在其中一集中,它最終到達出口并獲得出口獎勵。它回溯其軌跡,并根據代理與最終目標的接近程度重新調整每個狀態-動作對的獎勵。在下一集中,RL 代理將更好地了解給定每個狀態要采取的操作,從而逐漸調整策略,直到收斂到最優解。
REINFORCE 是一種流行的基于策略的算法。基于策略的函數的優勢在于可以應用于各種強化學習問題。基于策略的算法的權衡在于,它們的樣本效率低,并且在收斂到最佳解決方案之前需要大量訓練。
基于值的算法:基于值的函數學習評估狀態和動作的值。基于值的函數可幫助 RL 代理評估當前狀態和操作的未來回報是多少。
基于值的函數有兩種變體:Q 值和 V 值。Q 函數是估計狀態-動作對的預期回報。V 函數僅估計狀態的值。Q 函數更常見,因為它更容易將狀態-動作對轉換為 RL 策略。
兩種流行的基于值的算法是 SARSA 和 DQN。基于值的算法比基于策略的 RL 具有更高的樣本效率。它們的局限性在于它們僅適用于離散動作空間(除非對其進行一些更改)。
基于模型的算法:基于模型的算法采用不同的方法進行強化學習。他們不是評估狀態和動作的價值,而是預測給定當前狀態和動作的環境狀態。基于模型的強化學習允許agent在采取任何行動之前模擬不同的軌跡。
基于模型的方法為代理提供了遠見,并減少了手動收集數據的需要。在收集訓練數據和經驗既昂貴又緩慢的應用中非常有利(例如,機器人和自動駕駛汽車)。
但基于模型的強化學習的關鍵挑戰是,創建環境的真是模型可能非常困難。非確定性環境,如現實世界,很難建模。在某些情況下,開發人員設法創建近似真實環境的模擬。但是,即使是學習這些模擬環境的模型,也非常困難。
盡管如此,基于模型的算法在諸如國際象棋和圍棋等確定性問題中變得流行。蒙特卡羅樹搜索 (MTCS) 是一種流行的基于模型的方法,可應用于確定性環境。
組合方法:為了克服各類強化學習算法的缺點,科學家們開發了組合不同類型學習函數元素的算法。例如,Actor-Critic 算法結合了基于策略和基于值的函數的優點。這些算法使用來自價值函數(評論家)的反饋來引導策略學習者(參與者)朝著正確的方向改進,從而產生一個更具樣本效率的系統。
為什么要進行深度強化學習?

到目前為止,還沒有談到深度神經網絡。事實上,可以以任何方式實現上述所有算法。例如,Q-learning是一種經典的強化學習算法,它在agent與環境交互時創建了一個狀態-動作-獎勵值表。在處理狀態和操作數量非常少且非常簡單的環境時,此類方法可以很好地工作。
但是,當處理一個復雜的環境時,在這個環境中,動作和狀態的組合數量可能會達到巨大的數量,或者環境是不確定的,并且可能具有幾乎無限的狀態,評估每個可能的狀態-動作對就變得不可能了。
在這些情況下,需要一個近似函數,該函數可以根據有限的數據學習最優策略,這就是人工神經網絡所做的。給定正確的結構和優化函數,深度神經網絡可以學習最優策略,而無需遍歷系統的所有可能狀態。深度強化學習代理仍然需要大量數據(例如,在Dota和星際爭霸中進行數千小時的游戲),但它們可以解決經典強化學習系統無法解決的問題。
例如,深度強化學習模型可以使用卷積神經網絡從視覺數據中提取狀態信息,例如攝像機輸入和視頻游戲圖形。而遞歸神經網絡可以從幀序列中提取有用的信息,比如球的方向,或者汽車是否停放或移動。這種復雜的學習能力可以幫助 RL 代理理解更復雜的環境,并將其狀態映射到動作。
深度強化學習可與機器監督學習相媲美。該模型生成動作,并根據來自環境的反饋調整其參數。然而,深度強化學習也有一些獨特的挑戰,使其不同于傳統的監督學習。
與監督學習不同,在監督學習問題中,模型具有一組標記數據,RL 代理只能訪問其自身經驗的結果。它能夠根據在不同訓練階段收集的經驗來學習最佳策略。但也可能錯過許多其他導致更好政策的最佳軌跡。強化學習還需要評估狀態-動作對的軌跡,這比每個訓練示例與其預期結果配對的監督學習問題更難學習。
這種增加的復雜性增加了深度強化學習模型的數據要求。但監督學習不同的是,深度強化學習模型在訓練期間收集數據,監督學習可以提前管理和準備數據。在某些類型的 RL 算法中,在一個片段中收集的數據必須在之后被丟棄,并且不能用于進一步加快未來片段中的模型調整過程。
深度強化學習與通用人工智能
人工智能社區對深度強化學習的推動程度存在分歧。一些科學家認為,使用正確的 RL 架構,就可以解決任何類型的問題,包括通用人工智能。這些科學家相信,強化學習與產生自然智能的算法相同,如果有足夠的時間和精力以及適當的獎勵,我們可以重新創造人類水平的智能。
其他人則認為強化學習不能解決人工智能的一些最基本的問題。另一部分人認為,盡管深度強化學習代理有很多好處,但需要明確定義問題,并且無法自己發現新問題和解決方案。
無論如何,不可否認的是,深度強化學習已經幫助解決了一些非常復雜的挑戰,并且將繼續成為 人工智能社區目前感興趣和研究的一個重要領域。
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】