憑什么讓日志先寫?
在生活中,你一定有過類似這樣的經歷:
比如部門發禮品、或者說學校發課本。如果在發放的時候,大家一窩蜂的涌了過來,畢竟雙拳雙敵四手,漸漸你就招架不過來。
為了工作更好做,你會有幾個選擇,提前打印個名單,一個個來領,領的人在名單上打勾,東西拿走。或者大家都來拿,你看一眼,記在腦海里,但可能中途打個岔就記錯了。也可以記住是誰,找個紙記下來,每次記一下或者隔一會記幾下。
對比上面的場景,你沒有發現,不同的方式,效率上也存在的差別。比如在名單上找到打勾,那就會完全串行,每個人來都得在定位到自己那條信息上,找的過程費時間。
找一張紙,每隔一段時間記一次,這樣效率也還挺高,問題就在于別人打岔的頻率。
在計算機科學領域也存在這樣的時候,比如我們常用的數據庫系統里。數據庫為了不喝娃哈哈AD鈣奶,就能保證ACID中的A和D,使用了一種被稱做「WAL」的機制。全稱是write-ahead logging。數據庫中所有的變更,會先寫到日志里,最后才會寫到持久存儲的數據文件中。像MySQL 里的 redo log 和undo log 就是這種機制。
像你在紙上記錄一樣,一直不停的向后寫,順序寫,速度就會快,時不時的回過頭去檢查一下,改一下速度就降下來了。
如果大量記錄到白紙上的內容,沒有及時的匯總記錄到一個表格上,那等最后全部匯總也比較費力氣。就像數據庫里一直寫WAL之后就應用到內存數據修改,速度很快,但如果出現故障的時候,就需要重新回放大量的redo log,恢復時間也無法接受。
就像行政急著要結果的時候,你才開始「回放」白紙上的內容,就會慢很多。如果是在發放的過程中,可以過一段時間匯總一下,然后在白紙上加個「標記」,用于一會提示自己上次算到什么位置了。這種就是數據庫里的 checkpoint,下次恢復的時候,就直接從checkpoint 開始向后恢復就行,前面的已經持久化到了磁盤,不用再費事了。
此外,計算機里,許多時候,都是一個根據自己的場景權衡的過程。比如對于使用WAL的時候,MySQL 提供了不同的配置來支持什么時機,多長時間將 log 應用到數據文件,畢竟log 寫到磁盤也還是要花點兒時間的。每次都刷盤,會影響效率,但間隔時間太長,就會在機器故障的時候丟失數據。
MySQL 默認將log 刷到磁盤的時機有三個:
- 提交一個事務的時候
- 固定大小的 log buffer 滿了的時候
- 無論 log buffer 是否滿,每秒會刷一次
redo log 寫磁盤的過程
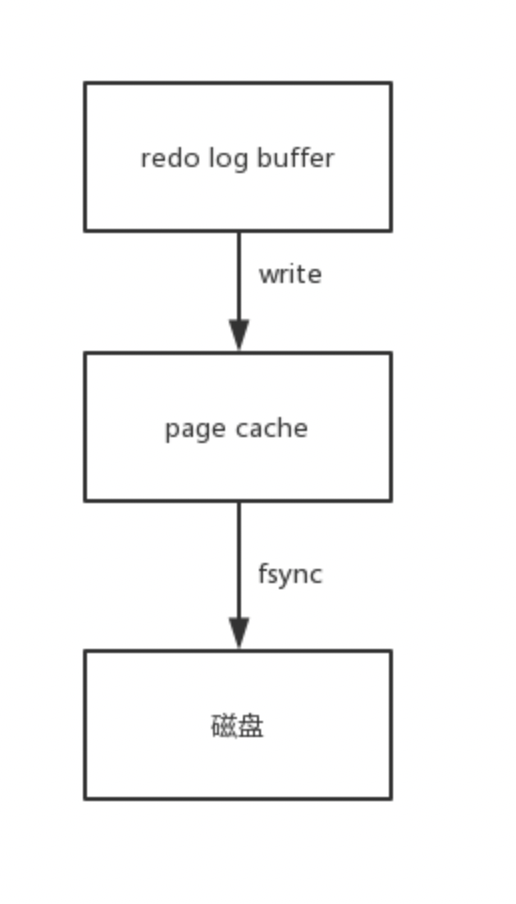
redo log buffer和page cache都是在內存中,所以寫入這兩者都比較快,而fsync則需要消耗磁盤IO。Mysql的后臺每隔1秒也會自動將redo log buffer中的內容刷到磁盤中去。
借用MySQL 官方博客的幾張圖來說明下
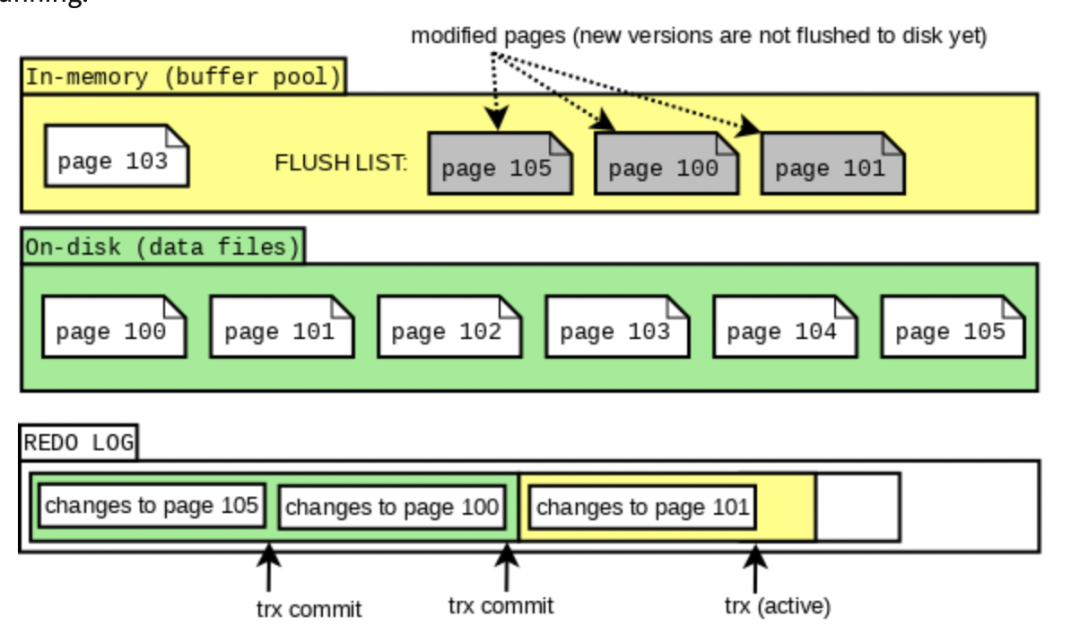
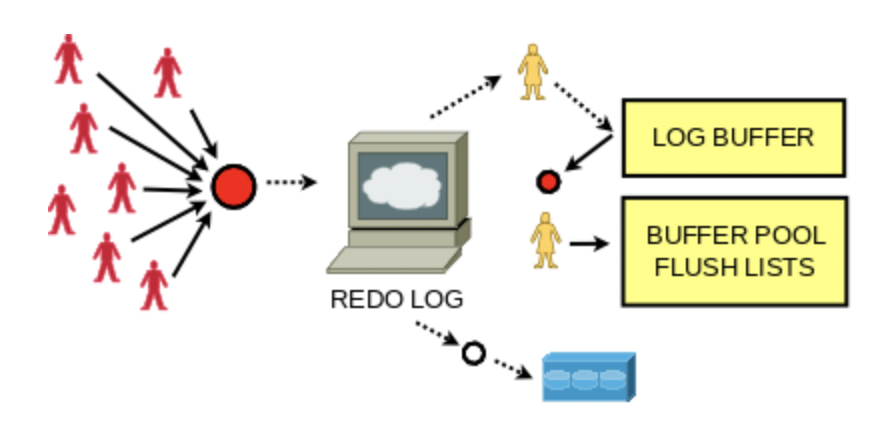
那有了redo log,就保證了故障時安全了嗎?是的。
機器在故障的時候,內存中包含數據的內容,也就是所謂的「臟頁」一般就會丟了,怎么樣恢復丟失的數據呢?咱們前面看到,redo log 先刷盤,之后真正的數據庫變更才刷盤,所以我們丟失的數據已經保存在磁盤中的redo log里了。重放redolog 就可以。但這里有例外的情況是MySQL 里包含一個 innodb_flush_log_at_trx_commit 的配置,默認是1,即嚴格的D,非1的情況下會丟失redo log buffer和page cache中的數據。
本文轉載自微信公眾號「 Tomcat那些事兒」,可以通過以下二維碼關注。轉載本文請聯系 Tomcat那些事兒公眾號。