新記錄誕生,騰訊云2分31秒打破ImageNet訓練記錄
8月21日,騰訊云正式對外宣布成功創造了128卡訓練ImageNet業界新記錄,以2分31秒的成績一舉刷新了這個領域的世界記錄。若改變跨機網絡帶寬,該成績還可以進一步提升至2分2秒,將這一記錄提升到一個全新的高度。
這次記錄是基于公有云25Gbps的VPC網絡環境,使用128塊V100 GPU,借助最新研制的Light大規模分布式多機多卡訓練框架創造的,最終成績定格在2分31秒訓練 ImageNet 28個epoch,TOP5精度達到93%,之前的業界最好成績是2分38秒。據了解,這項記錄的背后團隊來自騰訊云智能鈦團隊、騰訊機智團隊、騰訊優圖實驗室以及香港浸會大學計算機科學系褚曉文教授團隊。
作為人工智能最重要的基礎技術之一,深度學習的應用已經快速延伸到智慧城市、智能制造等眾多場景。然而與需求同步衍生的是在深度學習訓練中產生的諸多問題,比如數據量龐大且訓練耗時長、計算模型/結構愈漸復雜、參數量大、超參數范圍廣泛等。這些問題已經阻礙了深度學習開發應用的進度。如何做高性能AI訓練和計算,不僅關乎到AI生產研發效率,還對AI產品的迭代效率和成功上線產生重要影響,而高效訓練的一個非常重要的基準是如何在更短時間內對大型可視化數據庫ImageNet做一次訓練。
正是在這樣的背景下,騰訊云聯合多個團隊研發出了Light大規模分布式多機多卡訓練框架,從深度學習訓練的速度、多機多卡的擴展性、batch收斂等方面,為業界提供了一套全新的訓練解決方案。
在單機訓練速度方面,騰訊云首先利用GPU云服務器的內存和SSD云盤,在訓練過程中為訓練程序提供數據預取和緩存,加速了訪問遠程存儲數據。而針對大量線程相互搶占導致CPU運行效率低下問題,騰訊云通過自動調整最優數據預處理線程數來降低CPU的切換負擔,讓數據預處理和GPU計算并行,提升了整體訓練的速度。
在多機擴展訓練方面,以往的TCP環境下,跨機通信的數據需要從顯存拷到主存,再通過CPU去收發數據,計算時間短加上通信時間長,使多機多卡的擴展性受到了很大挑戰。騰訊云則憑借Light高效擴展了多機訓練,通過自適應梯度融合技術、層級通信+多流手段、層級topk壓縮通信算法等,充分利用通信時的網絡帶寬,優化了跨機通信的時間。
此外,為充分利用大規模集群算力,目前業界主要通過不斷提升訓練的batch size來提升訓練速度,但是batch size的增大會對精度帶來影響和損失。為解決這一問題,騰訊云通過大batch調參策略、梯度壓縮精度補償、AutoML調參等方法,有效實現了在增大batch size的同時,最小化其對精度的影響。
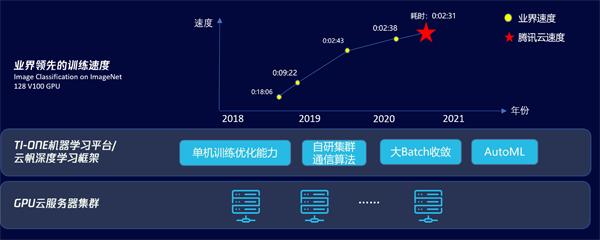
通過 Light大規模分布式多機多卡訓練框架及平臺等一系列完整的解決方案,ImageNet的訓練結果取得了新突破。并且在取得高效訓練的同時,也將其能力集成到騰訊云智能鈦機器學習平臺,并廣泛應用在騰訊內外部的業務。
接下來,聯合項目團隊還將進一步提升機器學習平臺易用性,訓練和推理性能,構建穩定、易用、好用、高效的平臺和服務,為算法工程師提供有力的機器學習工具,助力各行各業用戶業務的發展。