面試官:為什么在系統中不推薦雙寫?
引言
某日,阿雄跑去面試!于是有如下情形
面試官:"阿雄是吧,做做自我介紹!"
阿 雄:"我叫阿雄,來自某a國際電商公司!"
面試官:"我看你項目里用了elasticsearch,你是怎么同步數據的呢?"
阿 雄:"在代碼里寫入數據庫的時候,同時再寫入elasticsearch!"
面試官:"那你如何保證寫入數據庫,和寫入elasticsearch原子性問題呢?萬一寫入數據庫成功了,寫入elasticsearch失敗了怎么處理?"
阿 雄:"我還是回去等通知吧!"
OK,以上情形純屬虛構,如有雷同,絕對巧合!
其實這篇文章所探討的數據同步策略并不限于某兩種固定的存儲系統之間,而想去探討一種通用的數據同步策略。主要分為以下三個部分
- (1)背景介紹
- (2)雙寫缺點
- (3)改良方案
正文
背景介紹
話說阿雄在加入某a國際電商公司的時候,業務系統十分簡單,一個database就能搞定一切!
可是某a國際電商公司在產品韓的領導下,業務增長迅速,阿雄發現了數據庫越來越慢,于是乎阿雄加入了一些緩存,如redis來緩存一些數據,提高系統的響應能力。
又過了一段時間,產品韓發現搜索的速度灰常慢,讓阿雄去改。阿雄在網上發現,現在業內都用一些elasticsearch做一些全文檢索的操作,于是乎阿雄將一些需要全文檢索的數據放入elasticsearch,提高了系統的搜索能力!
隨著數據的膨脹,阿雄慢慢的發現了,對數據庫做一些數據分析操作,性能明顯的跟不上了。于是乎阿雄將數據庫里的數據,導入hadoop,然后進行數據分析。
(省略一萬字….)
最后,阿雄和產品韓幸福的在一起了。
OK,好,現在分析上面的場景!思考第一個問題
1、在database,redis,elasticsearch,hadoop中的數據是有關系的,還是彼此獨立的?
顯然是有關系的,在這幾個數據源中的數據都是相關的。只是格式不一樣而已!例如,對于一條Product數據,在數據庫里是

在redis里就是key為 product:pId:1,value是
- {
- "pId": "1",
- "productName": "macbook"
- }
如上所示,只是數據格式不一樣而已!
那好,現在思考第二個問題
2、既然這些數據源之間數據是相關的,如何保證這幾個數據源之間數據一致性!
一種比較簡單且容易想到的方案是,hardcode在程序中
例如現在有兩個數據源DataSouce1和DataSource2,我們往里頭寫數據,代碼如下
- ProductService{
- \\省略
- public void syncData(){
- x1. writeDataSource1();
- x2. writeDataSource2();
- }
- }
這就是我們標題中所提到的雙寫!那么,雙寫會帶來什么壞處呢?OK,繼續往下看!
雙寫缺點
一致性問題
打個比方我們現在有兩個client,同時往兩個DataSouce寫數據。
- 一個client往里頭入X為1
- 一個client往里頭入X為5
那么會有如下情形出現
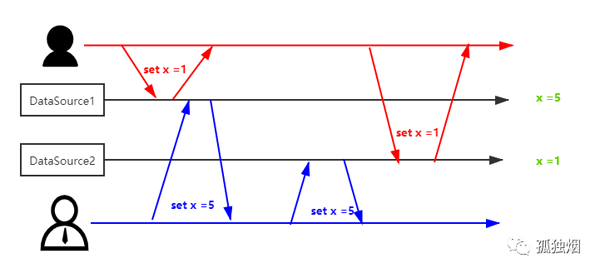
如圖所示,兩個DataSouce的數據就不一致了,一個為1,一個為5。除非接下來有一個新的請求,對x數據發生了變更,才能修正這種現象!否則,你可能永遠都發現不了。
原子性問題
因為我們需要同時往DataSource1和DataSource2一起寫數據,你需要保證
- x1. writeDataSource1();
- x2. writeDataSource2();
這兩個操作一起成功,或者一起失敗!如果采用雙寫的方法,是避不開這個問題的!
那么有沒有通用的辦法來解決這些問題呢?
有的,只要能按順序記錄數據的變更即可!那具體怎么做呢,我們繼續往下看!
改良方案
假設,如果我們能將數據按順序記錄,寫入某個消息隊列,然后其他系統按消息順序恢復數據,看看what happen?
此時架構圖如下
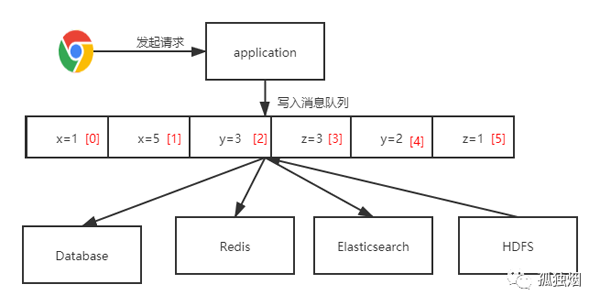
在該架構下,所有的數據變更寫入一個消息隊列里去。其他各數據源從消息隊列里恢復數據即可!
那么,此時還有一致性問題,和原子性問題么?
一致性問題
OK,這種情況下,各個數據源之間數據肯定是一致的。因為寫入順序已經在消息隊列中定義好,各數據源按照消息隊列中的消息順序,恢復數據即可,并不存在競爭現象。因此,不會出現不一致的問題!
原子性問題
OK,這種情況下,如果寫入DataSource失敗會怎么樣?例如出現了網絡問題,這條消息恢復失敗了。這個問題其實好解決,一般我們在順序根據消息恢復數據的時候,會記錄下坐標。如果寫入失敗,停止恢復數據。下次從該坐標處恢復數據即可。
但是在上面那張圖中,寫入DataBase是異步寫入的。這樣就不符合很多業務場景的"寫后即讀"的要求,因此,在實際落地中,做了一些變更!通用做法是去提取數據庫的變化!
如下圖所示
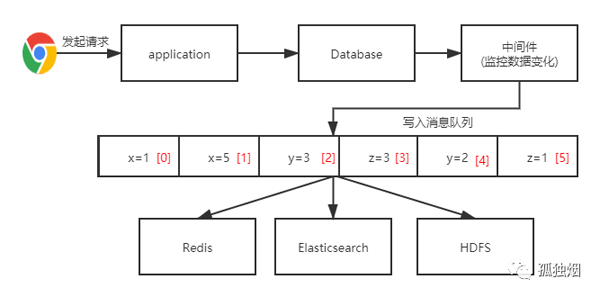
在該圖中的中間件,例如oracle中的oracle golden gate可以提取數據變化。mysql中的canal能提取數據的變化。至于消息隊列,可以選用kafka。直接提取數據變化到kafka中,其他數據源從kafka中獲取數據,避免了直接雙寫從而導致一致性和原子性問題。
總結
本問討論了在項目中常見的數據同步問題,希望大家有所收獲。