高并發系統三大利器之緩存
引言
隨著互聯網的高速發展,市面上也出現了越來越多的網站和app。我們判斷一個軟件是否好用,用戶體驗就是一個重要的衡量標準。比如說我們經常用的微信,打開一個頁面要十幾秒,發個語音要幾分鐘對方才能收到。相信這樣的軟件大家肯定是都不愿意用的。軟件要做到用戶體驗好,響應速度快,緩存就是必不可少的一個神器。緩存又分進程內緩存和分布式緩存兩種:分布式緩存如redis、memcached等,還有本地(進程內)緩存如ehcache、GuavaCache、Caffeine等。
緩存特征
緩存作為一個數據數據模型對象,那么它有一些什么樣的特征呢?下面我們分別來介紹下這些特征。
命中率
命中率=命中數/(命中數+沒有命中數)當某個請求能夠通過訪問緩存而得到響應時,稱為緩存命中。緩存命中率越高,緩存的利用率也就越高。
最大空間
緩存中可以容納最大元素的數量。當緩存存放的數據超過最大空間時,就需要根據淘汰算法來淘汰部分數據存放新到達的數據。
淘汰算法
緩存的存儲空間有限制,當緩存空間被用滿時,如何保證在穩定服務的同時有效提升命中率?這就由緩存淘汰算法來處理,設計適合自身數據特征的淘汰算法能夠有效提升緩存命中率。常見的淘汰算法有:
FIFO(first in first out)
「先進先出」。最先進入緩存的數據在緩存空間不夠的情況下(超出最大元素限制)會被優先被清除掉,以騰出新的空間接受新的數據。策略算法主要比較緩存元素的創建時間。「適用于保證高頻數據有效性場景,優先保障最新數據可用」。
LFU(less frequently used)
「最少使用」,無論是否過期,根據元素的被使用次數判斷,清除使用次數較少的元素釋放空間。策略算法主要比較元素的hitCount(命中次數)。「適用于保證高頻數據有效性場景」。
LRU(least recently used)
「最近最少使用」,無論是否過期,根據元素最后一次被使用的時間戳,清除最遠使用時間戳的元素釋放空間。策略算法主要比較元素最近一次被get使用時間。「比較適用于熱點數據場景,優先保證熱點數據的有效性。」
進程緩存
為什么需要引入本地緩存,本地緩存的應用場景有哪些?本地緩存的話是我們的應用和緩存都在同一個進程里面,獲取緩存數據的時候純內存操作,沒有額外的網絡開銷,速度非常快。它適用于緩存一些應用中基本不會變化的數據,比如(國家、省份、城市等)。
項目中一般如何使用、怎么樣加載、怎么樣更新?
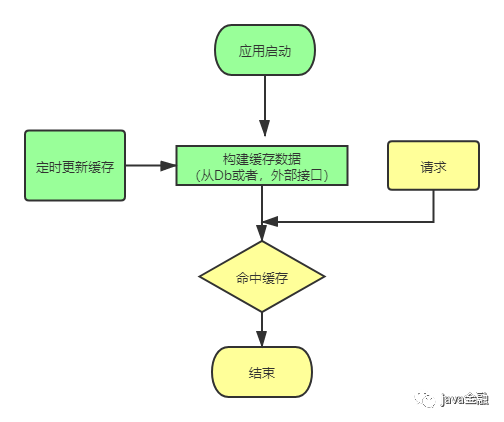
進程緩存的話,一般可以在應用啟動的時候,把需要的數據加載到系統中。更新緩存的話可以采取定時更新(實時性不高)。具體實現的話就是在應用中起一個定時任務(「ScheduledExecutorService」、「TimerTask」等),讓它每隔多久去加載變更(數據變更之后可以修改數據庫最后修改的時間,每次查詢變更數據的時候都可以根據這個最后變更時間加上半小時大于當前時間的數據)的數據重新到緩存里面來。如果覺得這個比較麻煩的話,還可以直接全部全量更新(就跟項目啟動加載數據一樣)。這種方式的話,對數據更新可能會有點延遲。可能這臺機器看到的是更新后的數據,那臺機器看到的數據還是老的(機器發布時間可能不一樣)。所以這種方式比較適用于對數據實時性要求不高的數據。如果對實時性有要求的話可以通過廣播訂閱mq消息。如果有數據更新mq會把更新數據推送到每一臺機器,這種方式的話實時性會比前一種「定時更新」的方法會好。但是實現起來會比較復雜。
本地緩存有哪些實現方式?常見本地緩存有以下幾種實現方式:
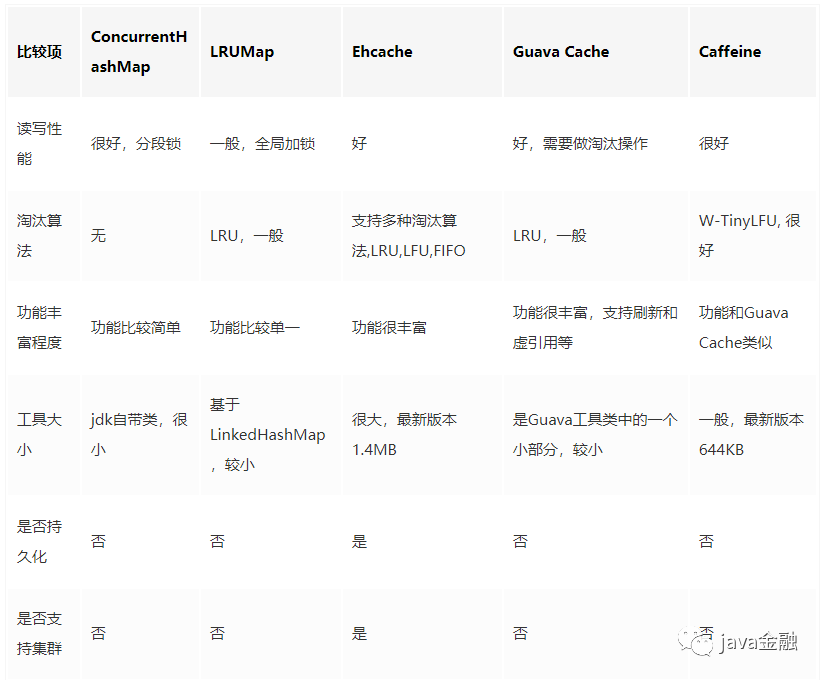
從上述表格我們看出性能最佳的是Caffeine。關于這個本地緩存的話我還是強烈推薦的,里面提供了豐富的api,以及各種各樣的淘汰算法。如需了解更加詳細的話可以看下以前寫的這個篇文章《本地緩存性能之王Caffeine》。
本地緩存
缺點本地緩存與業務系統耦合在一起,應用之間無法直接共享緩存的內容。需要每個應用節點單獨的維護自己的緩存。每個節點都需要一份一樣的緩存,對服務器內存造成一種浪費。本地緩存機器重啟、或者宕機都會丟失。
分布式緩存
分布式緩存是與應用分離的緩存組件或服務,其最大的優點是自身就是一個獨立的應用,與本地應用隔離,多個應用可直接的共享緩存。常見的分布式緩存有redis、MemCache等。
分布式緩存的應用在高并發的環境下,比如春節搶票大戰,一到放票的時間節點,分分鐘大量用戶以及黃牛的各種搶票軟件流量進入12306,這時候如果每個用戶的訪問都去數據庫實時查詢票的庫存,大量讀的請求涌入到數據庫,瞬間Db就會被打爆,cpu直接上升100%,服務馬上就要宕機或者假死。即使進行了分庫分表也是無法避免的。為了減輕db的壓力以及提高系統的響應速度。一般都會在數據庫前面加上一層緩存,甚至可能還會有多級緩存。
緩存常見問題
緩存雪崩
指大量緩存同一時間段集體失效,或者緩存整體不能提供服務,導致大量的請求全部到達數據庫 對數據CPU和內存造成巨大壓力,嚴重的會造成數據庫宕機。因此而形成的一系列連鎖反應造成整個系統奔潰。解決這個問題可以從以下方面入手:
- 保證緩存的高可用。使用redis的集群模式,即使個別redis節點下線,緩存還是可以用。一般稍微大點的公司還可能會在多個機房部署Redis。這樣即使某個機房突然停電,或者光纖又被挖斷了,這時候緩存還是可以使用。
- 使用多級緩存。不同級別緩存時間過時時間不一樣,即使某個級別緩存過期了,還有其他緩存級別 兜底。比如我們Redis緩存過期了,我們還有本地緩存。這樣的話即使沒有命中redis,有可能會命中本地緩存。
- 緩存永不過期。Redis中保存的key永久不失效,這樣的話就不會出現大量緩存同時失效的問題,但是這種做法會浪費更多的存儲空間,一般應該也不會推薦這種做法。
- 使用隨機過期時間。為每一個key都合理的設計一個過期時間,這樣可以避免大量的key在同一時刻集體失效。
- 異步重建緩存。這樣的話需要維護每個key的過期時間,定時去輪詢這些key的過期時間。例如一個key的value設置的過期時間是30min,那我們可以為這個key設置它自己的一個過期時間為20min。所以當這個key到了20min的時候我們就可以重新去構建這個key的緩存,同時也更新這個key的一個過期時間。
緩存穿透
指查詢一個不存在的數據,每次通過接口或者去查詢數據庫都查不到這個數據,比如黑客的惡意攻擊,比如知道一個訂單號后,然后就偽造一些不存在的訂單號,然后并發來請求你這個訂單詳情。這些訂單號在緩存中都查詢不到,然后會導致把這些查詢請求全部打到數據庫或者SOA接口。這樣的話就會導致數據庫宕機或者你的服務大量超時。這種查詢不存在的數據就是緩存擊穿。解決這個問題可以從以下方面入手:
- 緩存空值,對于這些不存在的請求,仍然給它緩存一個空的結果,這種方式簡單粗暴,但是如果后續這個請求有新值了需要把原來緩存的空值刪除掉(所以一般過期時間可以稍微設置的比較短)。
- 通過布隆過濾器。查詢緩存之前先去布隆過濾器查詢下這個數據是否存在。如果數據不存在,然后直接返回空。這樣的話也會減少底層系統的查詢壓力。
- 緩存沒有直接返回。這種方式的話要根據自己的實際業務來進行選擇。比如固定的數據,一些省份信息或者城市信息,可以全部緩存起來。這樣的話數據有變化的情況,緩存也需要跟著變化。實現起來可能比較復雜。
緩存擊穿
是指緩存里面的一個熱點key(拼多多的五菱宏光神車的秒殺)在某個時間點過期。針對于這一個key有大量并發請求過來然后都會同時去數據庫請求數據,瞬間對數據庫造成巨大的壓力。這個的話可以用緩存雪崩的幾種解決方法來避免:
- 緩存永不過期。Redis中保存的key永久不失效,這樣的話就不會出現大量緩存同時失效的問題,但是這種做法會浪費更多的存儲空間,一般應該也不會推薦這種做法。
- 異步重建緩存。這樣的話需要維護每個key的過期時間,定時去輪詢這些key的過期時間。例如一個key的value設置的過期時間是30min,那我們可以為這個key設置它自己的一個過期時間為20min。所以當這個key到了20min的時候我們就可以重新去構建這個key的緩存,同時也更新這個key的一個過期時間。
- 互斥鎖重建緩存。這種情況的話只能針對于同一個key的情況下,比如你有100個并發請求都要來取A的緩存,這時候我們可以借助redis分布式鎖來構建緩存,讓只有一個請求可以去查詢DB其他99個(沒有獲取到鎖)都在外面等著,等A查詢到數據并且把緩存構建好之后其他99個請求都只需要從緩存取就好了。原理就跟我們java的DCL(double checked locking)思想有點類似。
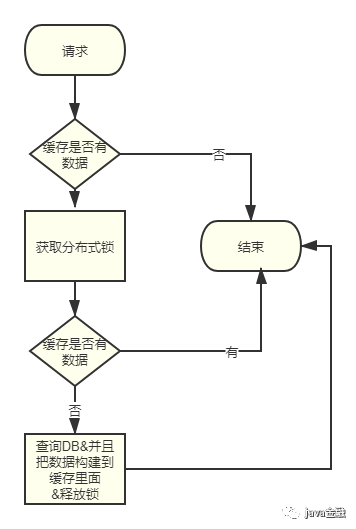
緩存更新
我們一般的緩存更新主要有以下幾種更新策略:
- 先更新緩存,再更新數據庫
- 先更新數據庫,再更新緩存
- 先刪除緩存,再更新數據庫
- 先更新數據源庫,再刪除緩存 至于選擇哪種更新策略的話,沒有絕對的選擇,可以根據自己的業務情況來選擇適合自己的不過一般推薦的話是選擇 「先更新數據源庫,再刪除緩存」。
總結
如果想要真正的設計好一個緩存,我們還是必須要掌握很多的知識,對于不同場景,緩存有各自不同的用法。比如實際工作中我們對于訂單詳情的一個緩存。我們可能會根據訂單的狀態來來構建緩存。我們就以機票訂單為例,已出行、或者已經取消的訂單我們基本上是不會去管的(訂單狀態已經終止了),這種的話數據基本也不會變了,所以對于這種訂單我們設置的過期時間是不是就可以久一點,比如7天或者30天。對于未出行即將起飛的訂單,這時候顧客是不是就會頻繁的去刷新訂單看看,看看有沒有晚點什么的,或者登機口是在哪。對于這種實時性要求比較高的訂單我們過期時間還是要設置的比較短的,如果是需要更改訂單的狀態查詢的時候可以直接不走緩存,直接查詢master庫。畢竟這種更改訂單狀態的操作還是比較有限的。大多數情況都是用來展示的。展示的話是可以允許實時性要求沒那么高。總的來說需要開具體的業務,沒有通用的方案。看你的業務需求的容忍度,畢竟脫離了業務來談技術都是耍流氓,是業務驅動技術。
本文轉載自微信公眾號「 java金融」,可以通過以下二維碼關注。轉載本文請聯系 java金融公眾號。