隱藏彩蛋:你知道python有一個內置的數據庫嗎?
本文轉載自公眾號“讀芯術”(ID:AI_Discovery)。
如果你是軟件開發人員,相信你一定知道甚至曾經使用過一個非常輕量級的數據庫——SQLite。它幾乎擁有作為一個關系數據庫所需的所有功能,而且這些有功能都保存在一個文件中。下面是一些官方網站顯示可以使用SQLite的場景:
- 嵌入式設備和物聯網
- 數據分析
- 數據傳輸
- 文件歸檔和/或數據容器
- 內部或臨時數據庫
- 在演示或測試期間代表企業數據庫
- 教育、培訓和測試
- 實驗性SQL語言擴展
最重要的是,SQLite實際上是作為Python的內置庫,換言之,你不需要安裝任何服務器端/客戶端軟件,也不需要讓某個東西作為服務運行,只要你用Python導入庫并開始編碼,就會有一個關系數據庫管理系統!
輸入與使用
當我們說“內置”時,這意味著你甚至不需要運行pip install來獲取庫。只需通過以下方式導入:
- import sqlite3 as sl
創建到數據庫的連接
不要為驅動程序、連接字符串等煩惱。可以創建一個SQLite數據庫,并擁有一個簡單的連接對象:
- con = sl.connect('my-test.db')
運行這行代碼之后,我們已經創建了數據庫并連接到它。我們要求Python自動連接現有的數據庫,因此它不是空的。否則,我們可以使用完全相同的代碼連接到現有數據庫。

創建表
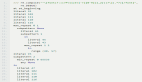
然后創建一個表:
- with con:
- con.execute("""
- CREATE TABLE USER (
- id INTEGER NOT NULL PRIMARYKEY AUTOINCREMENT,
- name TEXT,
- age INTEGER
- );
- """)
在這個用戶表中添加三列。正如你所看到的,SQLite確實是輕量級的,但是它支持常規RDBMS應該具有的所有基本特性,例如數據類型、可為null、主鍵和自動遞增。運行這段代碼之后就已經創建了一個表,盡管它什么也不輸出。
插入記錄
讓我們在剛剛創建的USER表中插入一些記錄,這也可以證明我們確實創建了它。假設要一次性插入多個條目。Python中的SQLite可以輕松實現這一點。
- sql = 'INSERT INTO USER (id, name, age) values(?,?, ?)'
- data = [
- (1, 'Alice', 21),
- (2, 'Bob', 22),
- (3, 'Chris', 23)
- ]
我們需要用問號作為占位符來定義SQL語句。然后,創建一些要插入的示例數據。通過連接對象,插入這些示例行。
- with con:
- con.executemany(sql, data)
運行代碼之后,沒有任何提示,證明我們成功了。
查詢表
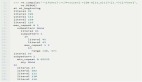
現在,是時候驗證所做的一切了。查詢表以獲取樣本行。
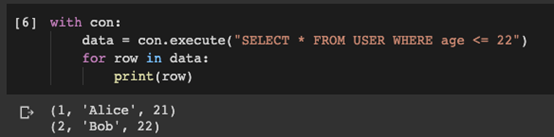
- with con:
- data = con.execute("SELECT *FROM USER WHERE age <= 22")
- for row in data:
- print(row)
另外,盡管SQLite是輕量級的,但是作為一個廣泛使用的數據庫,大多數SQL客戶端軟件都支持使用它。我使用最多的是DBeaver。
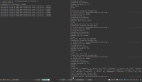
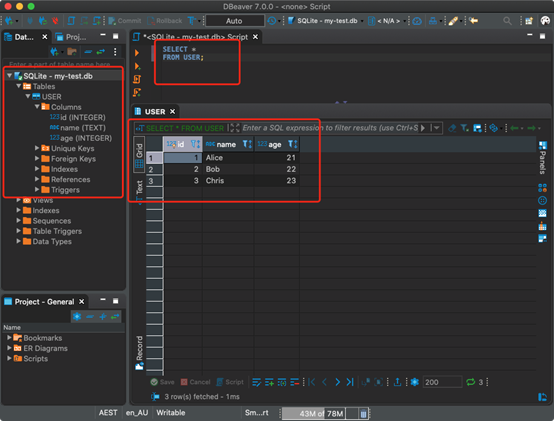
從SQL客戶端(DBeaver)連接到SQLite數據庫
因為我用的是googlecolab,所以要下載- my-test.db測試數據庫文件到本地計算機。在本例中,如果在本地計算機上運行Python,則可以使用SQL客戶機直接連接到數據庫文件。
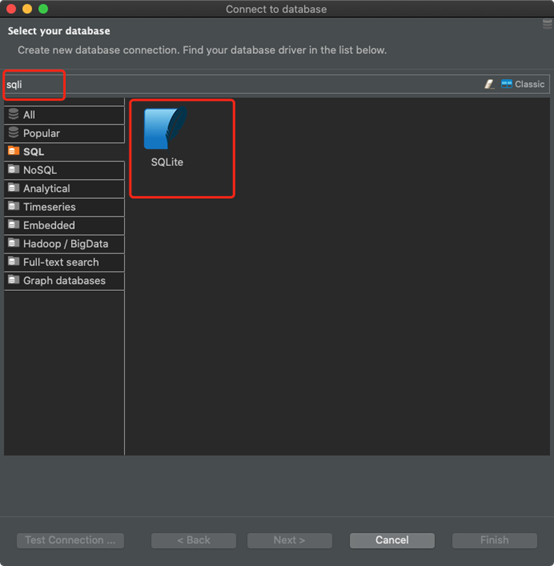
在DBeaver中,創建一個新連接并選擇SQLite作為DB type。
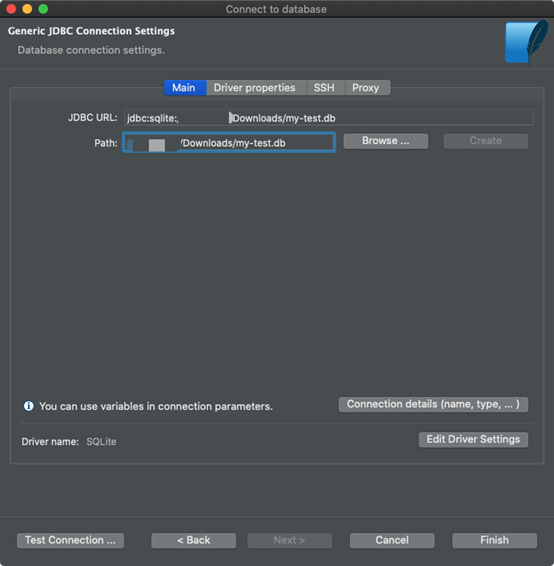
然后,瀏覽到DB文件。
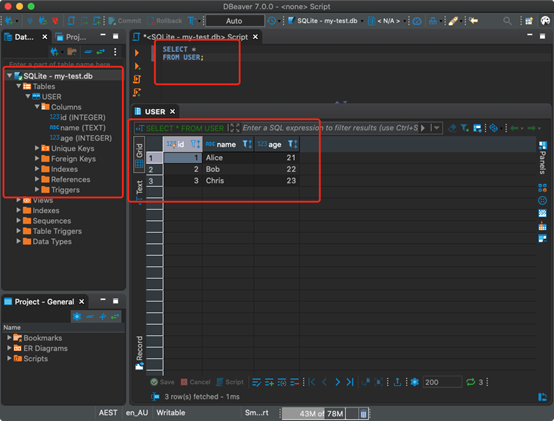
現在,可以在數據庫上運行任何SQL查詢。它與其他常規關系數據庫沒有什么不同。
與Pandas無縫融合
事實上,作為Python的一個內置特性,SQLite還可以與Pandas數據幀無縫集成。
定義一個數據幀:
- df_skill = pd.DataFrame({
- 'user_id': [1,1,2,2,3,3,3],
- 'skill': ['Network Security','Algorithm Development', 'Network Security', 'Java', 'Python', 'Data Science','Machine Learning']
- })
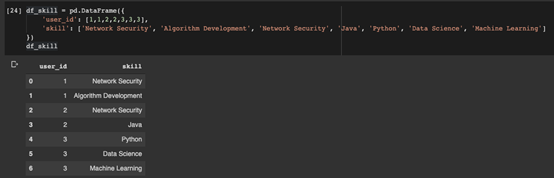
然后,可以簡單地調用數據幀的to_sql()方法將其保存到數據庫中。
- df_skill.to_sql('SKILL', con)
就這樣,我們甚至不需要預先創建表,列的數據類型和長度都會被推斷出來。當然,如果你想的話,仍然可以事先定義它。
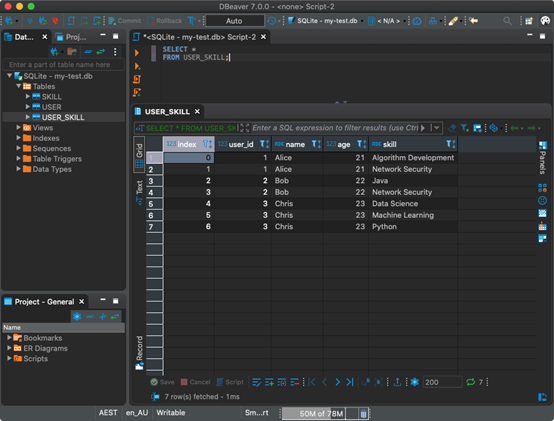
然后,假設我們要連接表USER和SKILL,并將結果讀入Pandas數據框。它也是無縫的。
- df = pd.read_sql('''
- SELECT s.user_id, u.name, u.age,s.skill
- FROM USER u LEFT JOIN SKILL s ON u.id= s.user_id
- ''', con)
讓我們把結果寫到一個名為USER_SKILL的新表中:
- df.to_sql('USER_SKILL', con)
然后,還可以使用SQL客戶機檢索表。
本文介紹了如何使用Python內置庫sqlite3在SQLite數據庫中創建和操作表。當然,它也支持更新和刪除,你可以自己嘗試一下。
最重要的是,我們可以輕松地將表從SQLite數據庫讀入Pandas數據幀,反之亦然。這使我們能夠更容易地與輕量級關系數據庫進行交互。此外,SQLite沒有身份驗證,因為一切都需要是輕量級的。
Python中隱藏著許多驚喜。它們并不是故意藏起來,只是因為Python中存在太多現成的特性以至于人們無法發現。去探索Python中更多令人驚訝的特性,享受它們吧!