













實(shí)時(shí)犯罪警報(bào):且看深度學(xué)習(xí)如何保護(hù)你的安危
本文轉(zhuǎn)載自公眾號(hào)“讀芯術(shù)”(ID:AI_Discovery)。
在美國(guó)各大主要城市,市民一天24小時(shí)會(huì)切到數(shù)千個(gè)公共第一響應(yīng)者無(wú)線電波,這些信息用于給500多萬(wàn)用戶提供火災(zāi)、搶劫和失蹤等突發(fā)事件的實(shí)時(shí)安全警報(bào)。每天人們收聽音頻的總時(shí)長(zhǎng)會(huì)超過(guò)1000小時(shí),這給需要開發(fā)新城市的公司帶來(lái)了挑戰(zhàn)。
因此,我們構(gòu)建了一個(gè)機(jī)器學(xué)習(xí)模型,它可以從音頻中捕捉到重大安全事故的信息。

定制的軟件適用無(wú)線電(SDR)會(huì)捕捉大范圍內(nèi)的無(wú)線電頻率(RF),將優(yōu)化后的音頻片段發(fā)送到ML模型進(jìn)行標(biāo)記。標(biāo)記后的片段會(huì)被發(fā)送至操作分析員,他們將在app中記錄事件,最后通知事故地點(diǎn)附近的用戶。
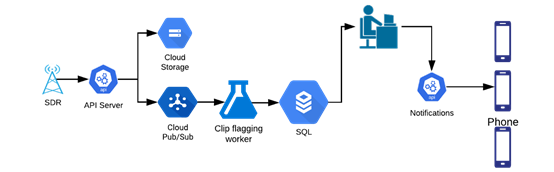
安全警報(bào)工作流程(圖自作者)
為適應(yīng)問(wèn)題領(lǐng)域,調(diào)整一個(gè)公共語(yǔ)音轉(zhuǎn)文本引擎
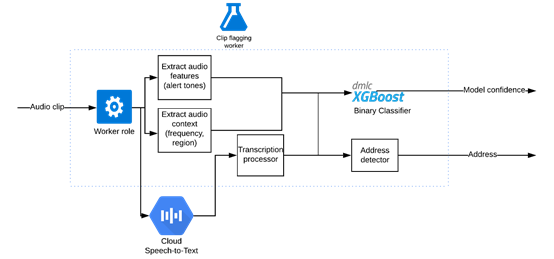
運(yùn)用公共語(yǔ)音轉(zhuǎn)文本引擎的剪輯分類器 (圖自作者)
依據(jù)單詞錯(cuò)誤率(WER),我們將從一個(gè)性能最好的語(yǔ)音轉(zhuǎn)文本引擎著手。很多警察使用的特殊代碼都不是白話,例如,紐約警察局官員會(huì)發(fā)送“信號(hào)13”來(lái)請(qǐng)求后備部隊(duì)。
我們使用語(yǔ)音上下文定制詞匯表。為適應(yīng)領(lǐng)域,我們還擴(kuò)充了一些詞匯,例如,“assault”并不通俗,但常見于領(lǐng)域中,模型應(yīng)檢測(cè)出“assault”而不是“a salt”。
調(diào)整參數(shù)之后,我們能夠在一些城市獲得相對(duì)準(zhǔn)確的轉(zhuǎn)錄。接下來(lái),我們要使用音頻片段的轉(zhuǎn)錄數(shù)據(jù),找出哪些與市民相關(guān)。
基于轉(zhuǎn)錄和音頻特征的二值分類器
我們建立了一個(gè)二進(jìn)制分類問(wèn)題的模型,其中轉(zhuǎn)錄作為輸入,置信水平作為輸出,XGBoost算法為數(shù)據(jù)集提供了最好的性能。
我們從一位前執(zhí)法部門工作人員處了解到,在重大事件的無(wú)線電廣播之前,一些城市會(huì)發(fā)出特殊警報(bào)音以引起當(dāng)?shù)鼐降淖⒁狻_@個(gè)“額外”的特征使我們的模型更加可靠,尤其是在轉(zhuǎn)錄出錯(cuò)的情況下。其他一些有用的特征是警察頻道和傳輸ID。
我們?cè)诓僮髁鞒讨袑?duì)ML模型進(jìn)行了測(cè)試。運(yùn)行了幾天后,我們注意到在事件中,那些只使用帶了模型標(biāo)記的片段的分析員未出差錯(cuò)。
我們?cè)趲讉€(gè)城市推出了這種模式。現(xiàn)在一個(gè)分析師可以同時(shí)處理多個(gè)城市的音頻,這在以前是不可能的。隨著投入運(yùn)營(yíng)的閑置產(chǎn)能增多,我們得以開發(fā)新的城市。
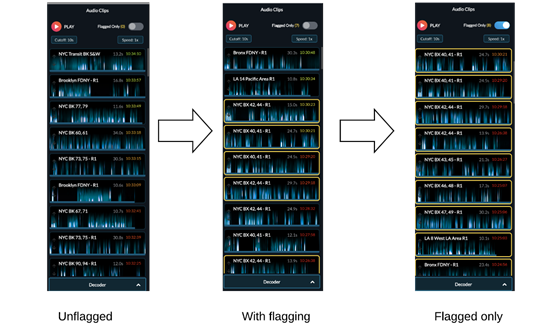
模型的推出顯著減少了分析員的音頻量(圖自作者)
超越公共語(yǔ)音轉(zhuǎn)文本引擎
這個(gè)模型并不是解決所有問(wèn)題的靈丹妙藥,我們只能在少數(shù)幾個(gè)音質(zhì)好的城市使用它。公共語(yǔ)音轉(zhuǎn)文本引擎是按照聲學(xué)剖面不同于收音機(jī)的音素模型訓(xùn)練的,因此,轉(zhuǎn)錄的質(zhì)量有時(shí)是不可靠的。對(duì)于那些非常嘈雜的老式模擬系統(tǒng)來(lái)說(shuō),轉(zhuǎn)錄是完全不可用的。
我們嘗試了多個(gè)來(lái)源的多個(gè)模型,但沒有一個(gè)是按照與數(shù)據(jù)集相似的聲學(xué)剖面訓(xùn)練的,全都無(wú)法處理嘈雜的音頻。
我們?cè)囍迷诒WC管道其他部分不變的情況下由數(shù)據(jù)訓(xùn)練出的語(yǔ)音轉(zhuǎn)文本引擎,替換原語(yǔ)音轉(zhuǎn)文本引擎。然而,為了音頻,我們需要幾百小時(shí)的轉(zhuǎn)錄數(shù)據(jù),而生成這些數(shù)據(jù)耗時(shí)耗財(cái)。
我們還有個(gè)優(yōu)化過(guò)程的選擇,就是只抄寫詞匯表中定義為“重要”的單詞,并為不相關(guān)的單詞添加空格,但這仍然只是在逐步減少工作量而已。最后,我們決定為問(wèn)題領(lǐng)域建立一個(gè)定制的語(yǔ)音處理管道。
用于關(guān)鍵詞識(shí)別的卷積神經(jīng)網(wǎng)絡(luò)
因?yàn)槲覀冎魂P(guān)心關(guān)鍵字,所以并不需要知道單詞正確的順序,由此可簡(jiǎn)化問(wèn)題為關(guān)鍵字識(shí)別。這就簡(jiǎn)單多了,我們決定使用在數(shù)據(jù)集上訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)(CNN)。
在循環(huán)神經(jīng)網(wǎng)絡(luò)(RNNs)或長(zhǎng)短期記憶(LSTM)模型之上使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)意味著我們可以更快地訓(xùn)練和重復(fù)。我們?cè)u(píng)估了Transformer模型,其大致相同,但需要大量硬件才能運(yùn)行。
由于我們只在音頻段之間尋找短期的依賴關(guān)系來(lái)檢測(cè)單詞,計(jì)算簡(jiǎn)單的CNN似乎優(yōu)于Transformer模型,同時(shí)它能騰出硬件空間,從而可以通過(guò)超參數(shù)調(diào)整更加靈活。
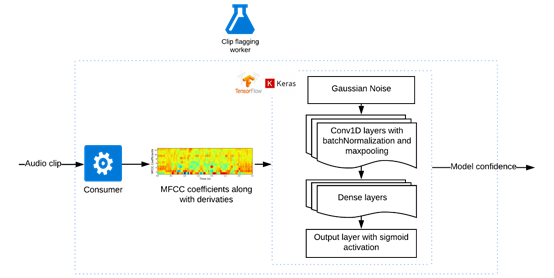
用于識(shí)別關(guān)鍵字并運(yùn)用了卷積神經(jīng)網(wǎng)絡(luò)的剪輯標(biāo)記模型(圖自作者)
音頻片段會(huì)被分成固定時(shí)長(zhǎng)的子片段。如果詞匯表中的一個(gè)單詞出現(xiàn)了,該子片段會(huì)被加上一個(gè)正標(biāo)簽。然后,如果在某個(gè)片段中發(fā)現(xiàn)任何這樣的子片段,該音頻片段會(huì)被標(biāo)記為有用。
在訓(xùn)練過(guò)程中,我們嘗試改變子片段的時(shí)長(zhǎng)以判斷其如何影響融合性能。長(zhǎng)的片段讓模型更難確定片段的哪個(gè)部分會(huì)有用,也讓模型更難調(diào)試。短片段意味著部分單詞會(huì)出現(xiàn)在多個(gè)剪輯中,這使得模型更難識(shí)別出它們。調(diào)整這個(gè)超參數(shù)并找到一個(gè)合理的時(shí)長(zhǎng)是能做到的。
對(duì)于每個(gè)子片段,我們將音頻轉(zhuǎn)換成梅爾倒譜系數(shù)(MFCC),并添加一階和二階導(dǎo)數(shù),特征以25ms的幀大小和10ms的步幅生成。然后,通過(guò)Tensorflow后端輸入到基于Keras序列模型的神經(jīng)網(wǎng)絡(luò)中。
第一層是高斯噪聲,這使得模型耐得住不同無(wú)線信道之間的噪聲差異。我們嘗試了另一種方法,人為地將真實(shí)的噪音疊加到片段上,但這大大放緩了訓(xùn)練,卻沒有顯著的性能提升。
然后,我們添加了Conv1D、BatchNormalization和MaxPooling1D三個(gè)后續(xù)層。批處理規(guī)范化有助于模型收斂,最大池化有助于使模型耐得住語(yǔ)音和信道噪聲的細(xì)微變化。另外,我們?cè)囍黾恿嗣撀鋵樱@些脫落層并未有效改進(jìn)模型。
最后,添加一個(gè)密集連接的神經(jīng)網(wǎng)絡(luò)層,將其注入到一個(gè)有著sigmoid函數(shù)激活的單一輸出密集層。
生成標(biāo)記數(shù)據(jù)
音頻剪輯的標(biāo)記過(guò)程(圖自作者)
為了標(biāo)記訓(xùn)練數(shù)據(jù),我們把問(wèn)題領(lǐng)域的關(guān)鍵字列給了注釋者,并要求他們?nèi)绻性~匯表里的單詞出現(xiàn),必須為片段標(biāo)記好開始和結(jié)束位置和單詞標(biāo)簽。
為了確保注釋的可靠性,我們?cè)谧⑨屍髦g有10%的重疊,并計(jì)算了它們?cè)谥丿B片段上的表現(xiàn)。一旦有了大約50小時(shí)的標(biāo)記數(shù)據(jù)就會(huì)啟動(dòng)訓(xùn)練,我們會(huì)在重復(fù)訓(xùn)練的過(guò)程中不斷收集數(shù)據(jù)。
由于詞匯表中的一些單詞比另一些單詞更為常見,模型針對(duì)于普通單詞來(lái)說(shuō)表現(xiàn)正常,但是對(duì)于僅有較少示例的單詞卻遇到了困難。
我們?cè)噲D將單字發(fā)音覆蓋在其他片段中,借以人為制造示例。然而,性能的提升與這些單詞的實(shí)際標(biāo)記量不相稱。最終,模型對(duì)于常用詞等會(huì)更加敏感,我們?cè)谖幢粯?biāo)記的音頻片段上運(yùn)行該模型,并消除掉那些含有已習(xí)得單詞的片段,這有助于減少未來(lái)標(biāo)記時(shí)多余的詞語(yǔ)。
模型的發(fā)行
經(jīng)過(guò)幾次重復(fù)的數(shù)據(jù)收集和超參數(shù)調(diào)整,我們已能訓(xùn)練出一個(gè)對(duì)詞匯表里的詞語(yǔ)具有高查全率和精準(zhǔn)捕捉能力的模型。高查全率對(duì)于捕捉關(guān)鍵的安全警報(bào)非常重要。標(biāo)記的片段會(huì)在發(fā)送警報(bào)之前被收聽,因此誤報(bào)不是一個(gè)大問(wèn)題。
我們?cè)诩~約市的一些區(qū)對(duì)這個(gè)模型進(jìn)行了測(cè)試,該模型能夠?qū)⒁纛l音量降低50–75%(取決于頻道),它明顯超越了我們?cè)诠舱Z(yǔ)音轉(zhuǎn)文本引擎上訓(xùn)練的模型,因?yàn)榧~約由于模擬系統(tǒng)有非常嘈雜的音頻。
令人驚訝的是,盡管模型是根據(jù)紐約市的數(shù)據(jù)訓(xùn)練的,但它也可以很好地切換到芝加哥的音頻。在收集了幾個(gè)小時(shí)的芝加哥片段之后,從紐約市模型中學(xué)到的東西轉(zhuǎn)移到芝加哥,該模型也表現(xiàn)良好。
圖源:unsplash
語(yǔ)音處理管道與定制的深度神經(jīng)網(wǎng)絡(luò)廣泛適用于來(lái)自美國(guó)主要城市的警察音頻。它從音頻中發(fā)現(xiàn)了重大的安全事故,使全國(guó)范圍的市民能夠迅速向城市廣播,履行保護(hù)社區(qū)安全的使命。
在RNN、LSTM或Transformer中選擇計(jì)算簡(jiǎn)單的CNN架構(gòu),以及簡(jiǎn)化標(biāo)記過(guò)程,這些都是重大的突破,使我們能在限時(shí)限材的情況下超越公共語(yǔ)音轉(zhuǎn)文本模型。




















