你知道深度學(xué)習(xí)為什么叫做深度學(xué)習(xí)嗎?
這是一篇單純的推送,今天我們單純來聊一聊深度學(xué)習(xí)這個名字。
深度學(xué)習(xí)的復(fù)蘇,可以從2012算起,那一年,深度學(xué)習(xí)網(wǎng)絡(luò)AlexNet橫空出世,在ImageNet競賽中取得了冠軍,到了2016年,Alpha Go的勝利將深度學(xué)習(xí)推到了我們每一個人的面前。
但是,今天膾炙人口的深度學(xué)習(xí),其實,從學(xué)習(xí)方式上來說,和存在了幾十年的神經(jīng)網(wǎng)絡(luò)并沒有什么區(qū)別。
所以,到底為什么神經(jīng)網(wǎng)絡(luò)突然就變成了深度學(xué)習(xí)?
well,用吳恩達的話來說,深度學(xué)習(xí)是神經(jīng)網(wǎng)絡(luò)的一種re-branding,這個名字,至少聽上去,很有……深度……
wow, deep learning, it sounds so deep……
那么,深度學(xué)習(xí)的本質(zhì)變了嗎?
沒有,變的只是數(shù)據(jù)量和計算力。
Like it or not, 目前在復(fù)雜的任務(wù)中達到人類水平的學(xué)習(xí)算法,與上世紀80年代努力解決玩具問題(toy example)的學(xué)習(xí)算法幾乎是一樣的。
這可不是我瞎掰,這是AI圣經(jīng)花書里的原話。

AI圣經(jīng) —— “花書”
真正變革的,是我們有了這些算法得以成功訓(xùn)練所需的資源 —— 數(shù)據(jù)量和計算力。
然而,深度就一定那么好?
不一定。
這個問題可以從兩方面來看,第一,一味的增加網(wǎng)絡(luò)的深度是不好的。太深的網(wǎng)絡(luò)不好訓(xùn)練!太深的網(wǎng)絡(luò)不好訓(xùn)練!太深的網(wǎng)絡(luò)不好訓(xùn)練!
第二,一定要追究起來,其實網(wǎng)絡(luò)的深度和寬度都是好的,這個道理非常簡單,一個機器學(xué)習(xí)模型,模型的復(fù)雜度越高,(理論上)模型的學(xué)習(xí)能力就越強。這就好比說,使用更多的變量,你就能表達出更復(fù)雜的公式。從這個角度出發(fā),一個神經(jīng)網(wǎng)絡(luò)無論是變的更深了,還是更寬了,模型的復(fù)雜度都是提升了。
這是很自然的一種想法,所以在深度學(xué)習(xí)的發(fā)展過程中,也出現(xiàn)了這樣兩種風格的經(jīng)典網(wǎng)絡(luò)。
一種看上去很深,比如網(wǎng)絡(luò)層數(shù)達到了152層的ResNet:
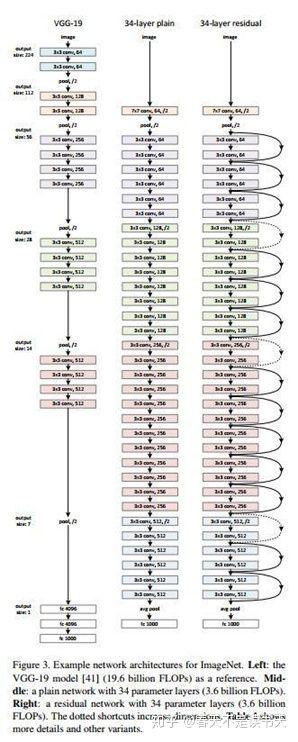
看上去很深的ResNet
還有一種看上去很胖(很寬),比如使用了Inception模塊的Inception網(wǎng)絡(luò)家族。
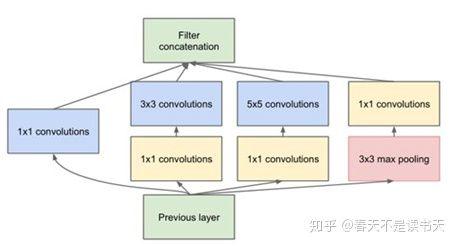
變寬了的Inception模塊
這都是好用的網(wǎng)絡(luò)結(jié)構(gòu),甚至還有結(jié)合了兩者之大成的網(wǎng)絡(luò):Inception-ResNet。
這樣一種聽上去就很復(fù)雜的網(wǎng)絡(luò)的結(jié)構(gòu)確實……也很龐大,這里就不放出來了。
當然,這樣一種深度和寬度的拓展,所要用到的計算資源也是杠杠的。
而在資源有限的情況下,深度比寬度更好,這就涉及到了直擊深度的靈魂問題 ——
深度到底是在做什么
學(xué)習(xí)!一種隨著網(wǎng)絡(luò)層的深入而進行的學(xué)習(xí)。這種學(xué)習(xí)有個專業(yè)術(shù)語叫做特征學(xué)習(xí),或者表示學(xué)習(xí)。
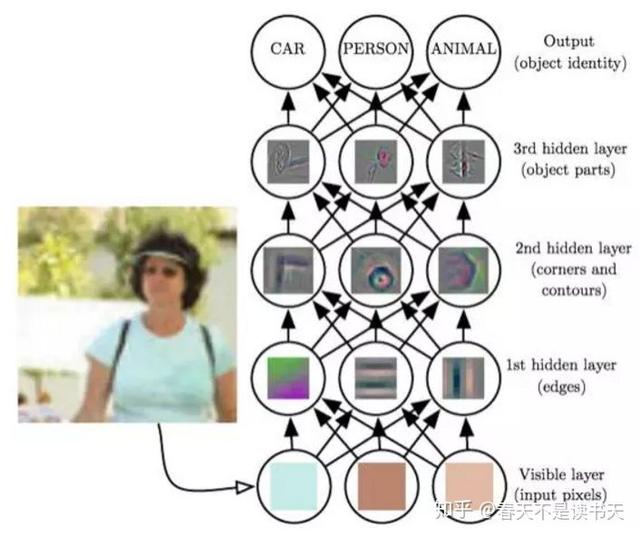
《深度學(xué)習(xí)》一書中關(guān)于網(wǎng)絡(luò)學(xué)習(xí)的例子
一個深度學(xué)習(xí)網(wǎng)絡(luò)有很多層,當我們將一張圖像送進網(wǎng)絡(luò),首先在最底層,好像我們看到的是像素一類的東西,一層層往上,網(wǎng)絡(luò)層“看到了”邊緣、輪廓、部件等等,網(wǎng)絡(luò)的深度,帶來的是逐層抽象的能力,所以有了深度的網(wǎng)絡(luò)有了學(xué)習(xí)的能力,和寬度所帶來的比較單純的計算力的上升,深度當然是更符合學(xué)習(xí)型模型的結(jié)構(gòu)。
當然這只是一個示意,實際情況下神經(jīng)網(wǎng)絡(luò)的分層是比較模糊的,而中間網(wǎng)絡(luò)層的輸出還是相對比較抽象的概念,很難說清楚哪一些網(wǎng)絡(luò)層就”看到了“什么特征。但是總體上當我們逐漸往上的時候,網(wǎng)絡(luò)確實是不斷在對對象進行抽象。而這是寬度所不能夠帶來的能力。所以,我們有深度學(xué)習(xí),而不是寬度學(xué)習(xí)。
要說在一開始,深度學(xué)習(xí)或許只是一個好聽的名字,但是到了今天,我們所用到的和看到的網(wǎng)絡(luò)確實越來越深了。2012年令人矚目的AlexNet不過8層,而到了 2015 年,殘差的方式使訓(xùn)練一個很深的神經(jīng)網(wǎng)絡(luò)成為現(xiàn)實,Resnet的網(wǎng)絡(luò)深度直接到達了152層,到了 2016 年,ImageNet競賽的冠軍已經(jīng)用上了 1207層的網(wǎng)絡(luò)了。
深度學(xué)習(xí),真是深得叫你心服口服。