如何做一個(gè)好的大數(shù)據(jù)平臺(tái)架構(gòu)
一、Lambda架構(gòu)需求

Lambda架構(gòu)背后的需求是由于MR架構(gòu)的延遲問題。MR雖然實(shí)現(xiàn)了分布式、可擴(kuò)展數(shù)據(jù)處理系統(tǒng)的目的,但是在處理數(shù)據(jù)時(shí)延遲比較嚴(yán)重。實(shí)際上如果內(nèi)存和CPU足夠強(qiáng)大,MR也可以實(shí)現(xiàn)近實(shí)時(shí)運(yùn)算,但實(shí)際業(yè)務(wù)環(huán)境并非如此,因此我們需要權(quán)衡,選擇實(shí)時(shí)處理和批處理所需要數(shù)據(jù)量和恰當(dāng)?shù)馁Y源。
2012年Storm的作者Nathan Marz提出的Lambda數(shù)據(jù)處理框架。Lambda架構(gòu)的目標(biāo)是設(shè)計(jì)出一個(gè)能滿足實(shí)時(shí)大數(shù)據(jù)系統(tǒng)關(guān)鍵特性的架構(gòu),包括有:高容錯(cuò)、低延時(shí)和可擴(kuò)展等。Lambda架構(gòu)整合離線計(jì)算和實(shí)時(shí)計(jì)算,融合不可變性(Immunability),讀寫分離和復(fù)雜性隔離等一系列架構(gòu)原則,可集成Hadoop,Kafka,Storm,Spark,Hbase等各類大數(shù)據(jù)組件。
二、Lambda架構(gòu)的關(guān)鍵
橫向擴(kuò)容
可擴(kuò)展性意味著為滿足日益增長(zhǎng)的用戶服務(wù)需求,同時(shí)不用對(duì)底層架構(gòu)或者代碼,可以通過現(xiàn)有機(jī)器添加內(nèi)存或者磁盤資源來實(shí)現(xiàn)(垂直擴(kuò)展),或者可以通過在集群中添加機(jī)器實(shí)現(xiàn)(水平擴(kuò)展)。無論是實(shí)時(shí)或者批處理,都應(yīng)該能夠不停服務(wù)的情況下,可以實(shí)施水平擴(kuò)展。
故障容錯(cuò)
系統(tǒng)需要妥善處理故障,確保系統(tǒng)在某些組件發(fā)生故障的情況下,整個(gè)系統(tǒng)服務(wù)的可用性。可能部分組件故障會(huì)導(dǎo)致集群中部分節(jié)點(diǎn)宕機(jī),影響了整理的SLA,但是系統(tǒng)還是可以相應(yīng)的,系統(tǒng)不能有單點(diǎn)故障。
低延遲
很多應(yīng)用對(duì)于讀和寫操作的延時(shí)要求非常高,要求對(duì)更新和查詢的響應(yīng)是低延時(shí)的。
可擴(kuò)展
系統(tǒng)需要足夠靈活,能夠?qū)崿F(xiàn)新增和修改需求,又不需要重構(gòu)整個(gè)系統(tǒng)。實(shí)時(shí)處理和批處理隔離開,能夠靈活修改需求。
易維護(hù)
開發(fā)部署不能夠太復(fù)雜。
三、Lambda架構(gòu)的分層
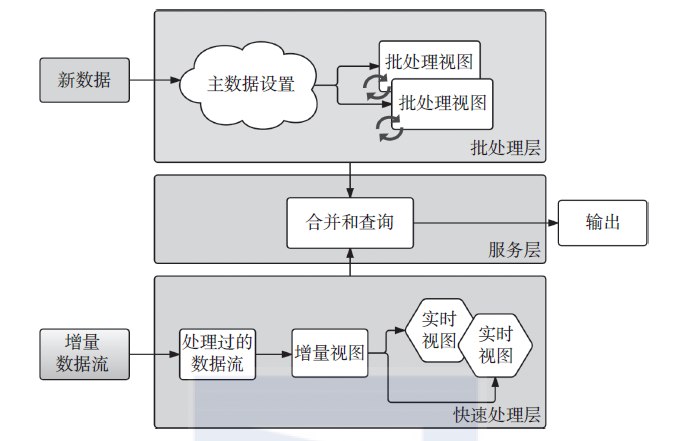
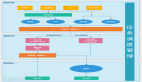
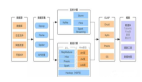
在Lambda架構(gòu)中新數(shù)據(jù)到達(dá)時(shí),會(huì)被同時(shí)分派到批處理層和快速處理層。一旦數(shù)據(jù)到達(dá)批處理層,按照常規(guī)批處理時(shí)間間隔,每次都從頭開始重新計(jì)算并生成批處理視圖。類似地,只要新數(shù)據(jù)到達(dá)快速處理層,快速處理層就會(huì)使用新數(shù)據(jù)生成快速視圖。在查詢到達(dá)服務(wù)層時(shí),它會(huì)合并快速視圖和批處理視圖來生成適當(dāng)?shù)牟樵兘Y(jié)果。生成批處理視圖后,快速視圖將被丟棄,除非有新數(shù)據(jù)抵達(dá),否則只需要查詢批處理視圖,因?yàn)榇藭r(shí)批處理層中擁有所有的數(shù)據(jù)。
Lambda架構(gòu)定義主要層以及每個(gè)組件之間的集成。注意分為以下層:
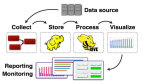
數(shù)據(jù)源
數(shù)據(jù)源指外部的數(shù)據(jù)庫(kù)、消息隊(duì)列、文件等,可以開發(fā)數(shù)據(jù)消費(fèi)層,隱藏來自不同訪問數(shù)據(jù)的復(fù)雜性,定義好數(shù)據(jù)格式。
數(shù)據(jù)消費(fèi)層
負(fù)責(zé)封裝不能數(shù)據(jù)源獲取數(shù)據(jù)的復(fù)雜性,將其轉(zhuǎn)換可由批處理或者流處理進(jìn)一步使用同一的格式進(jìn)行消費(fèi)。
批處理層
這是Lambda架構(gòu)核心層之一,批處理接受數(shù)據(jù),持久化到用戶定義好的數(shù)據(jù)結(jié)構(gòu)中,維護(hù)著主數(shù)據(jù)。數(shù)據(jù)結(jié)構(gòu)一般不做改變,只是追加數(shù)據(jù)。批處理還負(fù)責(zé)創(chuàng)建和維護(hù)批處理視圖。比如我們常做的Hive ETL ,統(tǒng)計(jì)一些數(shù)據(jù),最后將結(jié)果保存在hive表中,或者數(shù)據(jù)庫(kù)中,就屬于批處理層。
實(shí)時(shí)層
這是Lambda另一個(gè)核心層。批處理在很多場(chǎng)景下能夠滿足需求,但是隨著業(yè)務(wù)需求“苛刻性”,他們希望能夠及時(shí)看到數(shù)據(jù),而不是等到第二天才看指標(biāo)變化和分析結(jié)果。所以引入了實(shí)時(shí)處理。實(shí)時(shí)層解決了一個(gè)問題,即只存儲(chǔ)可立即向用戶提供的一組數(shù)據(jù),這樣就不需要對(duì)全量數(shù)據(jù)進(jìn)行處理,大大提供處理效率。比如流處理僅僅存儲(chǔ)最近5分鐘的數(shù)據(jù),處理計(jì)算并形成結(jié)果,這就是我們用spark streaming中要有的時(shí)間窗口。
服務(wù)層
這是Lambda架構(gòu)的最后一層,服務(wù)層的職責(zé)是獲取批處理和流處理的結(jié)果,向用戶提供統(tǒng)一查詢視圖服務(wù)。
四、Lambda架構(gòu)總結(jié)
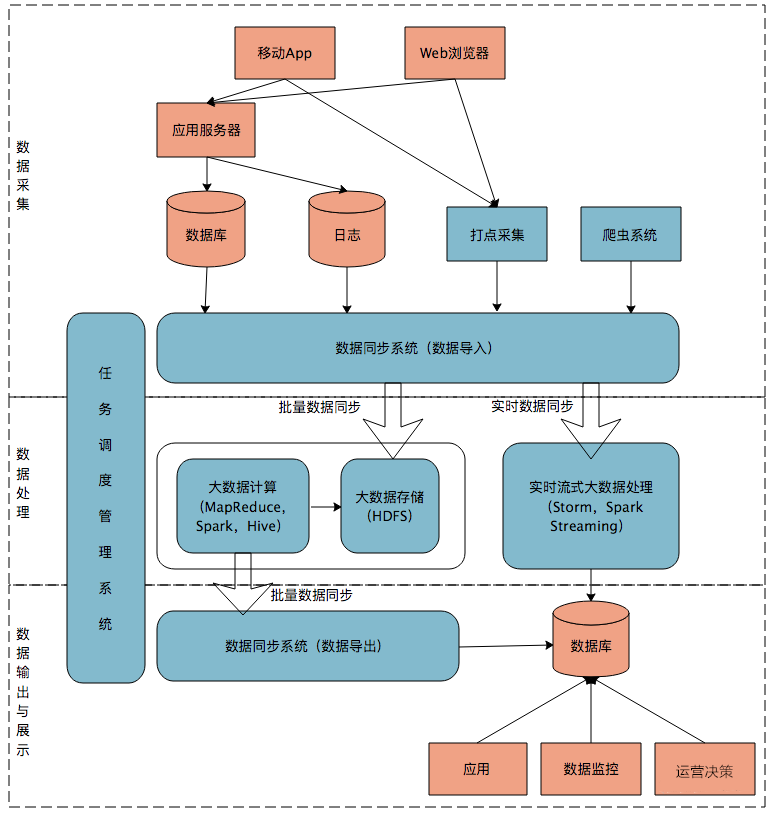
Lambda數(shù)據(jù)架構(gòu)曾經(jīng)成為每一個(gè)公司大數(shù)據(jù)平臺(tái)必備的架構(gòu),它解決了一個(gè)公司大數(shù)據(jù)批量離線處理和實(shí)時(shí)數(shù)據(jù)處理的需求。
數(shù)據(jù)從底層的數(shù)據(jù)源開始,經(jīng)過各種各樣的格式進(jìn)入大數(shù)據(jù)平臺(tái),在大數(shù)據(jù)平臺(tái)中經(jīng)過Kafka、Flume等數(shù)據(jù)組件進(jìn)行收集,然后分成兩條線進(jìn)行計(jì)算。一條線是進(jìn)入流式計(jì)算平臺(tái)(例如 Storm、Flink或者Spark Streaming),去計(jì)算實(shí)時(shí)的一些指標(biāo);另一條線進(jìn)入批量數(shù)據(jù)處理離線計(jì)算平臺(tái)(例如Mapreduce、Hive,Spark SQL),去計(jì)算T+1的相關(guān)業(yè)務(wù)指標(biāo),這些指標(biāo)需要隔日才能看見。
Lambda架構(gòu)經(jīng)歷多年的發(fā)展,非常穩(wěn)定,對(duì)于實(shí)時(shí)計(jì)算部分的計(jì)算成本可控,批量處理可以用晚上的時(shí)間來整體批量計(jì)算,這樣把實(shí)時(shí)計(jì)算和離線計(jì)算高峰分開,這種架構(gòu)支撐了數(shù)據(jù)行業(yè)的早期發(fā)展,但是它也有一些致命缺點(diǎn):
實(shí)時(shí)與批量計(jì)算結(jié)果不一致
因?yàn)榕亢蛯?shí)時(shí)計(jì)算走的是兩個(gè)計(jì)算框架和計(jì)算程序,算出的結(jié)果往往不同,經(jīng)常看到一個(gè)數(shù)字當(dāng)天看是一個(gè)數(shù)據(jù),第二天看昨天的數(shù)據(jù)反而發(fā)生了變化。
批處理的健壯性
隨著數(shù)據(jù)量級(jí)越來越大,經(jīng)常發(fā)現(xiàn)夜間只有4、5個(gè)小時(shí)的時(shí)間窗口,已經(jīng)無法完成白天20多個(gè)小時(shí)累計(jì)的數(shù)據(jù),保證早上上班前準(zhǔn)時(shí)出數(shù)據(jù)已成為每個(gè)大數(shù)據(jù)團(tuán)隊(duì)頭疼的問題,同時(shí)做個(gè)任務(wù)并行執(zhí)行對(duì)于大數(shù)據(jù)集群的穩(wěn)定性也是巨大的考驗(yàn),經(jīng)常會(huì)有任務(wù)因?yàn)橘Y源不足沒有定時(shí)啟動(dòng)或者報(bào)錯(cuò)。
開發(fā)和維護(hù)的復(fù)雜
Lambda 架構(gòu)中對(duì)同樣的業(yè)務(wù)邏輯進(jìn)行兩次編程:一次為批量計(jì)算的ETL系統(tǒng),一次為流式計(jì)算的Streaming系統(tǒng)。針對(duì)同一個(gè)業(yè)務(wù)問題產(chǎn)生了兩個(gè)代碼庫(kù),各有不同的漏洞。
存儲(chǔ)增長(zhǎng)快
數(shù)據(jù)倉(cāng)庫(kù)的設(shè)計(jì)不合理,會(huì)產(chǎn)生大量的中間結(jié)果表,造成數(shù)據(jù)急速膨脹,加大服務(wù)器存儲(chǔ)壓力。比如我們經(jīng)常糾結(jié)于數(shù)據(jù)倉(cāng)庫(kù)到底怎么分層,是直接ODS層到應(yīng)用呢?還是ODS層要景觀DWS、DW等,最后才到應(yīng)用呢?
Lambda架構(gòu)雖然有缺點(diǎn),但是在很多公司依然適用,有時(shí)候我們沒有那么大的業(yè)務(wù)量,實(shí)時(shí)業(yè)務(wù)需求并沒有那么明顯,用著Lambda架構(gòu)依然很爽。對(duì)于超大數(shù)據(jù)量的業(yè)務(wù)或者實(shí)時(shí)業(yè)務(wù)同樣多的情況,可以探索改良Lambda,業(yè)內(nèi)也提出了Kappa架構(gòu),感興趣的小伙伴可以搜索學(xué)習(xí)下。
作者:數(shù)據(jù)社 專注MPP數(shù)據(jù)庫(kù)研究、流處理計(jì)算、數(shù)據(jù)倉(cāng)庫(kù)架構(gòu)和數(shù)據(jù)分析