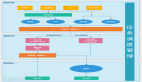
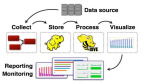
大數(shù)據(jù)平臺架構(gòu)及主流技術(shù)棧
互聯(lián)網(wǎng)和移動(dòng)互聯(lián)網(wǎng)技術(shù)開啟了大規(guī)模生產(chǎn)、分享和應(yīng)用數(shù)據(jù)的大數(shù)據(jù)時(shí)代。面對如此龐大規(guī)模的數(shù)據(jù),如何存儲?如何計(jì)算?各大互聯(lián)網(wǎng)巨頭都進(jìn)行了探索。Google的三篇論文 GFS(2003),MapReduce(2004),Bigtable(2006)為大數(shù)據(jù)技術(shù)奠定了理論基礎(chǔ)。隨后,基于這三篇論文的開源實(shí)現(xiàn)Hadoop被各個(gè)互聯(lián)網(wǎng)公司廣泛使用。在此過程中,無數(shù)互聯(lián)網(wǎng)工程師基于自己的實(shí)踐,不斷完善和豐富Hadoop技術(shù)生態(tài)。經(jīng)過十幾年的發(fā)展,如今的大數(shù)據(jù)技術(shù)生態(tài)已相對成熟,圍繞大數(shù)據(jù)應(yīng)用搭建的平臺架構(gòu)和技術(shù)選型也逐漸趨向統(tǒng)一。
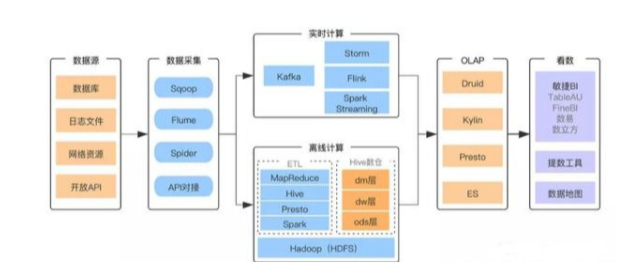
數(shù)據(jù)采集
“巧婦難為無米之炊”,沒有數(shù)據(jù)也就沒有后面的一切,數(shù)據(jù)采集作為基礎(chǔ)至關(guān)重要。采集的數(shù)據(jù)主要由業(yè)務(wù)系統(tǒng)產(chǎn)生,包括存儲在關(guān)系型DB中的結(jié)構(gòu)化數(shù)據(jù)和記錄在日志文件中的半結(jié)構(gòu)化數(shù)據(jù)。Sqoop用于從關(guān)系型DB中采集數(shù)據(jù),F(xiàn)lume用于日志采集。實(shí)時(shí)計(jì)算由于對時(shí)效性要求比較高,它一般采用Kafka和業(yè)務(wù)系統(tǒng)建立實(shí)時(shí)數(shù)據(jù)通道,完成數(shù)據(jù)傳輸。
Sqoop是Apache的一個(gè)獨(dú)立項(xiàng)目,始于2009年。Sqoop是一個(gè)用來將Hadoop和關(guān)系型數(shù)據(jù)庫中的數(shù)據(jù)相互轉(zhuǎn)移的工具,可以將一個(gè)關(guān)系型數(shù)據(jù)庫(例如 :MySQL ,Oracle ,Postgres等)中的數(shù)據(jù)導(dǎo)進(jìn)到Hadoop的HDFS中,也可以將HDFS的數(shù)據(jù)導(dǎo)進(jìn)到關(guān)系型數(shù)據(jù)庫中。其官方地址是 http://sqoop.apache.org/。官網(wǎng)介紹如下:
Apache Sqoop(TM) is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
http://sqoop.apache.org/
Flume最早是Cloudera提供的日志收集系統(tǒng),是Apache下的一個(gè)孵化項(xiàng)目。Flume是一個(gè)高可用的,高可靠的,分布式的海量日志采集、聚合和傳輸?shù)南到y(tǒng),F(xiàn)lume支持在日志系統(tǒng)中定制各類數(shù)據(jù)發(fā)送方,用于收集數(shù)據(jù);同時(shí),F(xiàn)lume提供對數(shù)據(jù)進(jìn)行簡單處理,并寫到各種數(shù)據(jù)接受方(可定制)的能力。其官方地址是 http://flume.apache.org/。官網(wǎng)介紹如下:
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows.
http://flume.apache.org/
離線計(jì)算
離線計(jì)算是指在計(jì)算開始前已知所有輸入數(shù)據(jù),輸入數(shù)據(jù)不會(huì)產(chǎn)生變化,且在解決一個(gè)問題后就要立即得出結(jié)果的前提下進(jìn)行的計(jì)算。離線計(jì)算處理的數(shù)據(jù)是靜態(tài)不變的,但是數(shù)據(jù)量非常大。因此如何存儲和計(jì)算海量數(shù)據(jù)是離線計(jì)算最大的技術(shù)挑戰(zhàn)。這也是Hadoop技術(shù)生態(tài)核心解決的問題。如果你對大數(shù)據(jù)開發(fā)感興趣,想系統(tǒng)學(xué)習(xí)大數(shù)據(jù)的話,可以加入大數(shù)據(jù)技術(shù)學(xué)習(xí)交流扣扣君羊:522189307
HDFS是基于谷歌GFS論文實(shí)現(xiàn)的開源分布式文件系統(tǒng),主要解決海量數(shù)據(jù)的存儲問題。系統(tǒng)架構(gòu)上,HDFS是一個(gè)典型的主從分布式架構(gòu)。主節(jié)點(diǎn)叫NameNode,從節(jié)點(diǎn)叫DataNode。NameNode負(fù)責(zé)集群的全局管理,處理來自客戶端的讀寫請求。DataNode是實(shí)際存儲文件的數(shù)據(jù)塊,執(zhí)行來自主節(jié)點(diǎn)的讀寫命令。HDFS保證了CAP中的CP,追求強(qiáng)一致高吞吐設(shè)計(jì),不適合低延遲的應(yīng)用場景。此外,HDFS采用流數(shù)據(jù)模式訪問和處理文件,只支持追加(append-only)的方式寫入數(shù)據(jù),不支持文件任意offset的修改。它的主要使用場景是作為數(shù)倉的底層存儲系統(tǒng)。
離線計(jì)算的核心計(jì)算模型基于MapReduce實(shí)現(xiàn)。Hive用類SQL的方式,簡化了MapReduce的腳本實(shí)現(xiàn)過程,目前已成為搭建數(shù)倉的首選工具。Spark將MapReduce對磁盤的多點(diǎn)I/O改為內(nèi)存中的多線程實(shí)現(xiàn),將中間處理數(shù)據(jù)存于內(nèi)存來減少磁盤IO操作,速度比傳統(tǒng)MapReduce快10倍。此外,Spark還支持流式計(jì)算,使它在實(shí)時(shí)計(jì)算中也占有一席之地。Presto也是完全基于內(nèi)存的并行計(jì)算模型,查詢性能好,但是受內(nèi)存大小限制,更多用于OLAP查詢。由于離線計(jì)算對時(shí)延要求不高,完全基于內(nèi)存的計(jì)算支撐不起數(shù)倉大量的ETL過程,在實(shí)際場景中,ETL過程大部分還是基于Hive的HSQL實(shí)現(xiàn)。
實(shí)時(shí)計(jì)算
實(shí)時(shí)計(jì)算與離線計(jì)算相對應(yīng)。離線計(jì)算在計(jì)算開始前已經(jīng)知道所有的輸入數(shù)據(jù)。實(shí)時(shí)計(jì)算在計(jì)算開始前并不知道所有的輸入數(shù)據(jù),輸入數(shù)據(jù)以序列化的方式一個(gè)個(gè)輸入并進(jìn)行處理。實(shí)時(shí)計(jì)算過程處理的數(shù)據(jù)量不大,但是要求數(shù)據(jù)處理的速度非常快。如果說離線計(jì)算看重的是高吞吐能力,那么實(shí)時(shí)計(jì)算看重的就是快響應(yīng)能力。為了實(shí)現(xiàn)快響應(yīng),實(shí)時(shí)計(jì)算通常會(huì)采用流計(jì)算(Stream Computing)方式。
流計(jì)算與批計(jì)算(Batch Computing)相對應(yīng),兩者區(qū)別在于處理的數(shù)據(jù)粒度不同。批計(jì)算以數(shù)據(jù)塊為單位進(jìn)行數(shù)據(jù)處理,流計(jì)算以單條數(shù)據(jù)記錄為單位進(jìn)行數(shù)據(jù)處理。批處理的吞吐效率高于流處理,但是由于數(shù)據(jù)到達(dá)不會(huì)立即處理,所以延遲比流處理要高。批處理主要用于離線計(jì)算,流處理主要用于實(shí)時(shí)計(jì)算。但這不是絕對的,實(shí)時(shí)計(jì)算有時(shí)為了提高吞吐率,也會(huì)犧牲一些延時(shí),比如Spark Streaming采用微批量(micro-batch,spark中稱為Discretized Stream)的方式進(jìn)行實(shí)時(shí)計(jì)算。除Spark外,Storm和Flink也是主流的實(shí)時(shí)計(jì)算框架,它們都是基于Native Streaming實(shí)現(xiàn),延遲(latency)非常低,Storm在幾十毫秒級別,F(xiàn)link在百毫秒級別。
Storm始于2011年,是Twitter開源的分布式實(shí)時(shí)大數(shù)據(jù)處理框架,被業(yè)界稱為實(shí)時(shí)版Hadoop,2013年開源給Apache。其官方地址是 http://storm.apache.org/。官網(wǎng)介紹如下:
Apache Storm is a free and open source distributed realtime computation system. Apache Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing.
http://storm.apache.org/
Flink誕生于歐洲的一個(gè)大數(shù)據(jù)研究項(xiàng)目StratoSphere。該項(xiàng)目是柏林工業(yè)大學(xué)的一個(gè)研究性項(xiàng)目,早期專注于批計(jì)算。2014 年,StratoSphere 項(xiàng)目中的核心成員孵化出 Flink,并在同年將 Flink 捐贈(zèng) Apache。其官方地址是 https://flink.apache.org/。官網(wǎng)介紹如下:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
https://flink.apache.org/
Flink計(jì)算的主流方向被定位成流計(jì)算,但它和Spark一樣是流批一體的。Spark用批模擬流實(shí)現(xiàn)流計(jì)算,F(xiàn)link用流模擬批來支持批處理。與Storm和Spark相比,F(xiàn)link最大的優(yōu)勢在于它實(shí)現(xiàn)了有狀態(tài)(Stateful)的計(jì)算,這個(gè)能力讓它可以提供Exactly-Once語義保證,大大提高了程序員的編程效率。在眾多的流計(jì)算框架中,F(xiàn)link是最接近 Dataflow 模型的流計(jì)算框架,業(yè)內(nèi)評價(jià)它是繼Spark之后的第四代大數(shù)據(jù)計(jì)算引擎。現(xiàn)在國內(nèi)互聯(lián)網(wǎng)公司,包括BAT和TMD都選擇了Flink。
除了計(jì)算問題外,對于實(shí)時(shí)計(jì)算還有一個(gè)很重要的問題:如何建立實(shí)時(shí)輸入的數(shù)據(jù)流通道。Kafka就是解決這個(gè)問題的最佳利器。Kafka起源于LinkedIn,2011年開源給Apache。其官方地址是 http://kafka.apache.org/。官網(wǎng)介紹如下:
Kafka is used for building real-time data pipelines and streaming apps. It is horizontally scalable, fault-tolerant, wicked fast, and runs in production in thousands of companies.
http://kafka.apache.org/
技術(shù)選型上,經(jīng)常會(huì)拿Kafka跟MQ中間件(比如RabbitMQ、RocketMQ)進(jìn)行比較。但Kafka設(shè)計(jì)的初衷是做日志統(tǒng)計(jì)分析,不是以可靠消息傳輸為設(shè)計(jì)目標(biāo)。比如Kafka中消息可能會(huì)重復(fù)或亂序,它也不支持事務(wù)消息等。另外,Kafka采用批處理的方式傳遞消息,吞吐量高,但會(huì)有延遲,時(shí)效性不如MQ中間件,這也是為什么不建議用Kafka替代MQ中間件的原因。
OLAP
大數(shù)據(jù)的主要應(yīng)用之一就是做數(shù)據(jù)分析,更專業(yè)的表述叫OLAP。OLAP是On Line Analytical Processing(聯(lián)機(jī)分析處理)的縮寫,與OLTP(On Line Transaction Processing, 聯(lián)機(jī)事務(wù)處理)相對應(yīng)。OLTP是傳統(tǒng)的關(guān)系型數(shù)據(jù)庫的主要應(yīng)用,是一種操作型數(shù)據(jù)處理。OLAP是數(shù)據(jù)倉庫的主要應(yīng)用,是一種分析型數(shù)據(jù)處理。
OLAP分析處理的數(shù)據(jù)一般采用維度建模,基于“維度”的分析操作包括:鉆取(上鉆roll up和下鉆drill down)、切片(slice)和切塊(dice)、以及旋轉(zhuǎn)(pivot)等。按數(shù)據(jù)存儲方式不同,OLAP引擎分為ROLAP、MOLAP和HOLAP三種(如下圖所示)。按實(shí)現(xiàn)架構(gòu)不同,OLAP引擎可分為:MPP(Massively Parallel Processor, 大規(guī)模并行處理)架構(gòu)、預(yù)處理架構(gòu)和搜索引擎架構(gòu)。
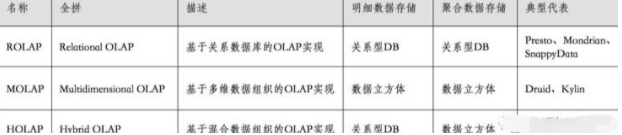
基于MPP架構(gòu)的ROLAP引擎:Presto
利用關(guān)系模型來處理OLAP查詢,通過并發(fā)來提高查詢性能。Presto是Facebook于2012年開發(fā),2013年開源的,完全基于內(nèi)存的并⾏計(jì)算,分布式SQL交互式查詢引擎。其官網(wǎng)地址是:https://prestodb.io/ 。
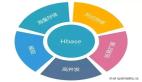
基于預(yù)計(jì)算架構(gòu)的MOLAP引擎:Druid、Kylin
Kylin是完全的預(yù)計(jì)算引擎,通過枚舉所有維度的組合,建立各種Cube進(jìn)行提前聚合,以HBase為基礎(chǔ)的OLAP引擎。其官網(wǎng)地址是:http://kylin.apache.org/ 。
Druid則是輕量級的提前聚合(roll-up),同時(shí)根據(jù)倒排索引以及bitmap提高查詢效率的時(shí)間序列數(shù)據(jù)和存儲引擎。其官網(wǎng)地址是:https://druid.apache.org/ 。
基于搜索引擎架構(gòu)的OLAP:ES
ES是典型的搜索引擎類的架構(gòu)系統(tǒng),在入庫時(shí)將數(shù)據(jù)轉(zhuǎn)換為倒排索引,采用Scatter-Gather計(jì)算模型提高查詢性能。- 對于搜索類的查詢效果較好,但當(dāng)數(shù)據(jù)量較大時(shí),對于Scan類和聚合類為主的查詢性能較低。
看數(shù):敏捷BI工具
看數(shù)解決數(shù)據(jù)可視化問題,幫助BI進(jìn)行數(shù)據(jù)分析,支持企業(yè)決策,實(shí)現(xiàn)商業(yè)價(jià)值。這個(gè)領(lǐng)域,國內(nèi)外已經(jīng)有很多成熟的軟件,比如QlikView、TableAU、FineBI、PowerBI、QuickBI等。大部分BI軟件都是商業(yè)軟件,不支持私有化部署或者私有化部署成本很高。并且,BI工具的用戶定位偏專業(yè)數(shù)據(jù)分析師,對普通人來說有一定的學(xué)習(xí)使用門檻。隨著前端數(shù)據(jù)可視化組件的不斷完善(比如Highcharts、百度的Echats、阿里的antV(G2)等),許多互聯(lián)網(wǎng)公司會(huì)選擇定制的數(shù)據(jù)可視化方案。一些大公司也會(huì)自研BI工具,比如滴滴的數(shù)易。