數據倉庫Hive vs 準實時分析系統Impala
一、什么是Hive?
Hive是基于Hadoop的一個數據倉庫工具,可以將結構化的數據文件映射為一張數據庫表,并提供完整的SQL查詢功能,可以將SQL語句轉換為MapReduce任務進行運行。Hive支持HSQL,是一種類SQL。
也由于這種機制導致Hive最大的缺點是慢。MapReduce調度本身只適合批量,長周期任務,類似查詢這種要求短平快的業務,代價太高。
二、什么是Impala?
Impala是用于處理存儲在Hadoop集群中的大量數據的MPP(大規模并行處理)SQL查詢引擎。它是一個用C++和Java編寫的開源軟件。與其他Hadoop的SQL引擎相比,它提供了高性能和低延遲。
換句話說,Impala是性能最高的SQL引擎(提供類似RDBMS的體驗),它提供了訪問存儲在Hadoop分布式文件系統中的數據的最快方法。
三、Hive vs Impala
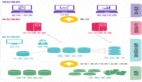
Impala與Hive都是構建在Hadoop之上的數據查詢工具,各有不同的側重適應面,但從客戶端使用來看Impala與Hive有很多的共同之處,如數據表元數據、ODBC/JDBC驅動、SQL語法、靈活的文件格式、存儲資源池等。Impala與Hive在Hadoop中的關系如下圖所示。
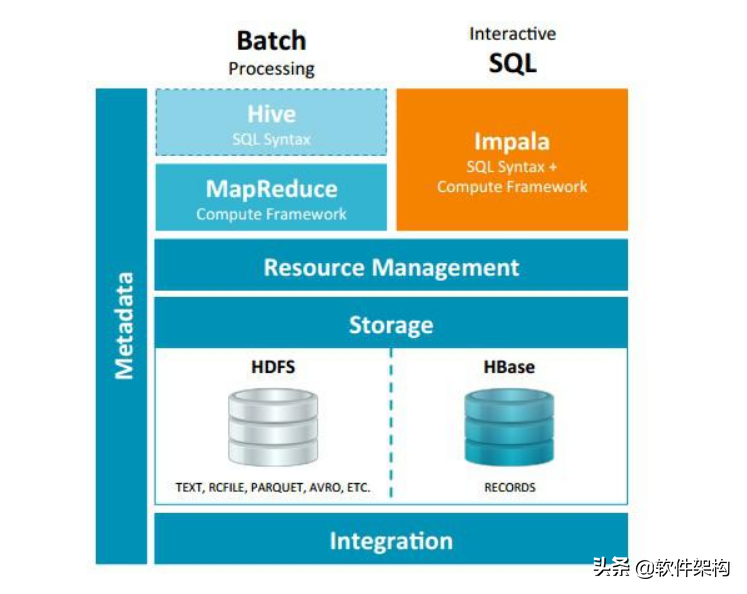
Hive適合于長時間的批處理查詢分析,而Impala適合于實時交互式SQL查詢,Impala給數據分析人員提供了快速實驗、驗證想法的大數據分析工具。可以先使用Hive進行數據轉換處理,之后使用Impala在Hive處理后的結果數據集上進行快速的數據分析。
Impala沒有使用 MapReduce進行并行計算,雖然MapReduce是非常好的并行計算框架,但它更多的面向批處理模式,而不是面向交互式的SQL執行。與 MapReduce相比:Impala把整個查詢分成一執行計劃樹,而不是一連串的MapReduce任務。在分發執行計劃后,Impala使用拉式獲取數據的方式獲取結果,把結果數據組成按執行樹流式傳遞匯集,減少了把中間結果寫入磁盤的步驟,再從磁盤讀取數據的開銷。Impala使用服務的方式避免每次執行查詢都需要啟動的開銷,即相比Hive沒了MapReduce啟動時間。
四、處理數據的方式
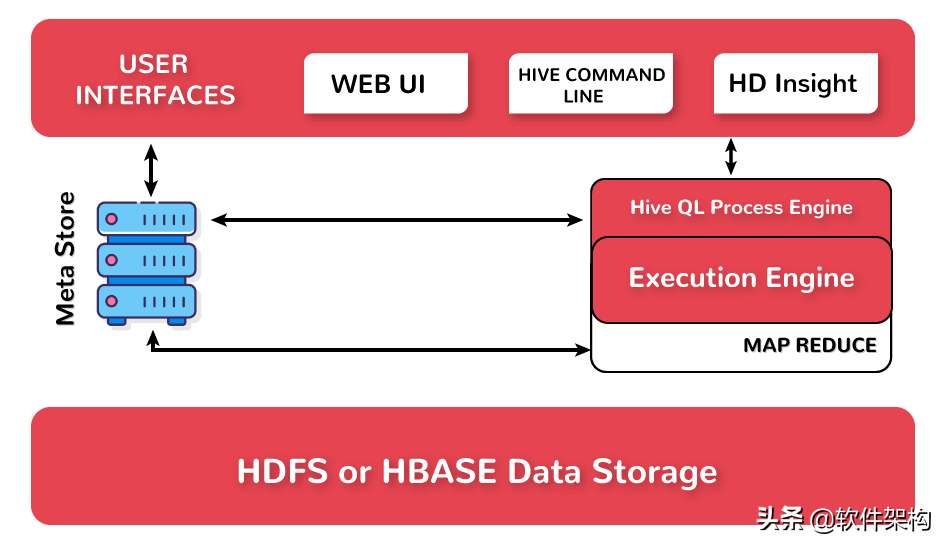
(1)Hive處理數據的方式
HiveQL通過CLI/Web UI或者thrift 、odbc 或 jdbc接口的外部接口提交,經過complier編譯器,運用Metastore中的元數據進行類型檢測和語法分析,生成一個邏輯計劃(logical plan),然后通過簡單的優化處理,產生一個以有向無環圖DAG數據結構形式展現的MapReduce任務。
(2)Impala處理數據的方式
每當用戶使用提供的任何接口發起查詢時,集群中的Impalads之一就會接受該查詢。 此Impalad被視為該特定查詢的協調程序。
在接收到查詢后,查詢協調器使用Hive元存儲中的表模式驗證查詢是否合適。 然后,它從HDFS名稱節點(NameNode)收集關于執行查詢所需的數據的位置的信息,并將該信息發送到其他Impalad以便執行查詢。
所有其他Impala守護程序讀取指定的數據塊并處理查詢。 一旦所有守護程序完成其任務,查詢協調器將收集結果并將其傳遞給用戶。
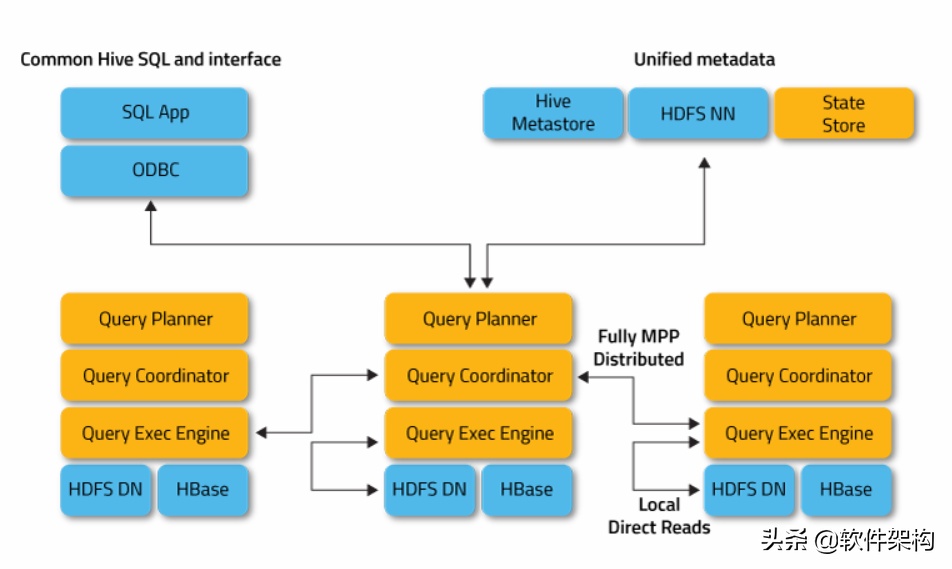
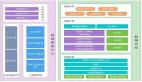
黃色部分是 Imapla模塊,藍色部分為運行 Impala 依賴的其他模塊。Impala 整體分為兩部分:StateStore 和 Impalad。
StateStore 是 Impala 的一個子服務,用來監控集群中各個節點的健康狀況,提供節點注冊,錯誤檢測等功能。
Impala Daemon 進程是運行在集群每個節點上的守護進程,每個節點上這個進程名稱為Impalad。
Impalad 運行在 DataNode 節點上,主要有兩個作用 :
- 一是協調Client提交的 Query 的執行,給其他Impalad分配任務,收集其他Impalad的執行結果進行匯總;
- 二是這個Impalad也會執行其他Impalad給其分配的任務,執行這部分任務主要就是對本地HDFS和HBase中的數據進行操作。
Impala中表的元數據存儲借用的是Hive的,也就是表的元數據信息存儲在Hive的Metastore中。
位于HDFS數據節點DataNode上的每個Impalad進程,都具有如下幾個模塊:
- Query Planner;
- Query Coordinator;
- Query Exec Engine;
Query Planner 接收來自SQL APP和ODBC的SQL語句,解釋成功執行計劃。Query Coordinator將執行計劃進行優化和拆分,形成執行計劃片段,調度這些片段分發到各個節點上,由各個節點上的Query Exec Engine 負責執行,最后返回中間結果,這些中間結果經過聚集之后,最終返回給用戶。