當(dāng)Pravega遇到TiDB,如何構(gòu)建出實時數(shù)據(jù)倉庫?
目前,大多數(shù)企業(yè)采用Apache Flink與Kafka相結(jié)合的方式進行實時數(shù)據(jù)處理,即kafka從其他端獲取數(shù)據(jù)后,?刻到Flink進行計算,F(xiàn)link計算完后結(jié)果導(dǎo)入到數(shù)據(jù)庫,整個過程是數(shù)據(jù)流式處理。然而,由于Kafka不在磁盤中持久保存數(shù)據(jù),在極端情況下,數(shù)據(jù)可能會丟失。
綜合研究了市場上主流的數(shù)據(jù)庫和存儲系統(tǒng)以后,筆者發(fā)現(xiàn)了一個更有效、更準(zhǔn)確的實時數(shù)據(jù)倉庫解決方案,即通過Pravega+TiDB這種架構(gòu)組合,來構(gòu)建實時數(shù)據(jù)倉庫。
在這篇文章中,我們將重點介紹Pravega分布式流存儲系統(tǒng)、TiDB分布式SQL數(shù)據(jù)庫能給用戶帶來哪些價值,以及這種組合如何解決Kafka數(shù)據(jù)持久性挑戰(zhàn)。同時,Pravega+TiDB在自動擴展、實時數(shù)據(jù)倉庫的高并發(fā)性、可用性和安全性等方面有哪些表現(xiàn)。
Pravega——重構(gòu)流式存儲架構(gòu)
Pravega 是Dell Emc開源分布式流存儲系統(tǒng),也是全球頂級開源基金會CNCF(云原生計算基金會)的沙盒項目。與Kafka和Apache Pulsar相似,Pravega重點解決了流批統(tǒng)一問題。
除此之外,Pravega功能更豐富:
- 自動化擴展能力更強。
- Pravega,是一個完整的存儲接口,提供以 stream 為抽象的接口,支持上層計算引擎的統(tǒng)一訪問。

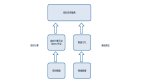
▲Pravega架構(gòu)
在分布式系統(tǒng)中,客戶端應(yīng)用程序和消息系統(tǒng)之間的異步傳遞信息,一般基于消息隊列來實現(xiàn)。提到消息隊列,大家首先會想到Kafka。Kafka是一個基于Zookeeper的分布式日志系統(tǒng)。它支持多分區(qū)、多副本和多訂閱者。
可以說,Pravega重構(gòu)了流式存儲架構(gòu),主要為解決Kafka無法解決的問題而建立。作為一個實時流式存儲解決方案,Pravega支持長期數(shù)據(jù)保留。Pravega在Hadoop分布式文件系統(tǒng)(HDFS)或S3上寫入數(shù)據(jù),從而消除了對數(shù)據(jù)持久性的擔(dān)憂。此外,Pravega在整個系統(tǒng)中只存儲一個數(shù)據(jù)副本,從架構(gòu)設(shè)計上解決了Kafka無法解決的問題。

為什么Pravega勝過Kafka?
你可能會問,"既然已經(jīng)有了Kafka,為什么還要重新發(fā)明輪子?" 答案是,使用Kafka存在一個重要挑戰(zhàn),那就是數(shù)據(jù)丟失、數(shù)據(jù)保留和再平衡問題。Kafka吃的數(shù)據(jù)比它吐出的多,存在著數(shù)據(jù)丟失的風(fēng)險。
- 當(dāng)你設(shè)置acks = all時,只有當(dāng)所有消費者確認(rèn)消息被保存時才會返回ACK,不會丟失數(shù)據(jù)。
- 當(dāng)acks = 1時,如果leader消費者保存了消息,就會返回ACK。如果leader在備份數(shù)據(jù)之前就關(guān)閉了,數(shù)據(jù)就會丟失。
- 當(dāng)acks=0時,Kafka不等待消費者的確認(rèn)。當(dāng)消費者關(guān)閉時,數(shù)據(jù)就會丟失。
Kafka沒有提供一個簡單有效的解決方案來將數(shù)據(jù)持久化到HDFS或S3,所以數(shù)據(jù)保留成為一個問題。雖然Confluent提供了相關(guān)解決方案,但你必須使用兩套存儲接口來訪問不同層的數(shù)據(jù)。
- 使用Apache Flume通過Kafka -> Flume -> HDFS訪問數(shù)據(jù)。
- 使用kafka-hadoop-loader通過Kafka -> kafka-hadoop-loader -> HDFS來訪問數(shù)據(jù)。
- 使用Kafka Connect HDFS通過Kafka -> Kafka Connect HDFS -> HDFS來訪問數(shù)據(jù)。
消費者再平衡也是有害的。因為新的消費者被添加到隊列中,隊列可能在重新平衡期間停止消費消息。因為提交間隔時間長,消費者可能會重復(fù)處理數(shù)據(jù)。無論哪種方式,重新平衡都可能導(dǎo)致消息積壓,從而增加延遲。
與Kafka相比,Pravega提供了更多的功能。

▲Pravega VS Kafka
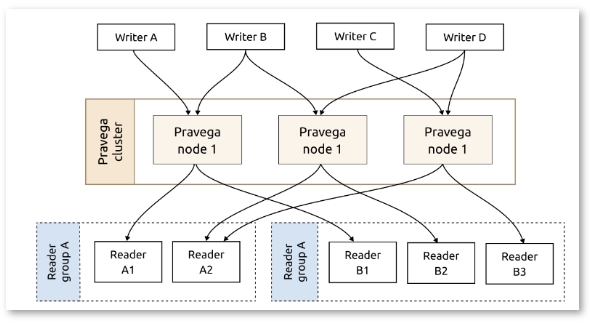
Pravega的特別之處在于,使用Apache BookKeeper來處理低延遲、高并發(fā)和數(shù)據(jù)的實時寫入等問題。然而,BookKeeper只作為一個緩存層,用于批量寫入。所有對Pravega的讀取請求都是直接向HDFS或S3發(fā)出,以利用其高吞吐量能力。
換句話說,Pravega不使用BookKeeper作為數(shù)據(jù)緩沖層,而是提供一個基于HDFS或S3的存儲層。這個存儲層既支持低延遲的尾部讀寫,也支持高吞吐量的追趕式讀取的抽象。當(dāng)數(shù)據(jù)在BookKeeper和HDFS或S3之間移動時,使用BookKeeper作為獨立層的系統(tǒng)可能表現(xiàn)不佳。相比之下,Pravega可以確保令人滿意的性能。
Pravega的優(yōu)勢與價值
通常,DBA有三個主要關(guān)注點:數(shù)據(jù)準(zhǔn)確性、系統(tǒng)穩(wěn)定性和系統(tǒng)可用性。
- 數(shù)據(jù)的準(zhǔn)確性是非常重要的。任何數(shù)據(jù)丟失、損壞或重復(fù)都將是一場災(zāi)難。
- 系統(tǒng)的穩(wěn)定性和可用性使DBA從繁瑣的維護程序中解脫出來,讓他們將時間投入到改善性系統(tǒng)應(yīng)用中。
Pravega解決了DBA的這些擔(dān)憂。它長期保留保證了數(shù)據(jù)的安全性,并且以精確的一次語義保證了數(shù)據(jù)的準(zhǔn)確性,尤其是自動擴展性,使系統(tǒng)維護變得輕而易舉。
實時數(shù)據(jù)倉庫是怎樣一個架構(gòu)?
問題是,實時數(shù)據(jù)倉庫應(yīng)該包含哪些關(guān)鍵組成部分?
一個實時數(shù)據(jù)倉庫通常有四個組成部分:數(shù)據(jù)采集層、數(shù)據(jù)存儲層、實時計算層和實時應(yīng)用層。通過將多種技術(shù)整合到一個無縫的架構(gòu)中,我們可以建立一個可擴展的大數(shù)據(jù)架構(gòu),可以支持?jǐn)?shù)據(jù)分析和挖掘,在線交易,以及統(tǒng)一的批處理和流處理等等。

▲實時數(shù)據(jù)倉庫的四個組成部分
數(shù)據(jù)存儲層有多種選擇,但不是所有的都適合實時數(shù)據(jù)倉庫:
- Hadoop或傳統(tǒng)的OLAP數(shù)據(jù)庫不能提供令人滿意的實時處理。
- 像HBase這樣的NoSQL解決方案可以實時擴展和處理數(shù)據(jù),但不能提供分析。
- 獨立的關(guān)系型數(shù)據(jù)庫不能擴大規(guī)模以適應(yīng)大量數(shù)據(jù)。
然而,TiDB解決了所有這些需求。
為什么選用TiDB?
TiDB是一個開源的分布式SQL數(shù)據(jù)庫,支持混合交易和分析處理(HTAP)工作負(fù)載。它與MySQL兼容,具有水平擴展性、強一致性和高可用性。
與其他開源數(shù)據(jù)庫相比,TiDB這種HTAP架構(gòu)更適合于建立實時數(shù)據(jù)倉庫。TiDB擁有一個混合存儲層,由TiKV(行存儲引擎)和TiFlash(列存儲引擎)組成。這兩個存儲引擎使用TiDB作為一個共享的SQL層。TiDB回答在線事務(wù)處理(OLTP)和在線分析處理(OLAP)查詢,并根據(jù)執(zhí)行計劃的成本從任何一個引擎中獲取數(shù)據(jù)。

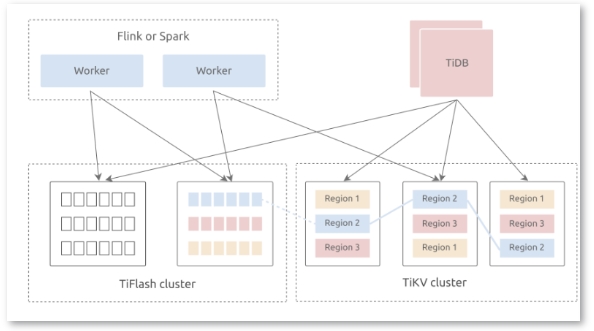
▲TiDB HTAP架構(gòu)
此外,TiDB 5.0引入了大規(guī)模并行處理(MPP)架構(gòu)。在MPP模式下,TiFlash補充了TiDB的計算能力。在處理OLAP工作負(fù)載時,TiDB成為一個主節(jié)點。用戶向TiDB服務(wù)器發(fā)送請求,所有的TiDB服務(wù)器執(zhí)行表連接,并將結(jié)果提交給優(yōu)化器進行決策。優(yōu)化器評估所有可能的執(zhí)行計劃(基于行、基于列、索引、單服務(wù)器引擎和MPP引擎),并選擇最佳計劃。

▲TiDB的MPP模式
例如,一個訂單處理系統(tǒng)在銷售活動中可能會遇到一個突然的流量高峰。在這個高峰期,企業(yè)需要進行快速分析,以便及時對客戶行為做出反應(yīng)和回應(yīng)。傳統(tǒng)的數(shù)據(jù)倉庫很難在短時間內(nèi)應(yīng)對泛濫的數(shù)據(jù),而且可能需要很長的時間來進行后續(xù)的數(shù)據(jù)分析處理。
通過MPP計算引擎,TiDB可以預(yù)測即將到來的流量高峰,并動態(tài)地擴展集群,為活動提供更多的資源。并且,它可以輕松地在幾秒鐘內(nèi)響應(yīng)聚合和分析請求。
當(dāng)TiDB遇到Pravega
在Flink的幫助下,當(dāng)TiDB遇到Pravega,構(gòu)成了一個實時、高吞吐量、穩(wěn)定的數(shù)據(jù)倉庫,該數(shù)據(jù)倉庫能夠滿足用戶對大數(shù)據(jù)的各種要求,并能一站式地處理OLTP和OLAP工作負(fù)載。