文本領域的對抗攻擊研究綜述
引 言
對抗攻擊(也稱為對抗樣本生成)是近幾年人工智能領域新興的研究方向,最初是針對圖像所提出,在計算機視覺領域取得了豐碩的研究成果,提出了很多實用的攻擊算法。最近,研究人員在不斷尋找新的應用場景,積極探索對抗攻擊在其他領域的應用,針對文本的對抗攻擊已取得一些進展。
基本概念
對抗樣本的概念最初是在2014年提出的,指的是一類人為構造的樣本,通過對原始的樣本數據添加針對性的微小擾動所得到,其不會影響人類的感知,但會使深度學習模型產生錯誤的判斷[1]。對抗攻擊即指構造對抗樣本的過程。
圖1展示了文本領域內實現對抗攻擊的一個例子。語句(1)為原始樣本,語句(2)為經過幾個字符變換后得到的對抗樣本。深度學習模型能正確地將原始樣本判為正面評論,而將對抗樣本誤判為負面評論。而顯然,這種微小擾動并不會影響人類的判斷。
關于對抗樣本存在的原因,有學者認為是由于模型的高度非線性和過擬合,有學者認為是由于特征維度過高和模型的線性性質,至今還未達成共識,研究人員一般都會根據自己的研究成果來進行解釋,每個人提出的觀點往往僅適用于局部現象。但不管是線性解釋還是非線性解釋,究其本質是由于模型沒有學到完美的判別規則,模型的判斷邊界與真實的決策邊界不一致。深度學習模型由于能夠自動學習特征的能力而得到廣泛應用,但是這種由數據出發進行自主學習,所得到的特征并不一定就是我們所希望的特征,模型對數據的理解與人的理解有著很大的差異。因而模型學習到的特征,極有可能并非是人理解事物的特征,即對抗樣本的存在是深度學習模型的固有缺陷。
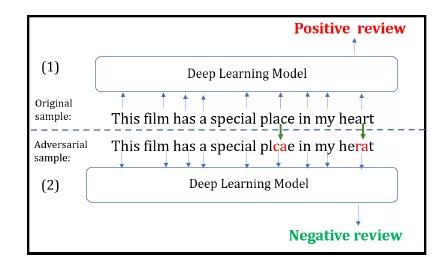
圖1 文本領域的對抗攻擊舉例
文本數據VS圖像數據
文本數據與圖像數據的不同,為文本領域的對抗攻擊研究帶來了巨大挑戰。[2]
1. 離散VS連續(Discrete VS Continucous)
圖像數據是連續的,易編碼為數值向量,預處理操作線性、可微,通常使用lp范數來度量原始樣本與對抗樣本間的距離;而文本數據是符號化的數據,是離散的,預處理操作非線性、不可微,很難定義文本上的擾動及度量文本序列改變前后的差異。
2. 易感知VS不易感知(Preceivable VS Unperceivable)
人類通常不容易察覺到圖像像素的微小變化,因此圖像的對抗樣本不會改變人類的判斷力,只會影響深度學習模型的判別結果;而文本上的變化則很容易影響文本可讀性,在將文本數據輸入DNN模型之前通過拼寫檢查和語法檢查來識別或糾正更改,極有可能導致攻擊失敗。
3. 富有語義VS無語義(Semanic VS Semanic-less)
像素的微小變化不會改變圖像的語義,但對文本的擾動可輕易改變單詞和句子的語義。例如,干擾單個像素不會將圖像從貓變為另一種動物,而刪除否定詞將改變句子的情感。更改樣本的語義有悖于對抗樣本的定義,文本領域的對抗樣本應在使深度學習模型發生誤判的同時保持數據樣本的真實標簽不變。
針對以上挑戰,有些學者首先將文本數據映射為連續數據,然后借鑒計算機視覺領域的一些對抗攻擊算法生成對抗樣本,有些學者針對文本數據的特性直接通過插入、刪除、替換等文本編輯操作生成對抗樣本。
算法分類
如圖2所示,對抗攻擊算法可以從不同的角度進行分類。
根據模型訪問權限可以分為白盒攻擊和黑盒攻擊,白盒攻擊需要獲取模型的結構和參數等詳細信息;而黑盒攻擊不需要模型知識,只需訪問模型獲取輸入的對應輸出即可。
根據攻擊目標設定可以分為有目標攻擊和無目標攻擊,無目標攻擊旨在使模型的輸出為偏離正確結果的任意錯誤預測;而有目標攻擊旨在使模型的輸出為某一特定結果。
根據添加擾動時所操作的文本粒度可以分為字符級、單詞級和語句級攻擊。字符級攻擊通過插入、刪除或替換字符,以及交換字符順序實現;單詞級攻擊主要通過替換單詞實現,基于近義詞、形近詞、錯誤拼寫等建立候選詞庫;語句級攻擊主要通過文本復述或插入句子實現。
根據攻擊策略可以分為Image-to-Text(借鑒圖像領域的經典算法)、基于優化的攻擊、基于重要性的攻擊以及基于神經網絡的攻擊。部分學者通過將文本數據映射到連續空間,然后借鑒圖像領域的一些經典算法如FGSM、JSMA等,生成對抗樣本;基于優化的攻擊將對抗攻擊表述為帶約束的優化問題,利用現有的優化技術求解,如梯度優化、遺傳算法優化;基于重要性的攻擊通常首先利用梯度或文本特性設計評分函數鎖定關鍵詞,然后通過文本編輯添加擾動;基于神經網絡的攻擊訓練神經網絡模型自動學習對抗樣本的特征,從而實現對抗樣本的自動化生成。
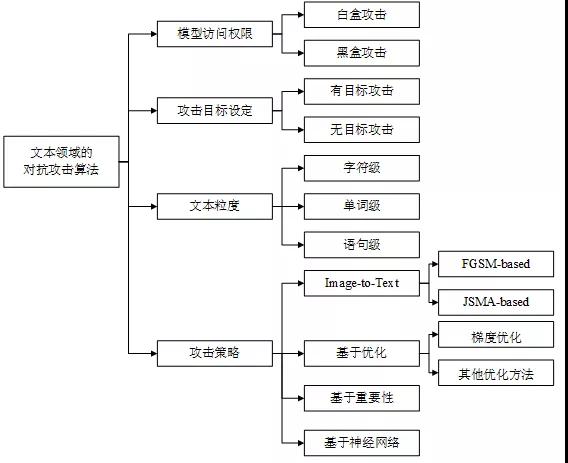
圖2 文本領域的對抗攻擊算法分類機制
代表性算法
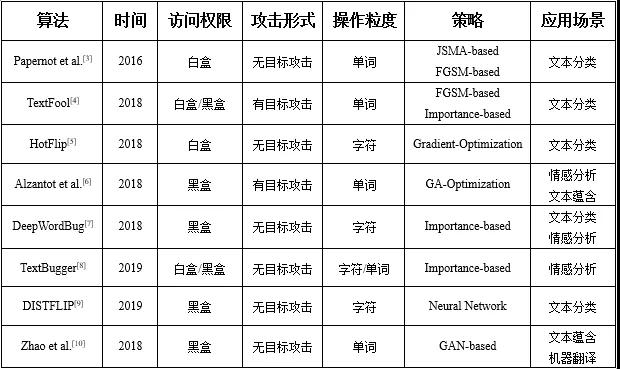
文本領域的常見任務有文本分類、情感分析、機器翻譯、閱讀理解、問答系統、對話生成、文本蘊含等,其中文本分類與情感分析任務使用分類器模型,其他任務使用seq2seq模型。針對分類任務的研究較多,下文介紹幾種代表性算法,表1總結了其主要特點。
Papernot等人[3]最先研究了文本領域的對抗樣本問題,提出了生成對抗性輸入序列的概念。作者將圖像對抗領域的JSMA算法遷移到文本領域,利用計算圖展開技術來評估與單詞序列的嵌入輸入有關的前向導數,構建雅可比矩陣,并借鑒FGSM的思想計算對抗性擾動。由于詞向量不能取任意實數值,作者建立了一個特定的詞典來選擇單詞以替換原始序列中的隨機詞。
Liang等人[4]提出了TextFool方法,首先針對白盒模型和黑盒模型使用不同的策略識別出對分類具有重要貢獻的文本項(HTP、HSP),然后對這些重要的文本項通過單一或混合使用插入、修改和刪除三種擾動策略,生成對抗樣本。對于白盒模型,作者借鑒FGSM的思想來估算文本項的重要度,但是通過損失函數的梯度大小而不是梯度符號來度量;對于黑盒模型,通過遮擋文本的策略來識別重要文本項。
Ebrahimi 等人[5]提出了HotFlip方法,基于one-hot表示的梯度來有效估計單個操作所造成的最大損失的變化,通過原子翻轉操作(將一個字符替換為另一個字符)生成對抗樣本,并通過一系列的字符翻轉來支持插入和刪除操作。考慮到梯度優化的局限性,Alzantot等人[6]提出使用最優化技術中的遺傳算法(Genetic Algorithm, GA)來生成與原始樣本具有相似語義和語法的對抗樣本。
Gao等人[7]提出了DeepWordBug方法,將對抗樣本的生成分為兩個階段。首先使用針對文本數據特性設計的評分函數來識別關鍵的Token,根據重要性進行排名;然后對排名最高的m個Token通過簡單的字符級操作(交換、替換、刪除和插入)進行擾動,改變分類結果。
Li等人[8]提出了TextBugger方法,首先針對白盒和黑盒模型通過不同策略識別影響模型分類結果的重要詞,然后采取插入、刪除、字符交換、字符替換、單詞替換等五種擾動策略分別生成擾動從中選擇一個最優擾動。在白盒場景下,通過計算分類器的雅可比矩陣來找到重要詞;在黑盒場景下,首先根據分類置信度找到重要的句子,然后使用評分函數來找到重要單詞。
Gil 等人[9]提出了HotFlip的派生方法DISTFLIP,該算法提取HotFlip優化過程中的知識訓練神經網絡模型來模擬攻擊從而生成對抗樣本,極大地節省了運行時間,并可以遷移到黑盒場景下進行攻擊。
Zhao等人[10]設計的用于生成對抗樣本的模型,首先使用一個逆變器將原始數據映射到向量空間,在數據對應的稠密向量空間中進行搜索添加擾動得到對抗樣本;然后使用GAN作為生成器將向量空間中得到的對抗樣本映射回原始數據類型。
表1 文本對抗領域的代表性算法
小 結
如今,深度神經網絡(DNN)在計算機視覺、語音識別和自然語言處理等各類領域得到了廣泛應用,涉及許多安全關鍵任務,對抗樣本的存在給基于DNN模型部署的系統帶來了潛在的安全威脅。例如攻擊自動駕駛系統,可使其錯誤識別路標造成交通隱患;攻擊惡意軟件檢測器,可使惡意軟件逃過檢測被識別為健康軟件。
相較于圖像領域,在文本領域生成對抗樣本更具挑戰性,在擾動離散數據的同時需要保留有效的句法、語法和語義。未來的研究可以考慮以下幾點:
(1)提高不可感知性。許多研究工作是通過翻轉字符或改變單詞來實現對文本的擾動,這種擾動較為明顯,錯誤拼寫的單詞和語法錯誤的句子很容易被人發現,也能被語法檢查軟件檢測出來,因此這種擾動很難攻擊實際的NLP系統。
(2)提高移植性。目前,文本對抗的研究主要集中在理論模型上,很少涉及到實際應用。對于現實世界中的NLP系統,模型訪問受到限制,可移植性是實施攻擊的關鍵因素。
(3)實現自動化。大多數研究工作在構造文本擾動時,需要依靠人工操作,效率較低。如通過將手動選擇的無意義段落串聯起來攻擊閱讀理解系統,人工挑選形近詞等。
參考文獻
[1]Szegedy C, Zaremba W, Sutskever I, et al. Intriguing Properties of Neural Networks[C] // Proceedings of the 2th International Conference on Learning Representations, 2014.
[2]Zhang W E, Sheng Q Z, Alhazmi A, et al. Adversarial Attacks on Deep Learning Models in Natural Language Processing: A Survey[J]. ACM Transactions on Intelligent Systems and Technology (TIST). 2020, 11(3): 1-41.
[3]Papernot N, McDaniel P, Swami A, et al. Crafting Adversarial Input Sequences for Recurrent Neural Networks[C]// Proceedings of MILCOM 2016-2016 IEEE Military Communications Conference. IEEE, 2016: 49-54.
[4]Liang B, Li H, Su M, et al. Deep Text Classification Can be Fooled[C]// Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence(IJCAI). 2018: 4208-4215.
[5]Ebrahimi J, Rao A, Lowd D, et al. HotFlip: White-Box Adversarial Examples for Text Classification[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2018: 31-36.
[6]Alzantot M, Sharma Y, Elgohary A, et al. Generating Natural Language Adversarial Examples[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 2890-2896.
[7]Gao J, Lanchantin J, Soffa M L, et al. Black-box Generation of Adversarial Text Sequences to Evade Deep Learning Classifiers[C]// Proceedings of 2018 IEEE Security and Privacy Workshops (SPW). IEEE, 2018: 50-56.
[8]Li J, Ji S, Du T, et al. TextBugger: Generating Adversarial Text Against Real-world Applications[C]// Proceedings of the 26th Annual Network and Distributed System Security Symposium. 2019.
[9]Gil Y, Chai Y, Gorodissky O, et al. White-to-Black: Efficient Distillation of Black-Box Adversarial Attacks[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019: 1373-1379.
[10]Zhao Z, Dua D, Singh S. Generating Natural Adversarial Examples[C]// Proceedings of the International Conference on Learning Representations. 2018.

【本文為51CTO專欄作者“中國保密協會科學技術分會”原創稿件,轉載請聯系原作者】