從數據表到圖表分析,這個實用的圖表推薦框架令你如虎添翼
面對數據表時,很多人通常不清楚應該創建什么樣的圖表分析。在這種場景中,你需要一個智能助手,可以幫你更好的生成圖表分析。
為多維數據集創建圖表(表格)是銷售、人力資源、投資、工程、科研、教育等許多領域的常見應用。為了執行常規分析和發現見解,人們花費大量時間構建不同類型的圖表來展示不同的觀點。這個過程通常需要數據分析方面的專業知識和廣泛的知識儲備來創建適當的圖表。
有沒有可能通過智能的方式來創建圖表呢?近日,由微軟研究院、北京大學和清華大學共同發表了一篇論文,文中提出的新型圖表推薦框架 Table2Charts 可以高效地解決創建圖表問題。

論文地址:https://arxiv.org/pdf/2008.11015.pdf
人們通常會創建不同類型的圖表來研究多維數據集。但是,要構建一個能夠推薦常用組成圖表的智能助手,通常面臨著多方言統一、數據不平衡和開放詞匯這些根本性問題。
因此,該論文提出了 Table2Charts 框架,該框架可以從大量的(表,圖表)對語料庫中學習通用模式。此外,基于具有復制機制和啟發式搜索的深度 Q-learning,Table2Charts 可進行表到序列的生成,其中每個序列都遵循圖表模板。
在具有 196000 個表和 306000 個圖表的大型電子表格語料庫中,該研究展示了 Table2Charts 可以學習表字段的共享表示,這樣不同圖表類型的任務就可以相互增強。
該論文的主要貢獻如下:
該論文提出了 Table2Charts 框架,該框架可以構建圖表合成助手。它能夠學習共享表的表示形式,以便在所有圖表類型的推薦任務中獲得更好的性能和效率,這是通過在圖表類型之間的統一操作空間上定義圖表模板來實現的;
對于涉及從表中選擇數據字段以填充模板的結構化預測問題(生成分析操作序列),該論文設計了具有復制機制的深度 Q 值網絡(Deep Q-value Network, DQN)。DQN 的編碼器部分學習表表示,而解碼器部分學習序列生成;
首次構建并大規模評估能夠從人類智慧中學習的端到端圖表推薦系統。
方法
在 Table2Charts 中,該論文設計了一種編碼器 - 解碼器 DQN 結構,它所具有的復制機制可用來填充圖表模板。由于模板規則生成序列的曝光偏差較大,因此研究者在進行集束搜索時采用搜索采樣技術進行訓練。
此外,為了解決數據不平衡問題并相互提高不同圖表類型之間的性能,研究者將主要的圖表類型混合在一起進行訓練以獲得混合模型。
混合編碼器部分是共享表表示形式,它將被傳輸到每個單一類型任務以進行解碼器調整。混合編碼器 - 解碼器也可直接用于多類型任務。
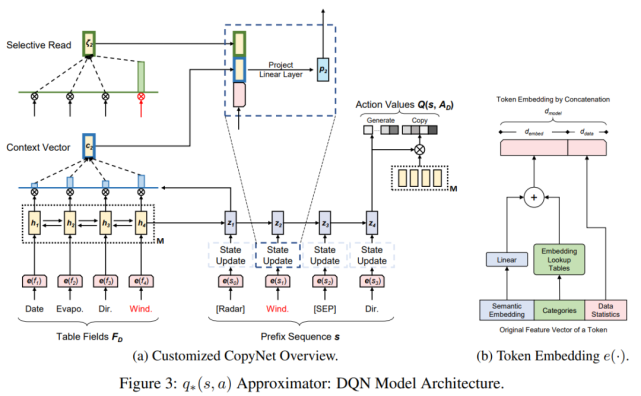
DQN 的模型架構如下圖 3 所示:
混合訓練和遷移學習
該論文設計的 DQN 具有編碼器 - 解碼器框架,其中編碼器計算表字段的表示嵌入,而解碼器使用給定的表示進行序列生成。基本思想為:表表示編碼器應該在一個多類型和六個單類型任務之間共享,以暴露于不同且豐富的表字段樣本,并減少部署任務模型的內存占用和推理時間。
為了學習共享表表示編碼器并獲取特定任務的解碼器,該論文提出了一個混合與遷移范式,該范式包含以下兩個階段:
混合訓練:將所有主要圖表類型混合在一起并訓練一個 DQN 模型。混合編碼器將被遷移至下一階段,而整個混合 DQN 將用于多類型推薦任務;
遷移學習:從上一階段獲取混合編碼器,并凍結其參數。然后,對于每個單一類型的任務,共享編碼器僅用圖表類型的數據訓練新的解碼器部分。
在單獨訓練(Lone Training)中,只使用圖表類型的數據為每個單一類型的任務訓練整個 DQN。與之相比,Table2Charts 中的混合遷移范式具有以下兩個優點:
更好的內存占用和推理速度,因為現在所有任務的 DQN 模型共享一個相同的表表示編碼器,而單獨訓練仍然需要為每個任務保留表表示編碼器,并導致更多的編碼器計算;
編碼器暴露的樣本遠遠超過每種圖表類型所能提供的樣本。這不僅可以更好地學習和泛化表的表示形式,而且還解決了數據不平衡的問題,因此僅解碼器部分(與較大的編碼器部分相比較小)需要針對較小的圖表類型進行調整。
實驗
圖表語料庫
本研究中的圖表語料庫包含 39139 個(12.8%)線狀、93614 個(30.5%)條狀、149747 個(48.8%)Series、20921(6.8%)個餅圖、2237(0.7%)個區域和 1244(0.4%)個雷達圖。
在過濾掉重復表、超大表(>128 個字段)、空圖表(未選擇字段)和過于復雜的圖表(y 軸字段數 > 4 個)并對每個表模式的表(由表的字段名和字段類型組成)進行下采樣后,306902 個圖表中保留 196255 個,共有 131119 個不同的表模式。這些模式(及其表和圖表)按 7:1:2 的比例分配給訓練、驗證和測試。
對單一類型推薦任務的評估
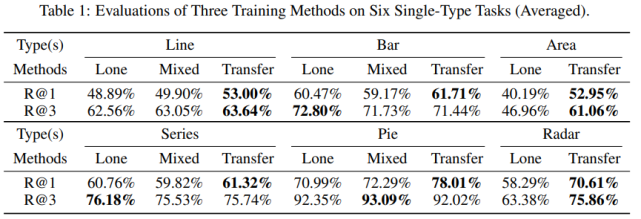
評價結果如表 1 所示。混合和遷移范式(Transfer)通常比單獨訓練 (Lone) 和僅混合模式(Mixed) 效果更好。特別地,Transfer 的評價標準 R@1 超過了其他兩種方法。
在較小的圖表類型上,增強效果清晰可見,召回率提升了約 12%。數據不平衡的問題得到了解決,因為較小圖表類型的有限數據僅用于訓練小的解碼器部分,而無需擔心編碼器部分。
探索表表示
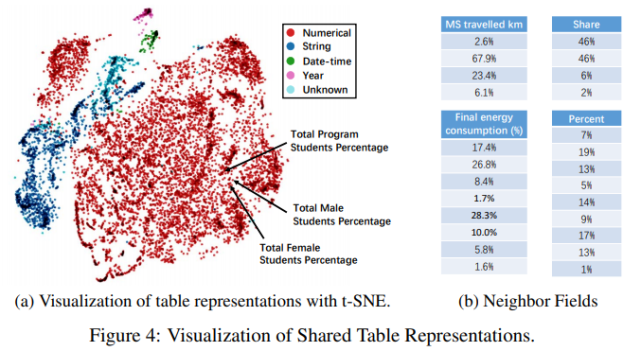
該實驗從驗證集中隨機選擇 3039 個表(包含 20000 個字段),通過 t-SNE 進行可視化,用來理解共享表表示編碼器生成的嵌入如何工作。
在下圖 4a 中,每個點代表一個字段,顏色代表其字段類型。在圖中,我們可以清楚地看到通過嵌入學得的字段類型信息。例如,日期時間字段和年份字段很接近。一種可能的解釋是,它們都經常在序列圖中用作 x 軸,因此具有相似的表示形式。