













終于有人把云計算、物聯網和大數據講明白了
本文轉載自微信公眾號「大數據DT」,作者高聰 王忠民 等 。轉載本文請聯系大數據DT公眾號。
01 云計算
根據美國國家標準與技術研究院(National Institute of Standards and Technology,NIST)的定義,云計算是指能夠針對共享的可配置計算資源,按需提供方便的、泛在的網絡接入的模型。上述計算資源包括網絡、服務器、存儲、應用和服務等,這些資源能夠快速地提供和回收,而所涉及的管理開銷要盡可能小。
具體來說,云模型包含五個基本特征、三個服務模型和四個部署模型。
五個基本特征:
- 按需自助服務(on-demand self-service)
- 廣闊的互聯網訪問(broad network access)
- 資源池(resource pooling)
- 快速伸縮(rapid elasticity)
- 可度量的服務(measured service)
三個服務模型:
- 軟件即服務(Software as a Service,SaaS)
- 平臺即服務(Platform as a Service,PaaS)
- 基礎設施即服務(Infrastructure as a Service,IaaS)
四個部署模型:
- 私有云(private cloud)
- 社區云(community cloud)
- 公有云(public cloud)
- 混合云(hybrid cloud)
一般來說,云計算可以被看作通過計算機通信網絡(例如互聯網)來提供計算服務的分布式系統,其主要目標是利用分布式資源來解決大規模的計算問題。
云中的資源對用戶是透明的,用戶無須知曉資源所在的具體位置。這些資源能夠同時被大量用戶共享,用戶能夠在任何時間、任何地點訪問應用程序和相關的數據。
云計算的體系結構如圖1-3所示,還對三個服務模型進行了闡述。
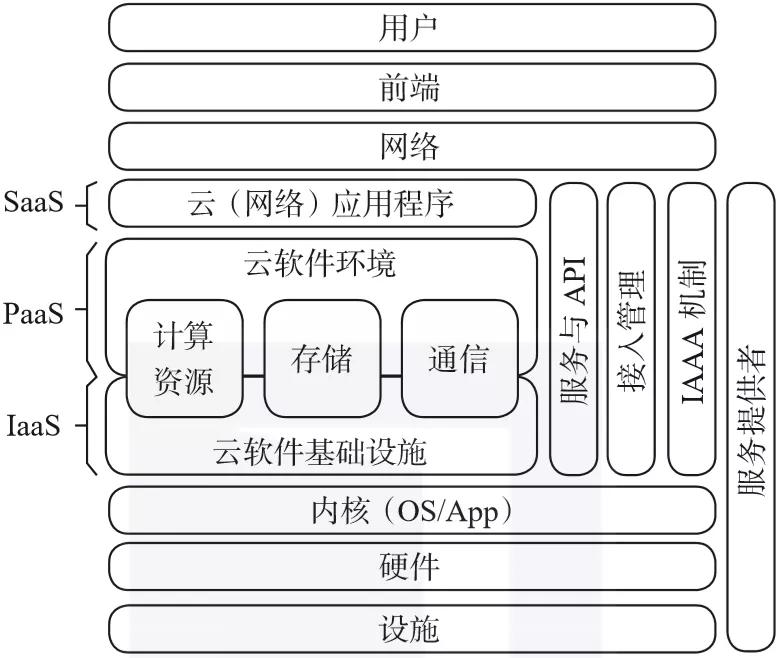
▲圖1-3 云計算的體系結構
1. 基礎設施即服務
這項服務是云計算提供的最簡單的內容,其涉及大規模的計算資源的交付,這些計算資源包括存儲空間、運算能力和網絡帶寬等。
基礎設施即服務的主要優勢是按次付費、安全性以及可靠性,因此也被稱為硬件即服務(Hardware as a Service,HaaS)。這項服務的典型案例有亞馬遜云(Amazon Elastic Compute Cloud,EC2)、谷歌計算引擎(Google Compute Engine,GCE)和阿里云(Aliyun)等。
2. 平臺即服務
這項服務為云計算提供了應用程序的接口。對于云計算來說,基礎設施即服務在很多應用場景下能力不足。
隨著網絡應用程序數的井噴式增長,平臺即服務的相關研究與應用逐步涌現。很多全球性的跨國公司都不約而同地尋求在云計算平臺方面稱霸,就像微軟在個人電腦領域所處的地位一樣。平臺即服務的典型案例有谷歌應用引擎(Google App Engine,GAE)、微軟云(Microsoft Azure)等。
3. 軟件即服務
這項服務旨在提供終端用戶可以直接使用的服務,這里的服務可以理解為部署在互聯網上的軟件。這樣的服務模式在很大程度上替代了在個人電腦上運行的傳統應用程序。
軟件即服務的典型案例有思科(Cisco)的思科網迅(WebEx)、軟營(Salesforce)的客戶關系管理(Customer Relationship Management,CRM)系統以及亞馬遜網絡服務(Amazon Web Service,AWS)。
02 物聯網
物聯網技術棧由三個核心層構成,即物/設備層、連接層和物聯網云層,詳情如圖1-4所示。
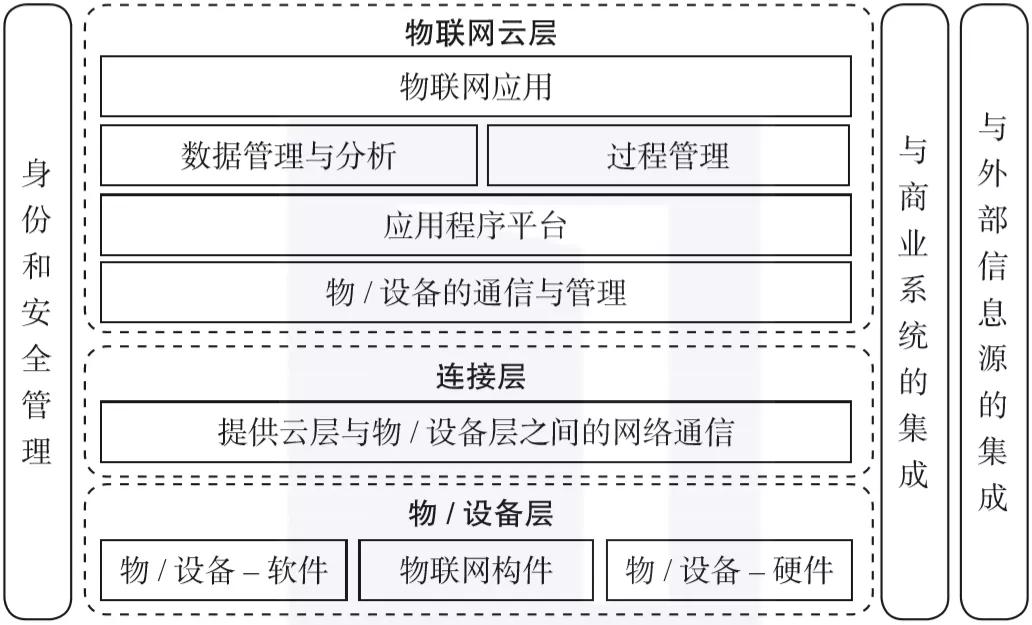
▲圖1-4 物聯網的技術棧
在物/設備層,諸如傳感器、執行器等物聯網特定的硬件可以被添加至已有的核心硬件中,嵌入式的軟件可以被修改或集成進已有的系統,以便管理和操作具體的設備。
在連接層,由通信協議來實現單個物/設備與云之間的通信,例如消息隊列遙測傳輸(Message Queuing Telemetry Transport,MQTT)協議。
在物聯網云層,設備通信協議和管理軟件用來協調、提供和管理互相連接的物/設備,由應用平臺來實現物聯網應用程序的開發和執行。此外,物聯網云層還引入了分析與數據管理軟件來存儲、處理和分析由物/設備產生的數據。針對跨物/設備、人員和系統的過程監測,引入了過程管理軟件來進行定義和執行。對于給定的目的,由物聯網應用程序軟件來協調物/設備、人員和系統之間的交互。
在上述三層的全域范圍內,還存在特定的軟件構件來對物聯網體系整體的身份和安全進行管理,以及提供與商業系統和外部信息源的集成,常見的商業系統和外部信息源類型有企業資源計劃(Enterprise Resource Planning,ERP)系統和客戶關系管理(CRM)系統,外部信息源通常是指來自第三方的信息。
在談論物聯網技術時,“物聯網平臺”(IoT platform)是一個提及頻次很高的概念。在計算領域,術語“平臺”是一個相對廣泛的概念,有些文獻將平臺定義為一組有機結合起來的技術,基于這些技術,能夠開發其他的應用程序。
物聯網平臺本質上是軟件產品,其提供大量與應用程序無關的功能,利用這些功能可以構建物聯網應用程序。對于各種不同的物聯網平臺,其提供者所側重的物聯網技術不同,因此所提供的功能集合也是不同的。
換言之,物聯網平臺的配置沒有統一的標準,但是存在眾多針對不同領域特定需求的物聯網平臺,例如ThingSpeak、DeviceHive、Xively、WSO2以及海爾COSMOPlat等。
將云計算與物聯網進行對比分析,給出了兩個技術領域的互補方面,詳情如表1-1所示。
▼表1-1 云計算與物聯網的互補方面
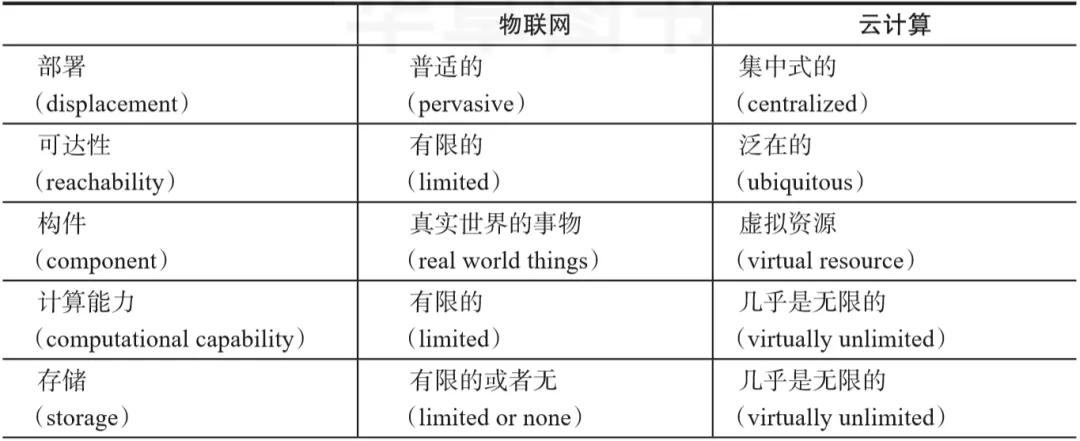
一般來說,物聯網能夠在云計算的虛擬形式的無限計算能力和資源上補償自身的技術性限制(例如存儲、計算能力和通信能力)。
云計算能夠為物聯網中服務的管理和組合提供高效的解決方案,同時能夠實現利用物聯網中產生的數據的應用程序和服務。對于物聯網來說,云計算能夠以更加分布式的、動態的方式來擴展其能處理的真實世界中物/設備的范圍,進而交付大量實際生活中的場景所需要的服務。
在多數情況下,云計算能夠提供物與應用程序之間的中間層,同時將實現應用程序所必需的復雜性和功能都隱藏起來,這將影響未來的應用程序開發。在未來的多云環境下,應用程序的開發面臨著來自信息的收集、處理和傳輸等方面的新挑戰。
物聯網在工業領域的應用涵蓋了眾多方面,例如自動化、優化、可預測制造、運輸等。
制造(manufacturing)是物聯網在工業領域最大的市場,涉及軟件、硬件、連通性和服務等。隨著物聯網的引入,由原料、工件、機器、工具、庫存和物流等組成的工業系統構成了實施制造過程的生產單元,上述這些構件之間可以互相通信。
物聯網提供的連通性驅動了各項操作技術(Operational Technology,OT)的實際性能的收斂性,這里的操作技術包括機械手、傳送帶、儀表、發電機等。在整個制造過程中,傳感器、分布式控制以及安全軟件發揮著“膠水”的作用。當前,工業領域有遠見的企業都將生產線和生產過程構建在了物聯網之上。
運輸(transportation)是物聯網在工業領域的第二大市場。當前,在眾多城市中涌現的智能運輸網絡能夠優化傳統運輸網絡中的路徑,生成高效、安全的路線,降低基礎設施的開銷并緩解交通擁塞。航空、鐵路、城際等貨運公司能夠集成海量的數據來對需求進行實時分析,實現統籌規劃和優化操作。
03 大數據
隨著物聯網和云計算技術的發展,海量的數據以前所未有的速度從異構數據源產生,這些數據源所在的領域有醫療健康、政府機構、社交網絡、環境監測和金融市場等。
在這些景象的背后,存在大量強大的系統和分布式應用程序來支持與數據相關的操作,例如智能電網(smart grid)系統、醫療健康(healthcare)系統、零售業(retailing)系統、政府(government)系統等。
在大數據的變革發生之前,絕大多數機構和公司都沒有能力長期保存歸檔數據,也無法高效地管理和利用大規模的數據集。實際上,現有的傳統技術能夠應對的存儲和管理規模都是有限的。在大數據環境下,傳統技術缺乏可擴展性和靈活性,其性能也無法令人滿意。
當前,針對海量的數據集,需要設計涵蓋清洗、處理、分析、加載等操作的可行性方案。業界的公司越來越意識到針對大數據的處理與分析是使企業具有競爭力的重要因素。
1. 三類定義
當前大數據在各個領域的廣泛普及使得學界與業界對大數據的定義很難達成一致。不過有一點共識是,大數據不僅是指大量的數據。通過對現有大數據的定義進行梳理,我們總結出三種對大數據進行描述和理解的定義。
1)屬性型定義(attributive definition)
作為大數據研究與應用的先驅,國際數據公司(International Data Corporation,IDC)在戴爾易安信(DELL EMC)公司的資助下于2011年提出了如下大數據的定義:
大數據技術描述了技術與體系結構,其設計初衷是通過實施高速的捕獲、發現以及分析,來經濟性地提取大量具有廣泛類型的數據的價值。
該定義側面描述了大數據的四個顯著特征:數量、速度、多樣化和價值。由Gartner公司分析師Doug Laney總結的研究報告中給出了與上述定義類似的描述,該研究指出數據的增長所帶來的挑戰與機遇是三個維度的,即顯著增長的數量(Volume)、速度(Velocity)和多樣化(Variety)。
盡管Doug Laney關于數據在三個維度的描述最初并不是要給大數據下定義,但包括IBM、微軟在內的業界在其后的十年間都沿用上述“3V”模型來對大數據進行描述。
2)比較型定義(comparative definition)
Mckinsey公司2011年給出的研究報告將大數據定義為:
規模超出了典型數據庫軟件工具的捕獲、存儲、管理和分析能力的數據集。
盡管該報告沒有在具體的度量標準方面對大數據給出定義,但其引入了一個革命性的方面,即怎樣的數據集才能夠被稱為大數據。
3)架構型定義(architectural definition)
美國國家標準與技術研究院(NIST)對大數據的描述為:
大數據是指數據的數量、獲取的速度以及數據的表示限制了使用傳統關系數據庫方法進行有效分析的能力,需要使用具有良好可擴展性的新型方法來對數據進行高效的處理。
2. 5V
以下是一些文獻中關于大數據特征的描述:
數據的規模成為問題的一部分,并且傳統的技術已經沒有能力處理這樣的數據。
數據的規模迫使學界和業界不得不拋棄曾經流行的方法而去尋找新的方法。
大數據是一個囊括了在合理時間內對潛在的超大數據集實現捕獲、處理、分析和可視化的范疇,并且傳統的信息技術無法勝任上述要求。
大數據的核心必須包含三個關鍵的方面:數量多、速度快和多樣化,即著名的“3V”。
1)數量
數據的數量又稱為數據的規模,在大數據中,其是指在進行數據處理時所面對的超大規模的數據量。目前,海量的數據持續不斷地從千百萬設備和應用中產生(例如信息通信技術、智能手機、軟件代碼、社交網絡、傳感器以及各類日志)。
- McAfee公司在2012年估算:在2012年的每一天中,全球都產生著2.5EB的數據,并且該數值約每40個月實現翻倍。
- 2013年,國際數據公司(IDC)估算全球所產生、復制和消費的數據已經達到4.4ZB,并且該數值約每兩年實現翻倍。
- 到2015年,全球產生的數據將達到8ZB。根據IDC的研究報告,全球產生的數據將在2020年達到40ZB。
2)速度
在大數據中,數據的速度是指在進行數據處理時所面對的具有高頻率和高實時性的數據流。高速生成的數據應當及時進行處理,以便提取有用的信息和洞察潛在的價值。
全球知名的折扣連鎖店沃爾瑪基于消費者的交易每小時產生2.5PB的數據。視頻分享類網站(例如優酷、愛奇藝等)則是大數據高頻率和高實時性特征的另一個例證。
3)多樣化
在大數據中,數據的多樣化是指在進行數據處理時所面對的具有不同語法格式的數據類型。隨著物聯網技術與云計算技術的普及,海量的多源異構數據從不同的數據源以不同的數據格式持續地產生,典型的數據源有傳感器、音頻、視頻、文檔等。
海量的異構數據形成各種各樣的數據集,這些數據集可能包含結構化數據、半結構化數據、非結構化數據,數據集的屬性可能是公開或隱私的、共享或機密的、完整或不完整的,等等。
隨著大數據理論的發展,更多的特征逐步被納入考慮的范圍,以便對大數據做出更好的定義,例如:
- 想象(vision),這里的想象是指一種目的;
- 驗證(verification),這里的驗證是指經過處理后的數據符合特定的要求;
- 證實(validation),這里的證實是指前述的想象成為現實;
- 復雜性(complexity),這里的復雜性是指由于數據之間關系的進化,海量數據的組織和分析均很困難;
- 不變性(immutability),這里的不變性是指如果進行妥善管理,那么經過存儲的海量數據可以永久保留。
描述大數據的五個關鍵特征(即“5V”):
- 數量(Volume)
- 速度(Velocity)
- 多樣化(Variety)
- 準確性(Veracity)
- 價值(Value)
4)準確性
在商界,決策者通常不會完全信任從大數據中提取出的信息,而會進一步對信息進行加工和處理,然后做出更好的決策。如果決策者不信任輸入數據,那么輸出數據也不會獲得信任,這樣的數據不會參與決策過程。
隨著大數據中數據規模的日新月異和數據種類的多樣化,如何更好地度量和提升數據可信度成為一個研究熱點。
5)價值
一般來說,海量的數據具有價值密度低的缺點。
如果無法從數據中有效地提取出潛在的價值,那么這些數據在某種程度上就是沒用的。數據的價值是決策者最關注的方面,其需要仔細且認真的研究。目前,已經有大量的人力、物力和財力投入到大數據的研究和應用中,這些投資行為都期望從海量數據中獲得有價值的內容。
但是,對于不同的機構和不同的價值提取方法,同樣的數據集所產生的價值差異可能很大,即投入與產出并不一定成正比。因此,對大數據價值的研究需要建立更加完善的體系。
關于作者:高聰,男,1985年11月生,西安電子科技大學計算機科學與技術專業學士,計算機系統結構專業碩士、博士。自2015年12月至今,在西安郵電大學計算機學院任教,主要研究方向:數據感知與融合、邊緣計算和無線傳感器網絡。
本文摘編自《工業大數據融合體系結構與關鍵技術》,經出版方授權發布。






















