













終于有人把云邊協同講明白了
正如前面所述,云計算是一種基于云的計算方式,這里的云指的是通過網絡連接的軟硬件資源。依賴互聯網,可以將各種共享的軟硬件資源分配給多個計算機以及其他終端使用,這使得終端設備可以將耗費計算資源多的應用程序、計算過程放到云上進行,大大增加了終端設備的運行效率。
一、云邊協同是什么
邊緣計算是一種分布式運算的架構,不同于云計算,它將之前由中心服務器負責的任務加以分解,并且將這些分解之后的任務片段分發至網絡的邊緣端,由邊緣端去負責運算。邊緣計算降低了相關信息的傳輸時間,減小了延遲。
云計算雖然可以將大型的計算任務放到云端去進行運算,但是對于需要低延遲的應用來說,則會遇到網絡帶寬瓶頸等問題。邊緣計算可以將任務放到邊緣端來進行,因此邊緣計算受到了本地邊緣終端計算能力的限制。
為了解決上述云計算與邊緣計算的缺點,云邊協同應運而生。云邊協同將云計算與邊緣計算緊密地結合起來,通過合理地分配云計算與邊緣計算的任務,實現了云計算的下沉,將云計算、云分析擴展到邊緣端。隨著技術的發展,云邊協同一定會在未來的互聯網產業之中占有一席之地。
二、云邊協同下的數據安全場景
隨著云計算與邊緣計算的發展,數據安全問題也成為一個重要的研究課題。針對數據安全保護,首先需要明確數據安全保護的相關場景。在云邊協同的環境下,主要考慮兩種數據安全場景:訓練與查詢。
在云邊協同訓練場景下,可以有以下應用實例。
(1)云邊協同人臉識別模型訓練
對于一個機器學習模型來說,訓練樣本的數量會影響到最終模型的效果。而在大數據時代下,各種各樣的智能設備都可以進行數據樣本的采集。然而如果將采集的設備傳輸到云端進行模型訓練則會面臨一些問題:一是帶寬與延遲的消耗;二是數據保存在云端則會有嚴重的隱私泄露隱患。
在這種場景下,云邊協同進行模型的訓練則是一個很好的選擇。得益于邊緣端的數據收集能力,最終訓練出來的模型的泛化性能會更好。其中邊緣端負責數據的收集以及部分的模型訓練,云端負責將邊緣端的模型更新聚合并且發送回邊緣端。而傳統的人臉識別模型訓練通常是先收集人臉數據,然后對人臉數據進行標注,同時在中心服務器進行人臉識別模型訓練,最后將訓練得到的模型部署到邊緣端。
在上述訓練過程中,需要由數據收集邊緣端收集數據,同時與中心服務器進行直接的數據交互,而直接的數據交互勢必導致隱私的泄露問題。相比于傳統的人臉識別模型訓練,云邊協同下的人臉識別模型訓練(見圖1)不需要將人臉數據上傳至中心服務器,而這防止了某種程度的隱私泄露問題,然而云邊協同下的人臉識別模型訓練仍然面臨著許多問題,例如訓練數據的標注問題以及如何更好地進行分布式訓練,這些問題都需要進一步研究與解決。
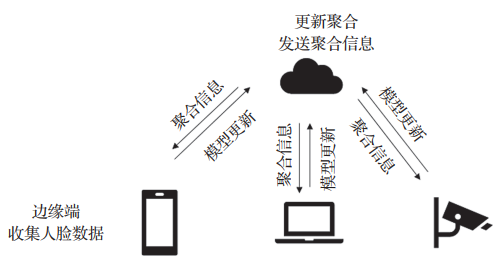
圖1 云邊協同人臉模型訓練
(2)云邊協同推薦系統
云邊協同下的推薦系統訓練利用邊緣端收集的數據在邊緣端本地進行訓練,同時將模型的更新信息上傳至云端進行模型的整合,本地的模型訓練避免了用戶的行為習慣、瀏覽數據等信息被上傳至云邊,減少了隱私泄露的可能。而傳統的推薦系統的實現,則需要服務提供商(例如淘寶、微博等)主動采集用戶的瀏覽數據、瀏覽偏好、搜索數據等信息,從而進行推薦模型的訓練,最后根據訓練的模型來對用戶進行有針對的推薦。而這種數據收集不可避免的會產生安全隱私問題。盡管以云邊協同的方式進行推薦系統的相關訓練可以在某種程度上避免服務商在云端收集用戶的瀏覽記錄等隱私數據,以達成數據安全保護的目標,但是該方法仍然面臨著一些問題需要解決,例如邊緣端設備的性能制約、云邊通信的帶寬制約等,而這些問題都需要更進一步的研究。
(3)傳統能源行業下的云邊協同數據處理
云邊協同技術不僅僅可以應用于上述的大數據場景,對于傳統的能源行業來說,它涉及的各種設備相對復雜,邊緣端傳感器較多,若是將收集數據全部發送至云端,則會面臨較大的帶寬壓力,因此轉型難度較大。而傳統行業下的數據處理往往比較依賴于人工,這也給傳統行業的轉型帶來了困難。接下來以石油行業為例,簡述石油行業下云邊協同的相關場景以及數據安全問題。不同于傳統的人工錄入等方法,在云邊協同的環境下,針對石油開采,可以將傳感器、各種開采設備等收集到的信息進行整合并且發送到具有簡單數據處理能力的邊緣端進行數據的自動化錄入、數據預處理、數據實時分析等操作,然后將處理之后的數據發送到云端進行更完全的數據分析以及決策,最后將決策結果發送回邊緣端指導石油的開采等操作,如圖2所示:
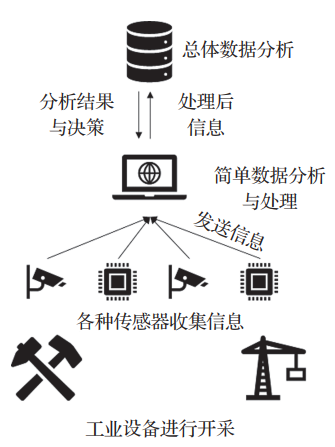
圖2 云邊協同下的石油開采
相比于傳統的石油開采方法,云邊協同下的數據處理大幅度提高了數據處理的效率,并且減少了決策所用的時間。盡管如此,云邊協同下的數據處理仍有一定的隱私泄露風險,在上述場景中,盡管邊緣端承擔了一定的數據分析操作,減輕了帶寬以及云端的壓力,但是數據的更進一步分析仍需要云端的參與,因此在數據傳輸或者云端分析的過程中仍然有隱私泄露的風險。
在云邊協同查詢場景下,有以下應用實例:
(1)云邊協同人臉支付
隨著“刷臉付”時代的到來,人臉識別的精度已經到達了可以進行商用的程度。受限于邊緣端支付設備的計算能力與存儲能力,不可能完全將人臉識別模型部署于邊緣端進行人臉識別,因此“刷臉付”必須要通過云邊協同的方式來實現,如圖3所示。其中邊緣端負責用戶人臉數據的捕獲以及預處理,以減少對網絡帶寬的負荷。云端負責人臉識別以及支付服務的相關邏輯。在上述人臉支付場景下,邊緣、云端、數據傳輸過程中都可能會出現隱私泄露的問題,例如邊緣端設備有可能會被破解成為惡意的邊緣端等,因此需要使用相應的隱私保護技術來防止隱私的泄露。
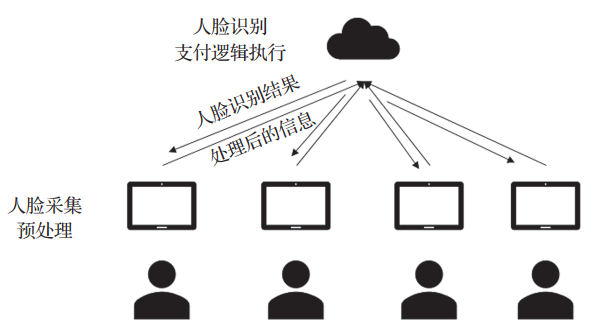
圖3 云邊協同人臉支付
(2)云邊協同智慧交通系統
隨著私家車越來越多,更多的車流量帶來的是對交通系統更大的壓力。當前的智慧交通的一個研究方向是自動駕駛,然而自動駕駛受限于復雜的路況以及車輛的計算能力等因素,不可能在現階段進行大規模的部署。而另一個研究方向則是利用道路上的各種攝像頭傳感器等設備進行數據的收集并且將它們上傳到邊緣端進行簡單的數據分析以及決策,同時在云端進行總體統籌以及數據分析,以實現云邊協同下的智慧交通系統。例如通過攝像頭收集信息并且利用機器學習算法來智能判別道路交通違法行為,以實現效率上的提升。然而借助攝像頭、傳感器等設備收集的道路交通信息往往也有可能泄露道路行人的隱私信息,而這對智慧交通的發展帶來了挑戰。
關于作者:
韓銳,北京理工大學特別研究員,博士生導師。專注于研究面向典型負載(機器學習、深度學習、互聯網服務)的云計算系統優化,在 TPDS、TC、TKDE、TSC等領域頂級(重要)期刊和INFOCOM、ICDCS、ICPP、RTSS等會議上發表超過40篇論文,Google學術引用1000 余次。
劉馳,北京理工大學計算機學院副院長,教授,博士生導師。智能信息技術北京市重點實驗室主任,國家優秀青年科學基金獲得者,國家重點研發計劃首席科學家,中國電子學會會士,英國工程技術學會會士,英國計算機學會會士。
本文摘編自《云邊協同大數據:技術與應用》,經出版方授權發布。(ISBN:9787111701002)轉載請保留文章出處。


















