













終于有人把數據架構講明白了
01數據架構的起源
追根溯源是一個數據人的底層思維邏輯,因此,我們先說一說數據架構的起源(來源也行,一個意思)。
其實,我們現在IT行業經常說的軟件架構、系統架構、XX架構的核心思想都是從建筑行業學來的,架構的英文單詞“Architecture”其本身就是“建筑學、建筑物、結構構造”的意思。
在DAMA-DMBOK2中指出“數據架構”是“企業架構”的一個重要的組成部分。
而提到企業架構,它是起源于IBM公司系統雜志的一篇文章“A framework for information systems architecture”,這篇文章的作者John Zachman,是業內公認的企業架構理論的首創者,而他提出企業架構的理論就是我們熟知的“Zachman框架”!
簡單理解,建筑學就是研究如何將一堆磚頭、水泥、鋼筋等建筑材料按照一定的結構搭建起來,形成滿足人們生活、工作所需的各式建筑物。實際上,Zachman老先生的企業架構思想也是源自于“建筑學”,其本質的原理都是從現狀向目標遷移的過程。因此,企業架構包含了當前架構、目標架構、遷移計劃和IT路線圖。
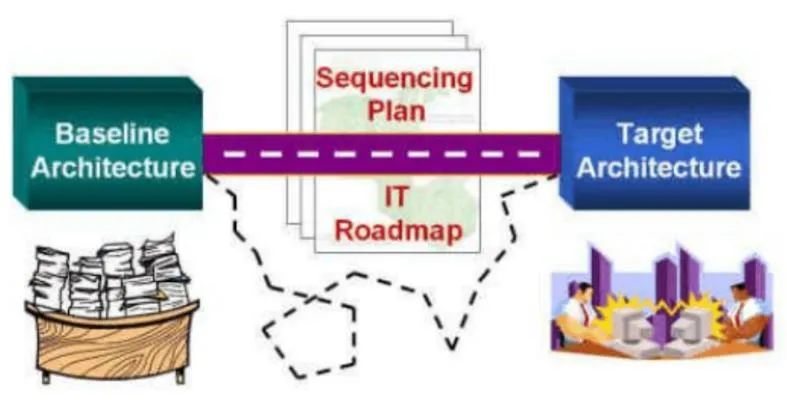
關于企業架構,除了Zachman框架之外,還有聯邦企業架構框架(FEA)、國防部架構框架 (DODAF)、UDPM、UAF等,當然還有非常流行的——Togaf框架。每個企業架構框架的管理原則都涉及推動有關業務戰略及其如何通過 IT 實現未來目標。通常,企業架構是由四個基本的相互關聯的專業領域構成:
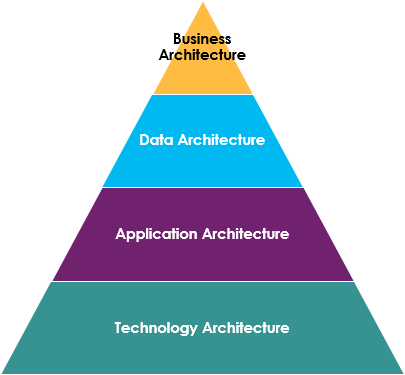
- 業務架構:定義了組織的業務戰略、企業治理、組織機構和關鍵業務流程;
- 應用架構:為要部署的應用系統之間的交互以及它們與組織核心業務流程的關系提供藍圖,并為集成業務功能公開的服務接口;
- 數據架構:描述了組織的邏輯和物理數據資產以及相關數據管理資源的結構;
- 技術架構:描述了支持部署核心任務關鍵型應用程序所需的硬件、軟件和網絡基礎設施;
02數據架構的演進
作為企業架構的組成,數據架構在不同時代,其形態也是不一樣,它是隨著信息技術的不斷發展而向前演進的。
1. 單體應用架構時代
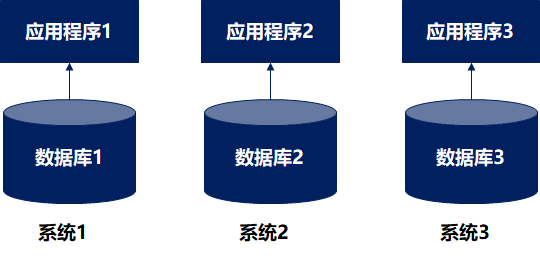
在信息化早期(上世紀80年代),企業信息化初步建設,信息系統以單體應用為主,例如:早期的財務軟件、OA辦公軟件等。這個時期還沒有數據管理的概念還在萌芽期,數據架構比較簡單,主要就是數據模型、數據庫設計,滿足系統業務使用即可。
2. 數據倉庫時代
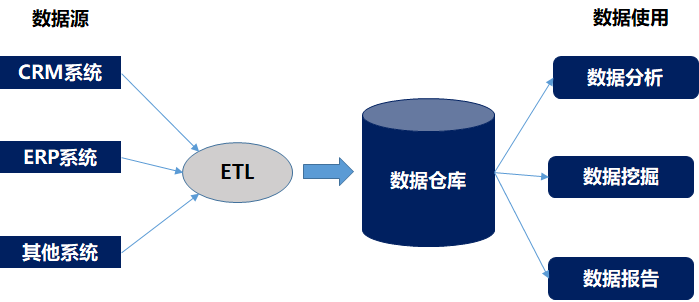
隨著信息系統使用,系統的數據也逐步積累起來。這時候,人們發現數據對企業是有價值的,但是割裂的系統導致了大量信息孤島的產生,嚴重影響了企業對數據的利用。于是,一種面向主題的、集成的、用于數據分析的全新架構誕生了,它就是數據倉庫。
與傳統關系數據庫不同,數據倉庫系統的主要應用是OLAP(On-Line Analytical Processing),支持復雜的分析操作,側重決策支持,并且提供直觀易懂的查詢結果。這個階段,數據架構不僅關注數據模型,還關注數據的分布和流向。
3. 大數據時代
大數據技術的興起,讓企業能夠更加靈活高效地使用自己的數據,從數據中提取出更多重要的價值。與此同時,在大數據應用需求的驅動下,各類大數據架構也在不斷發展和演進著,從批處理到流處理,從大集中到分布式,從批流一體到全量實時。
1)傳統大數據架構
之所以叫傳統大數據架構,是因為其解決的是數據倉庫、BI應用的性能瓶頸問題,數據分析業務沒有發生任何變化,主要是技術上的升級。傳統大數據架構從結構上與數據倉庫基本一致,還是分為三個部分:數據采集、數據處理、數據輸出與展示。
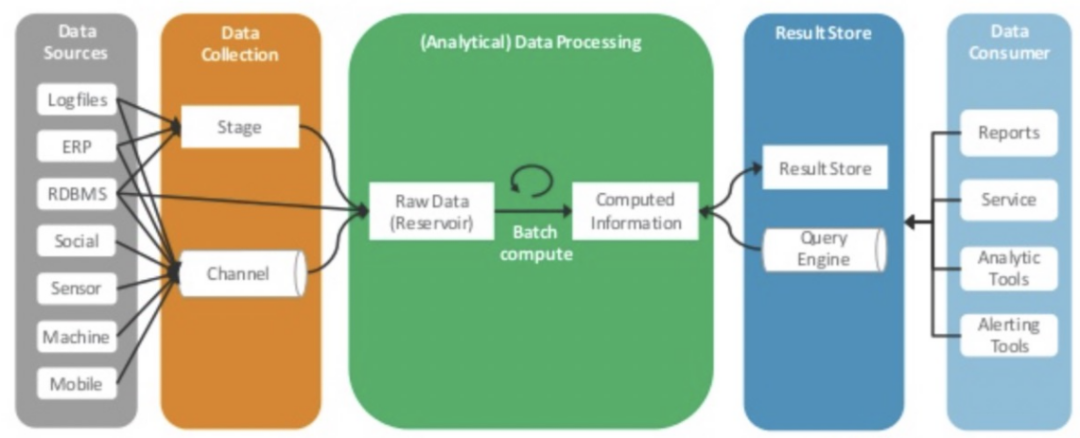
▲圖:傳統大數據架構,來源:51CTO 栗子哥《從傳統大數據架構到Lambda架構到Kappa架構》
相比傳統數據倉庫,傳統大數據架構是基于hadoop的各類組件構建的,例如:數據存儲用HDFS,數據采集用Sqoop、Flume、Kafka等,數據處理用MapReduce、Hive、Spark等,大數據技術的應用使得數據處理的性能得到了巨大提升。
2)Lambda架構
Lambda是大數據架構中舉足輕重的一個大數據架構,Lambda的數據通道分為兩條分支:實時流和離線。實時流依照流式架構,保障了其實時性,而離線則以批處理方式為主,保障了最終一致性。Lambda 架構總共由三層系統組成:批處理層(Batch Layer),速度處理層(Speed Layer),以及用于響應查詢的服務層(Serving Layer)。
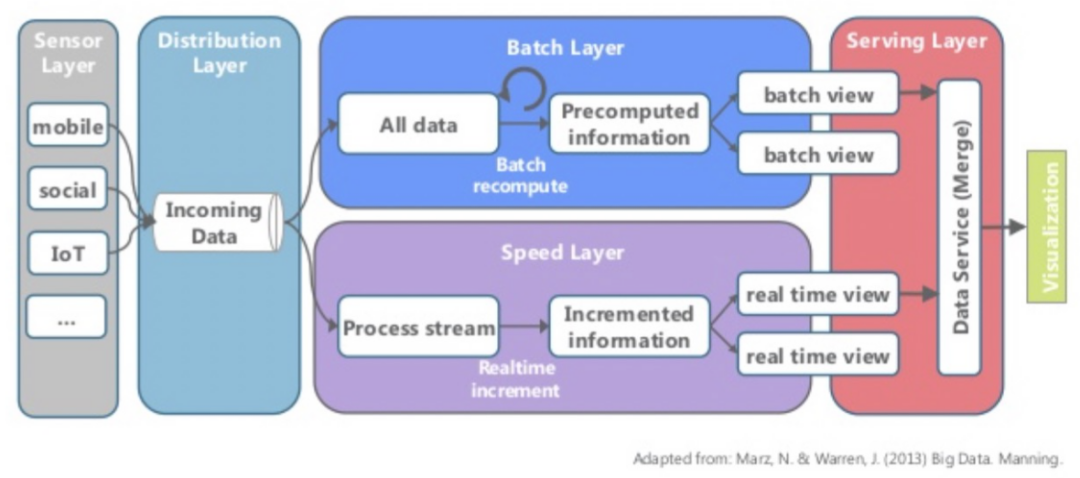
▲圖:Lambda架構,來源:51CTO 栗子哥《從傳統大數據架構到Lambda架構到Kappa架構》
Lambda 架構靈活,可以適用多種應用場景,但在也存在著一些不足,實時層和離線層模塊冗余、維護復雜。
3)Kappa架構
Kappa架構在Lambda 的基礎上進行了優化,將實時和流部分進行了合并,將數據通道以消息隊列進行替代。Kappa架構解決了Lambda 架構需要維護兩套分別跑在批處理和實時計算系統上面的代碼的問題,全程用流系統處理全量數據。
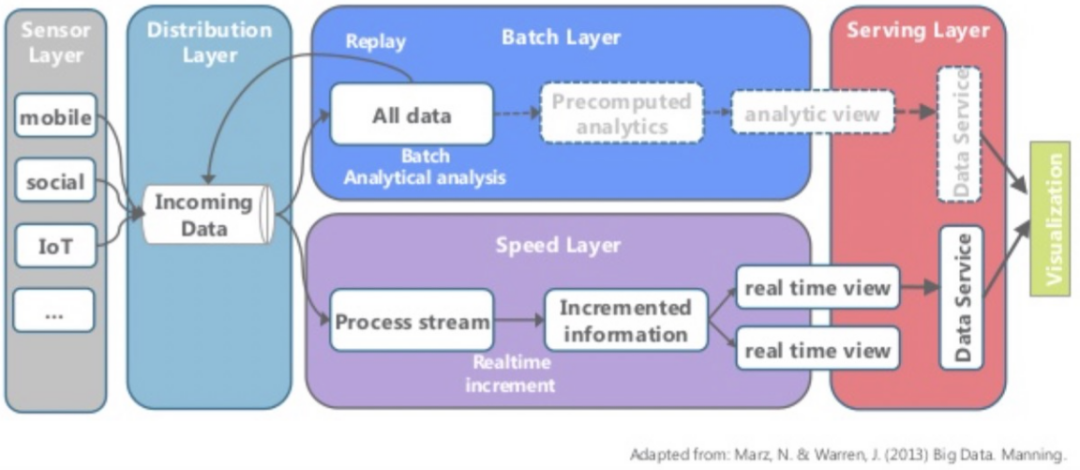
▲圖:Kappa架構,來源:51CTO 栗子哥《從傳統大數據架構到Lambda架構到Kappa架構》
大數據時代,我們以上介紹的幾種大數據架構,雖然名字中都含有“數據架構”四個字,但是和我們今天要講的數據架構還不完全是一回事,大數據架構準確來說,應該叫大數據技術架構,而數據架構是用來承接業務的,技術是其實現手段。
技術架構會影響數據架構,但不論技術如何變遷,數據架構的本質并沒有變,它始終都是數據模型、數據流向、數據分布和數據處理方式的綜合體現。
03數據管理中的數據架構
關于數據架構的定義其實在業內并沒有形成統一的認知,不同人對于數據架構的理解或許都是不同的,這一點我們其實可以從幾個權威的數據管理體系中窺見一二。
1. DAMA-DMBOK2中的數據架構
在DAMA的數據管理知識體系指南(DMBOK2)中對數據架構的定義是:“識別企業的數據需求(無論數據結構如何),并設計和維護總藍圖以滿足這些需求。使用總藍圖來指導數據集成、控制數據資產,并使數據投資與業務戰略保持一致”。其主要包含兩個部分:企業數據模型、數據流設計、數據價值鏈、實施路線圖。

圖:Dama數據架構,來源《DAMA數據管理知識體系指南2.0》
- 企業數據模型:企業數據模型是一個整體的、企業級的、獨立實施的概念或邏輯數據模型,為企業提供通用的、一致的數據視圖。企業數據模型包括數據實體(如業務概念),數據實體間的關系、關鍵業務規則和一些關鍵屬性,它為所有數據和數據相關的項目奠定了基礎。
- 數據流設計:定義數據庫、應用、平臺和網絡(組件)之間的需求和主藍圖。這些數據流展示了數據在業務流程、不同存儲位置、業務角色和技術組件間的流動。
- 數據價值鏈:DMBOK2中沒有明確交代,筆者理解就是基于企業核心業務價值鏈的數據分布和流向,與數據流設計是一致的。
- 實施路線圖:描述了架構3~5年的發展路徑。考慮到實際情況和技術評估,路線圖和業務需求共同將目標架構變為現實。企業架構實施路線圖包括:高層次里程碑事件、所需資源、成本評估、業務能力工作流劃分。
2. DCMM中的數據架構
在國標《數據管理能力成熟度評估模型(DCMM)》中,數據架構是DCMM的8大領域之一,它對數據架構的定義是:“通過組織數據模型定義數據需求,指導數據資產的分布控制和整合,部署數據的共享和應用環境,以及元數據管理的規范”。
在DCMM中,數據架構包含了數據模型、數據分布、數據集成與共享、元數據管理四個部分內容。

- 數據模型:使用結構化的語言將收集到的組織業務經營、管理和決策中使用的數據需求進行綜合分析,按照模型設計規范將需求重新組織。數據模型包括:主題域模型、概念模型、邏輯模型和物理模型。
- 數據分布:針對組織級數據模型中的數據定義,明確數據在系統、組織和流程等方面的分布關系,定義數據類型,明確權威數據源,為數據相關工作提供參考和規范。
- 數據集成共享:建立組織內各應用系統、各部門之間的集成共享機制,通過組織內部數據集成共享相關制度、標準、技術等方面的管理,促進組織內部數據的互聯互通。
- 元數據管理:主要是關于元數據的創建、存儲、整合與控制等一整套流程的集合。
3. 華為的數據之道
在《華為數據之道》一書以及華為很多公開材料中,并沒有明確給出數據架構,而是給出了信息架構的概念:“是指以結構化的方式描述在業務運作和管理決策中所需要的各類信息及其關系的一套整體組件規范。”
從定義上看,華為給出的信息架構和我們所說的數據架構是十分相識的,它包括了數據資產目錄、數據標準、數據模型、數據分布四個部分。
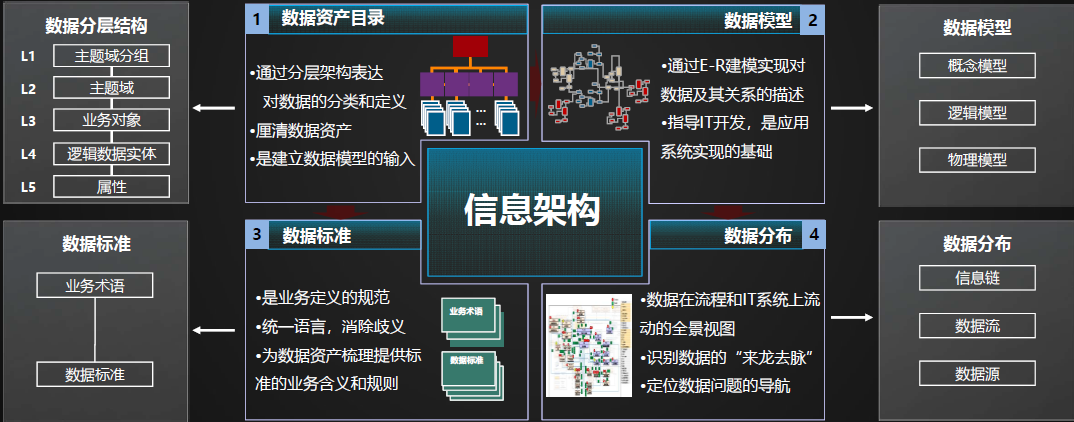
▲圖:信息架構,來源《華為數據治理之旅》
- 數據資產目錄:通過分層結構的表達,實現對數據的分類和定義,建立數據模型的輸入,形成完善的企業資產地圖,也在一定程度上為企業數據治理、業務變革提供了指引。基于數據資產目錄可以識別數據管理責任,解決數據問題爭議,幫助企業更好地對業務變革進行規劃設計,避免重復建設。
- 數據標準:數據標準定義公司層面需共同遵守的屬性層數據含義和業務規則,是公司層面對某個數據的共同理解,這些理解一旦確定下來,就應作為企業層面的標準在企業內被共同遵守。
- 數據模型:是從數據視角對現實世界特征的模擬和抽象,根據業務需求抽取信息的主要特征,反映業務信息(對象)之間的關聯關系。
- 數據分布:定義了數據產生的源頭及在各流程和IT系統間的流動情況。
DAMA的DMBOK2、國標的DCMM、華為的數據之道是當下業界認可的三個主流據管理體系。可以看到,在這三個體系中關于數據架構的定義和內容都不相同。那么,您認為的數據架構應該是什么?或者說,您認為以上三個數據管理系統中,哪個數據架構更合理、更符合企業管數、用數的?
接下來,我們聊聊數據架構的底層邏輯!
04數據架構的底層邏輯
在遙遠的原始社會,人類過著穴居野處的生活,為了適應自然,抵御猛獸,原始社會的人類會利用一些大樹或者直接在地上用樹枝樹葉搭建一些簡易的房子或柵欄。這個時候,人類建筑架構的思維模式已經開始萌芽。從原始部落的穴居野處、茅屋蓬蓽,到如今的鋼筋水泥、高樓林立,建筑架構的發展,本質是一部人類對居住環境的功能和性能不斷追求的發展史。
相比建筑業,IT行業還是一個年輕的行業,它的一些理論體系都是從傳統行業中引進而來的,包括我們今天聊的“架構”。架構思維的底層邏輯是將一個復雜的系統,從多個維度分解為多個架構元素,并定義這些元素之間的接口和交互關系、集成機制。
按照“熵增定律”,架構的本質就是就是對系統進行有序化重構,不斷減少系統的“熵”,使系統不斷進化。而這里,所謂的“熵”就是構成軟件的相關架構元素:組件、結構、功能、流程、數據、接口等。
架構的本質是不斷減少系統的“熵”,數據架構也一樣。數據架構的底層邏輯具有一定的數據資源規劃的內涵,是對企業數據進行結構化、有序化治理,讓企業從數據孤島走向數據共享,讓企業數據能夠更好的被管理、流動和使用,充分釋放數據價值。
基于這一底層邏輯,我們就不難理解DAMA、DCMM和華為在數據架構定義和內容上,雖然有所差異,但本質是一樣的。
在DAMA的數據管理體系中,數據架構最核心的是數據模型和數據流,而數據架構的設計、數據主價值鏈,數據架構實施都是圍繞數據模型和數據流的梳理、設計和落地而展開的。
在DCMM體系中,數據架構除了數據模型和數據分布(數據流)還包含了數據集成共享和元數據管理,這兩個也數據管理中比較大的領域,放在數據架構中略顯突兀。但是,數據模型、數據分布是通過元數據落地的,而數據集成共享也是數據模型并且集成的過程也反映了一定的數據流向,因此DCMM的核心其實還是數據模型和數據流向。
在華為數據之道中,沒有提數據架構而是信息架構。如果我們基于“DIKW模型”,在理解了“數據-信息-知識-智慧”的基礎之上,其實更容易理解華為的信息架構。
在筆者看來,華為信息架構是對數據架構的進一步提煉,是在數據管理實踐的視角給出的定義。如果說,其他兩套體系的數據架構偏理論和技術,那華為給出的信息架構則偏實踐和業務,但其基礎的內容仍然沒變,還是數據模型和數據分布。
在企業的數據項目實踐中,數據架構連接了企業的數據管理現狀和未來要實現的目標,筆者認為不必糾結哪套體系的數據架構理論更嚴謹、邏輯更合理,而要將重點放在數據目標的實現上,“能抓住老鼠的那只貓就是好貓!”




















