













6種數據分析實用方法,終于有人講明白了
具體來說,在本文中,我將概述統計、時間序列分析、自然語言處理、機器學習和運籌學中的方法。
01 應用統計與數學
與前面許多已經討論過的概念一樣,人們如何定義統計以及統計與一般數學(mathematics)有何不同,存在著很大的差異。
有些人認為統計是數學的一個分支(Merriam-Webster,2017b),而另一些人(如John Tukey(Brillinger,2002))則認為統計是一門獨立的科學。大多數人認為,就像物理學也使用數學方法但不是數學一樣,統計學使用數學但它并不是數學(Milley,2012)。
統計涉及數據的收集、組織、分析、解釋和展示。如果使用這個廣義的定義,它聽起來和分析的概念非常像。然而,分析和數據科學都使用統計學的數量分析基礎,但它們的關注范圍比傳統統計更廣泛,而關于統計與其他學科之間的概念關系有幾十個觀點,我列舉了我所看到的這些概念之間的關系,如圖1-3所示。
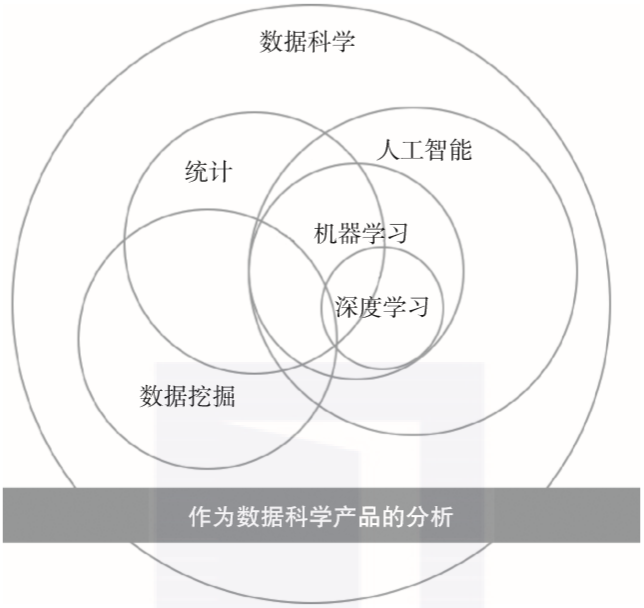
▲圖1-3 統計與其他定量學科之間的關系
數學具有一定的絕對和可確定的性質,而數學的教學方式(至少在美國學校是如此)灌輸了一種以確定性的方式來看待數量世界的思想。也就是說,我們被教導相信,所有的事實和事件都可以被解釋清楚。
但是,統計則把量化數據看成概率的或隨機的。也就是說,根據事實可能會推導出普遍正確的結論(除了簡單的隨機性),但必須承認,存在一些無法準確預測的隨機概率分布或模式。
- 拓展學習:想要學習更多的統計學歷史及它如何改變科學,請閱讀David Salsburg的書The Lady Tasting Tea。
如圖1-4所示,數學思維是演繹性的(即,它通過應用一般定律或原則來推斷某一特定實例),而統計推理是歸納性的(即,它從具體實例中提煉出一般規律)。
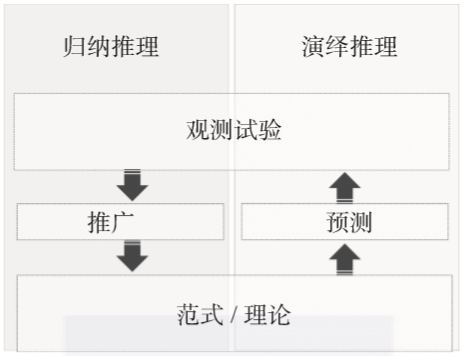
▲圖1-4 歸納推理與演繹推理的比較
這種差異在分析的環境下是很重要的,因為我們將歸納推理和演繹推理應用于分析解決不同的問題。因此,將數學和統計都應用到分析領域是適當的和必要的。如果開展分析是一種全面的策略,那么統計和數學就是在眾所周知的分析工具箱中幫助我們實現該策略的兩個工具。
線性規劃(linear programming)可用于支持我們分析解決一類特定的優化問題。例如,迪士尼公司在其數據科學類工作中使用線性、非線性、混合整數和動態規劃,來解決諸如優化餐廳座位安排、減少公園之間乘車的等待時間、安排工作人員(如演員)時間表等方面的問題。
請注意,為了討論的方便,我在這里不嚴格區分運籌學(operation research)、數學最優化(mathematical optimization)、決策科學(decision science)或精算科學(actuarial science)之間的區別,因為在我看來,它們都是我們分析工具箱中眾多分析工具的組成部分而已,可以根據思考和解決問題的需要而靈活使用。
- 線性規劃:線性規劃是解決問題的一個數學方法,其輸出是一個線性模型函數。例如,我們可能想通過調節幾個關鍵因素,比如外科手術的復雜度、需要醫務人員的數量、可能出現的并發癥等,來優化急救部門的效能。
02 預測和時間序列
在討論支持分析的方法時,預測和時間序列往往被一起提及,并不是因為它們是同一種方法,而是因為它們都針對同一類問題,即基于歷史信息對時間序列數據進行特征提煉和預測。
預測和時間序列分析是指對時間序列數據進行分析、從數據中提煉有意義特征的方法。很多時候,預測被描述為通過歷史數據對趨勢進行判斷,并通過可視化手段進行直觀展現的方法,有些還提供了關于未來的預測。
而時間序列分析不同于預測,雖然你需要時間序列數據來進行預測,但并非所有的時間序列分析都是用來進行預測的。例如,時間序列分析可用于在多個時間序列中發現模式或相似的特征,或執行統計過程控制。類似地,季節性的分析也可以用來識別模式。
時間序列分析采用了多種方法,既有定量的,也有定性的。時間序列分析的目的是在歷史數據(或時間序列數據)中找出一種模式,然后推測未來趨勢。通常有四大類時間序列分析方法,如圖1-5所示。
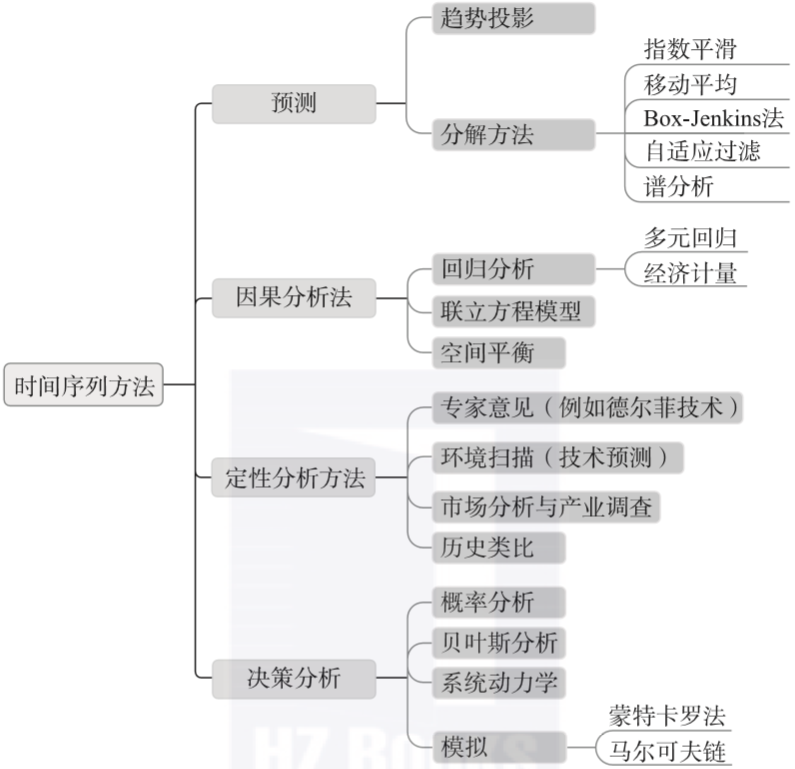
▲圖1-5 預測和時間序列分析的方法
一般而言,定量方法是最常見的預測方法。但是,當無法獲得定量的歷史數據時,或者廣泛存在不確定性時,使用定性分析和決策分析方法也很普遍。
03 自然語言處理
自然語言處理(Natural Language Process,NLP)是指通過計算機來理解和生成“自然語言”的方法。
當前,NLP是一個專注于人類語言和計算機之間相互交互的研究領域,處于計算機科學、人工智能和計算語言學的交叉領域。文本挖掘和文本分析技術通常可以互換使用,既是NLP的前置活動也可以是NLP本身的應用。
NLP的目標是理解計算機文本中的自然語言,NLP用于文本的分類、提取和總結,我們在理解和技術方面的進步正迅速將NLP推向分析和其他許多領域應用的前沿。例如,在分析過程中,我們獲取過去的描述信息(如文本、文檔、推文、演講),并對它們進行語義分類或情緒理解。
情緒分析對于理解人們如何看待產品或服務特別有用。在醫療保健領域,情緒分析被用來衡量患者的情緒,以及識別那些有心力衰竭風險的患者。然后,這些文本摘要將作為分析過程的輸入,用于預測建模、決策分析、搜索或回答問題的機器人。
圖1-6概述了這樣一個自然語言處理的普遍過程。

▲圖1-6 自然語言處理過程示意圖
NLP的一個非常實際的應用是在市場營銷領域,文本用于理解客戶對某商品(通常指品牌或產品)的整體“情感”。這里的情感指的是如何理解客戶的情緒并對情緒進行提煉與歸類。除了情感分析,NLP還可以有多種應用,比如:
- 語法檢查
- 實體提取
- 翻譯
- 搜索
- 標準化
- 回答問題
- 拓展學習:欲了解更多自然語言處理中使用的技術,請閱讀Matthew Mayo的文章:https://www.kdnuggets.com/2017/02/natural-language-processing-key-terms-explained.html
自然語言生成(Natural Language Generation,NLG)是人工智能和NLP研究的一個子集,它指自動從結構化數據中生成有意義的、可閱讀的文本。與NLP不同,NLG走的是另一條研究道路。
也就是說,NLG以數據或其他形式的信息作為輸入,以文本作為輸出。
NLG已經被廣泛應用于各種聊天機器人,從客戶服務(見Pathania和Guzma,Chatbots in Customer Service)到疾病癥狀診斷。聊天機器人只是NLG的一種應用,其他應用還包括自動化完成下列事項:
- 把商業智能報表歸納成完整的分析報告(Qlik、Tableau、TIBCO、Microstrategy、Sisense、Information Builders都提供這類方法)
- 自動創建財務報表并完成分析(Nanalyze軟件提供此類功能)
- 制作每日體育資訊簡報(StatsMonkey提供此類功能)
- 自動編制客戶服務代表的績效評估(Narrative Science公司的Quill軟件提供此類功能)
- 在客戶關系管理系統中自動創建CRM話術腳本,建議銷售機會(Yseop的Savvy提供此類功能)
- 為小企業提供智能的“財務分析師”整體解決方案(Arria公司的Recount軟件提供此類功能)
歷史上,自然語言處理領域涉及規則的直接編碼,以便處理語言本體,定義單詞的結構,理解內容和上下文,以及它們在日常語言中的使用方式。統計計算、計算語言學和機器學習的現代進步正以前所未有的速度改變著NLP的世界。
04 文本挖掘與文本分析
一般來說,文本分析中最令人困惑的一個方面可能是NLP和文本挖掘之間的區別。就像在數據挖掘中所做的一樣,我們試圖從數據中提取有用的信息。在文本分析情況下,數據恰好是文本,從中提取的信息包括在文本數據中發現的模式和趨勢。
文本挖掘處理文本數據本身,我們試圖回答諸如詞匯的頻率、句子長度、某些文本字符串的存在或不存在等問題。我們可以解決概述的問題(例如,使用NLP中的技術進行分類)。本質上,文本挖掘通常是NLP的前奏。
文本分析涵蓋的范圍廣泛,通常包括應用統計分析、機器學習和其他一些高級分析技術,但通常被認為等同于文本挖掘。我覺得這是個灰色地帶。
注意,在商業智能領域人們經常使用文本分析這一術語,以表示更多的簡單行動可以通過典型的報表方式(例如詞云、詞頻分析等),以一種自動和可視化的方式完成。
文本挖掘一般是數據科學家喜歡使用的提法,他們雖然擁有很多更先進的方法,但那些在文本挖掘中需要做的計數、統計之類的基礎事務也是他們復雜工作的一部分。我認為這符合我的觀點,即分析是商業智能(BI)的一種自然進化。
需要特別注意的是,不同的社區、不同的場景,會使用不同的術語,這在實際工作中可能會引起一些理解的混淆。例如,參見:
www.linguamatics.com/blog/are-terms-text-mining-and-text-analytics-largely-inter changeable
05 機器學習
美國最大的私營軟件公司和分析巨頭SAS公司將機器學習定義為:
……一種自動建立分析模型的數據分析方法。機器學習使用數據迭代學習的算法,使計算機能夠在無須顯式編程的情況下具有找到隱藏見解的洞察力。
機器學習的核心是使用算法來建立量化分析模型,幫助計算機模型從數據中“學習”。它同以人為中心的處理過程不同,它是由計算機學習和發現隱藏在數據中的模式,而不是由人去直接建立模型。
一般而言,機器學習中模型建立和模型管理的概念是指能夠持續并且重復開展后續的決策流程,而不是高度人工參與的常常基于統計手段的分析。
隨著近年來計算能力的進步,機器學習可以用來自動地實現針對大數據的復雜數學計算,而這在以前是不可能實現的。
人類通常每周可以建立一到兩個好的模型,而機器學習每周可以創建數千個模型。
——Thomas H.Davenpot,分析思想領袖(Davenport,2013年)
圖1-7概述了機器學習中的常見方法。
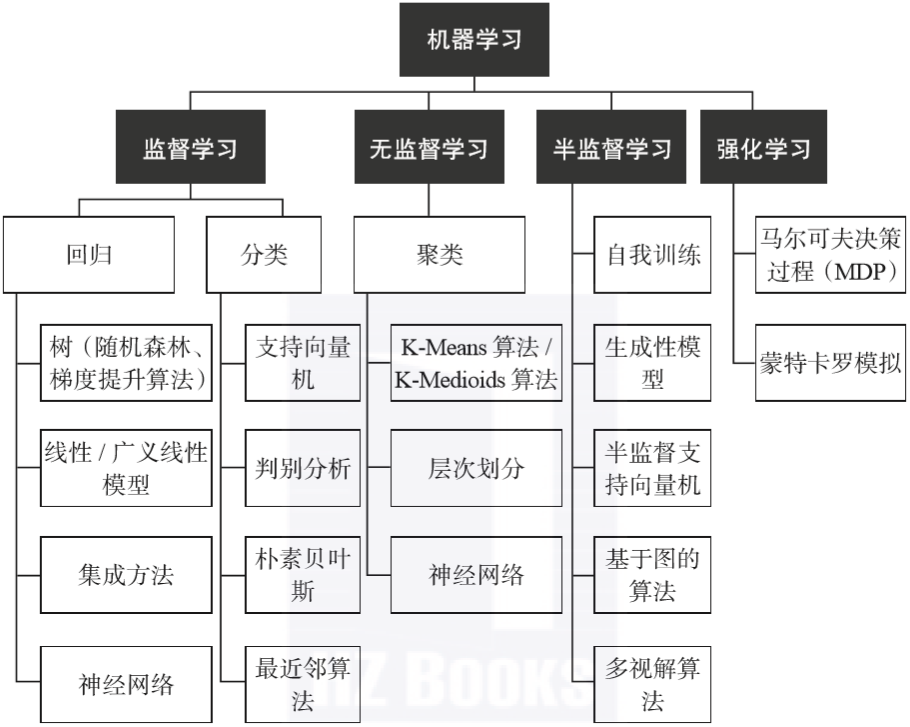
▲圖1-7 機器學習常用技術歸納
- 拓展學習:要學習更多相關知識及機器學習中的其他術語,請訪問谷歌開發者機器學習詞匯表,網址為:developers.google.com/machine-learning/glossary/
人們通常根據計算機的“學習模式”對機器學習算法進行分類(記住,機器學習就是讓計算機通過分析數據中的模式來提煉規律),也就是說,針對同樣的數據,可以有不同的機器學習算法來對真實世界(問題)建模。
一般而言,有四種機器學習模式或者學習模型算法,它們的區別在于輸入變量扮演的角色不同,以及如何為訓練模型準備數據。
表1-1概述了不同機器學習算法的差異。
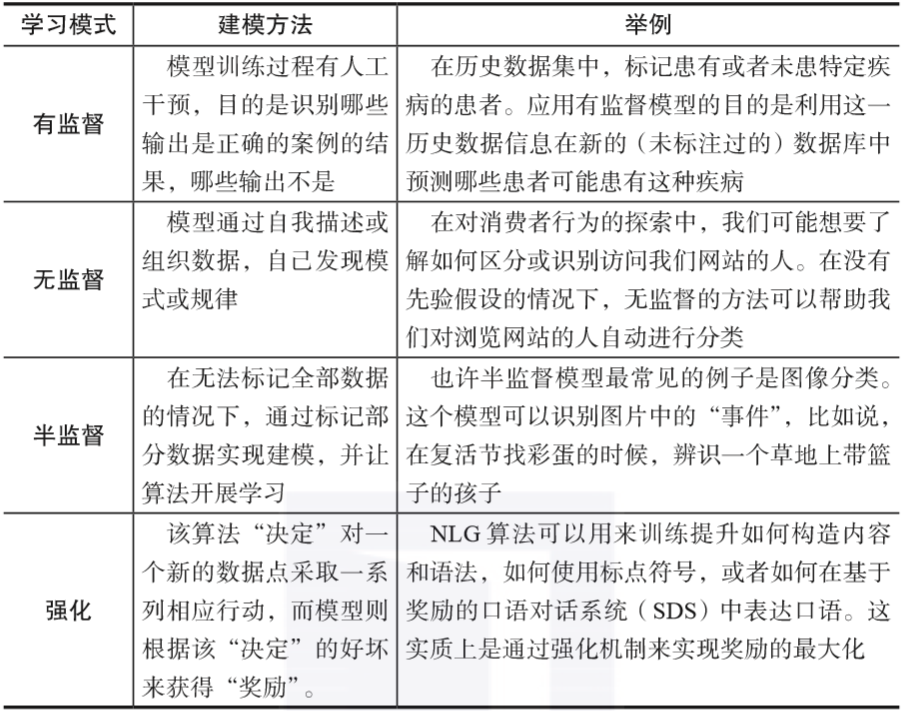
表1-1 機器學習模式
06 數據挖掘
- 數據挖掘:數據挖掘是在(通常是大型)數據集中發現和解釋規律模式,以解決業務問題的過程。
在20世紀90年代末和21世紀初,數據挖掘作為一種分析大型數據庫以生成新的或與眾不同的信息的方法而被廣泛應用。數據挖掘界的夢想是“找到干草堆中的一根針”。數據挖掘與統計學不同的是,在數據探索之前,不一定有一個先驗的理論驅動假說。
- 先驗:“先驗”被定義為“從早期開始”,或者簡單地解釋為“事先”。先驗假設是在進行實驗或收集數據之前陳述的假設。
數據挖掘采用傳統的統計方法以及人工智能和機器學習技術,目的是在我們擁有的數據中識別出以前未知的模式并進行預測。
就像分析中采用的其他技術一樣,數據挖掘遵循這樣一個生命周期:通常從問題描述開始,然后對數據進行理解,再進行模型構建,并根據結果采取相應行動。
一般情況下,數據挖掘人員識別出感興趣的輸出變量,然后使用各種技術對數據進行預處理(如聚類、主成分分析和關聯規則學習),然后將這些輸出變量作為輸入應用到數據挖掘算法中,如回歸算法、神經網絡、決策樹或支持向量機。
數據挖掘過程中的一個關鍵部分是模型評估和確保我們不會過度擬合模型。




















