













徹底理解 IO 多路復用實現機制
前言
- BIO 、NIO 、AIO 總結
- Unix網絡編程中的五種IO模型
為了加深對 I/O多路復用機制 的理解,以及了解到多路復用也有局限性,本著打破砂鍋問到底的精神,前面我們講了BIO、NIO、AIO的基本概念以及一些常見問題,同時也回顧了Unix網絡編程中的五種IO模型。本篇重點學習理解IO多路復用的底層實現機制。
概念說明
IO 多路復用有三種實現,在介紹select、poll、epoll之前,首先介紹一下Linux操作系統中基礎的概念:
- 用戶空間和內核空間
- 進程切換
- 進程的阻塞
- 文件描述符
- 緩存 I/O
用戶空間 / 內核空間
現在操作系統都是采用虛擬存儲器,那么對32位操作系統而言,它的尋址空間(虛擬存儲空間)為4G(2的32次方)。 操作系統的核心是內核,獨立于普通的應用程序,可以訪問受保護的內存空間,也有訪問底層硬件設備的所有權限。為了保證用戶進程不能直接操作內核(kernel),保證內核的安全,操作系統將虛擬空間劃分為兩部分,一部分為內核空間,一部分為用戶空間。
針對linux操作系統而言,將最高的1G字節(從虛擬地址0xC0000000到0xFFFFFFFF),供內核使用,稱為內核空間,而將較低的3G字節(從虛擬地址0x00000000到0xBFFFFFFF),供各個進程使用,稱為用戶空間。
進程切換
為了控制進程的執行,內核必須有能力掛起正在CPU上運行的進程,并恢復以前掛起的某個進程的執行。這種行為被稱為進程切換。因此可以說,任何進程都是在操作系統內核的支持下運行的,是與內核緊密相關的,并且進程切換是非常耗費資源的。
從一個進程的運行轉到另一個進程上運行,這個過程中經過下面這些變化:
- 保存處理機上下文,包括程序計數器和其他寄存器。
- 更新PCB信息。
- 把進程的PCB移入相應的隊列,如就緒、在某事件阻塞等隊列。
- 選擇另一個進程執行,并更新其PCB。
- 更新內存管理的數據結構。
- 恢復處理機上下文。
進程阻塞
正在執行的進程,由于期待的某些事件未發生,如請求系統資源失敗、等待某種操作的完成、新數據尚未到達或無新工作做等,則由系統自動執行阻塞原語(Block),使自己由運行狀態變為阻塞狀態。可見,進程的阻塞是進程自身的一種主動行為,也因此只有處于運行態的進程(獲得了CPU資源),才可能將其轉為阻塞狀態。當進程進入阻塞狀態,是不占用CPU資源的。
文件描述符
文件描述符(File descriptor)是計算機科學中的一個術語,是一個用于表述指向文件的引用的抽象化概念。 文件描述符在形式上是一個非負整數。實際上,它是一個索引值,指向內核為每一個進程所維護的該進程打開文件的記錄表。當程序打開一個現有文件或者創建一個新文件時,內核向進程返回一個文件描述符。在程序設計中,一些涉及底層的程序編寫往往會圍繞著文件描述符展開。但是文件描述符這一概念往往只適用于UNIX、Linux這樣的操作系統。
緩存I/O
緩存I/O又稱為標準I/O,大多數文件系統的默認I/O操作都是緩存I/O。在Linux的緩存I/O機制中,操作系統會將I/O的數據緩存在文件系統的頁緩存中,即數據會先被拷貝到操作系統內核的緩沖區中,然后才會從操作系統內核的緩沖區拷貝到應用程序的地址空間。
緩存 I/O 的缺點:
數據在傳輸過程中需要在應用程序地址空間和內核進行多次數據拷貝操作,這些數據拷貝操作所帶來的 CPU 以及內存開銷是非常大的。
什么是IO多路復用?
- IO 多路復用是一種同步IO模型,實現一個線程可以監視多個文件句柄;
- 一旦某個文件句柄就緒,就能夠通知應用程序進行相應的讀寫操作;
- 沒有文件句柄就緒就會阻塞應用程序,交出CPU。
多路是指網絡連接,復用指的是同一個線程
為什么有IO多路復用機制?
沒有IO多路復用機制時,有BIO、NIO兩種實現方式,但它們都有一些問題
同步阻塞(BIO)
服務端采用單線程,當 accept 一個請求后,在 recv 或 send 調用阻塞時,將無法 accept 其他請求(必須等上一個請求處理 recv 或 send 完 )(無法處理并發)
- // 偽代碼描述
- while (true) {
- // accept阻塞
- client_fd = accept(listen_fd);
- fds.append(client_fd);
- for (fd in fds) {
- // recv阻塞(會影響上面的accept)
- if (recv(fd)) {
- // logic
- }
- }
- }
- 服務端采用多線程,當 accept 一個請求后,開啟線程進行 recv,可以完成并發處理,但隨著請求數增加需要增加系統線程,大量的線程占用很大的內存空間,并且線程切換會帶來很大的開銷,10000個線程真正發生讀寫實際的線程數不會超過20%,每次accept都開一個線程也是一種資源浪費。
- // 偽代碼描述
- while(true) {
- // accept阻塞
- client_fd = accept(listen_fd)
- // 開啟線程read數據(fd增多導致線程數增多)
- new Thread func() {
- // recv阻塞(多線程不影響上面的accept)
- if (recv(fd)) {
- // logic
- }
- }
- }
同步非阻塞(NIO)
- 服務器端當 accept 一個請求后,加入 fds 集合,每次輪詢一遍 fds 集合 recv (非阻塞)數據,沒有數據則立即返回錯誤,每次輪詢所有 fd (包括沒有發生讀寫實際的 fd)會很浪費 CPU。
- // 偽代碼描述
- while(true) {
- // accept非阻塞(cpu一直忙輪詢)
- client_fd = accept(listen_fd)
- if (client_fd != null) {
- // 有人連接
- fds.append(client_fd)
- } else {
- // 無人連接
- }
- for (fd in fds) {
- // recv非阻塞
- setNonblocking(client_fd)
- // recv 為非阻塞命令
- if (len = recv(fd) && len > 0) {
- // 有讀寫數據
- // logic
- } else {
- 無讀寫數據
- }
- }
- }
IO多路復用
服務器端采用單線程通過 select/poll/epoll 等系統調用獲取 fd 列表,遍歷有事件的 fd 進行 accept/recv/send ,使其能支持更多的并發連接請求。
- // 偽代碼描述
- while(true) {
- // 通過內核獲取有讀寫事件發生的fd,只要有一個則返回,無則阻塞
- // 整個過程只在調用select、poll、epoll這些調用的時候才會阻塞,accept/recv是不會阻塞
- for (fd in select(fds)) {
- if (fd == listen_fd) {
- client_fd = accept(listen_fd)
- fds.append(client_fd)
- } elseif (len = recv(fd) && len != -1) {
- // logic
- }
- }
- }
IO多路復用的三種實現
- select
- poll
- epoll
select
它僅僅知道了,有I/O事件發生了,卻并不知道是哪那幾個流(可能有一個,多個,甚至全部),我們只能無差別輪詢所有流,找出能讀出數據,或者寫入數據的流,對他們進行操作。所以select具有O(n)的無差別輪詢復雜度,同時處理的流越多,無差別輪詢時間就越長。
select調用過程
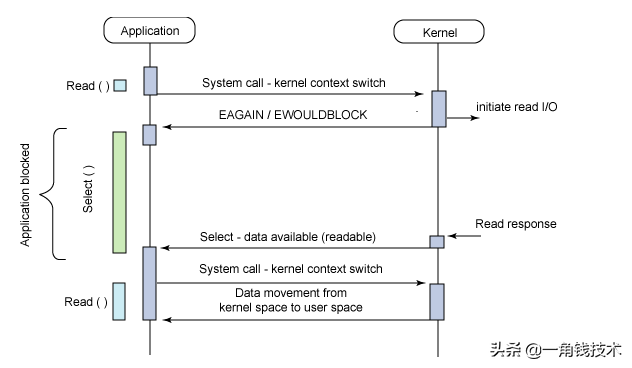
(1)使用copy_from_user從用戶空間拷貝fd_set到內核空間
(2)注冊回調函數__pollwait
(3)遍歷所有fd,調用其對應的poll方法(對于socket,這個poll方法是sock_poll,sock_poll根據情況會調用到tcp_poll,udp_poll或者datagram_poll)
(4)以tcp_poll為例,其核心實現就是__pollwait,也就是上面注冊的回調函數。
(5)__pollwait的主要工作就是把current(當前進程)掛到設備的等待隊列中,不同的設備有不同的等待隊列,對于tcp_poll來說,其等待隊列是sk->sk_sleep(注意把進程掛到等待隊列中并不代表進程已經睡眠了)。在設備收到一條消息(網絡設備)或填寫完文件數據(磁盤設備)后,會喚醒設備等待隊列上睡眠的進程,這時current便被喚醒了。
(6)poll方法返回時會返回一個描述讀寫操作是否就緒的mask掩碼,根據這個mask掩碼給fd_set賦值。
(7)如果遍歷完所有的fd,還沒有返回一個可讀寫的mask掩碼,則會調用schedule_timeout是調用select的進程(也就是current)進入睡眠。當設備驅動發生自身資源可讀寫后,會喚醒其等待隊列上睡眠的進程。如果超過一定的超時時間(schedule_timeout指定),還是沒人喚醒,則調用select的進程會重新被喚醒獲得CPU,進而重新遍歷fd,判斷有沒有就緒的fd。
(8)把fd_set從內核空間拷貝到用戶空間。
select函數接口
- #include <sys/select.h>
- #include <sys/time.h>
- #define FD_SETSIZE 1024
- #define NFDBITS (8 * sizeof(unsigned long))
- #define __FDSET_LONGS (FD_SETSIZE/NFDBITS)
- // 數據結構 (bitmap)
- typedef struct {
- unsigned long fds_bits[__FDSET_LONGS];
- } fd_set;
- // API
- int select(
- int max_fd,
- fd_set *readset,
- fd_set *writeset,
- fd_set *exceptset,
- struct timeval *timeout
- ) // 返回值就緒描述符的數目
- FD_ZERO(int fd, fd_set* fds) // 清空集合
- FD_SET(int fd, fd_set* fds) // 將給定的描述符加入集合
- FD_ISSET(int fd, fd_set* fds) // 判斷指定描述符是否在集合中
- FD_CLR(int fd, fd_set* fds) // 將給定的描述符從文件中刪除
select使用示例
- int main() {
- /*
- * 這里進行一些初始化的設置,
- * 包括socket建立,地址的設置等,
- */
- fd_set read_fs, write_fs;
- struct timeval timeout;
- int max = 0; // 用于記錄最大的fd,在輪詢中時刻更新即可
- // 初始化比特位
- FD_ZERO(&read_fs);
- FD_ZERO(&write_fs);
- int nfds = 0; // 記錄就緒的事件,可以減少遍歷的次數
- while (1) {
- // 阻塞獲取
- // 每次需要把fd從用戶態拷貝到內核態
- nfds = select(max + 1, &read_fd, &write_fd, NULL, &timeout);
- // 每次需要遍歷所有fd,判斷有無讀寫事件發生
- for (int i = 0; i <= max && nfds; ++i) {
- if (i == listenfd) {
- --nfds;
- // 這里處理accept事件
- FD_SET(i, &read_fd);//將客戶端socket加入到集合中
- }
- if (FD_ISSET(i, &read_fd)) {
- --nfds;
- // 這里處理read事件
- }
- if (FD_ISSET(i, &write_fd)) {
- --nfds;
- // 這里處理write事件
- }
- }
- }
select缺點
select本質上是通過設置或者檢查存放fd標志位的數據結構來進行下一步處理。這樣所帶來的缺點是:
- 單個進程所打開的FD是有限制的,通過 FD_SETSIZE 設置,默認1024 ;
- 每次調用 select,都需要把 fd 集合從用戶態拷貝到內核態,這個開銷在 fd 很多時會很大;
需要維護一個用來存放大量fd的數據結構,這樣會使得用戶空間和內核空間在傳遞該結構時復制開銷大
- 對 socket 掃描時是線性掃描,采用輪詢的方法,效率較低(高并發)
當套接字比較多的時候,每次select()都要通過遍歷FD_SETSIZE個Socket來完成調度,不管哪個Socket是活躍的,都遍歷一遍。這會浪費很多CPU時間。如果能給套接字注冊某個回調函數,當 他們活躍時,自動完成相關操作,那就避免了輪詢,這正是epoll與kqueue做的。
poll
poll本質上和select沒有區別,它將用戶傳入的數組拷貝到內核空間,然后查詢每個fd對應的設備狀態, 但是它沒有最大連接數的限制,原因是它是基于鏈表來存儲的.
poll函數接口
- #include <poll.h>
- // 數據結構
- struct pollfd {
- int fd; // 需要監視的文件描述符
- short events; // 需要內核監視的事件
- short revents; // 實際發生的事件
- };
- // API
- int poll(struct pollfd fds[], nfds_t nfds, int timeout);
poll使用示例
- // 先宏定義長度
- #define MAX_POLLFD_LEN 4096
- int main() {
- /*
- * 在這里進行一些初始化的操作,
- * 比如初始化數據和socket等。
- */
- int nfds = 0;
- pollfd fds[MAX_POLLFD_LEN];
- memset(fds, 0, sizeof(fds));
- fds[0].fd = listenfd;
- fds[0].events = POLLRDNORM;
- int max = 0; // 隊列的實際長度,是一個隨時更新的,也可以自定義其他的
- int timeout = 0;
- int current_size = max;
- while (1) {
- // 阻塞獲取
- // 每次需要把fd從用戶態拷貝到內核態
- nfds = poll(fds, max+1, timeout);
- if (fds[0].revents & POLLRDNORM) {
- // 這里處理accept事件
- connfd = accept(listenfd);
- //將新的描述符添加到讀描述符集合中
- }
- // 每次需要遍歷所有fd,判斷有無讀寫事件發生
- for (int i = 1; i < max; ++i) {
- if (fds[i].revents & POLLRDNORM) {
- sockfd = fds[i].fd
- if ((n = read(sockfd, buf, MAXLINE)) <= 0) {
- // 這里處理read事件
- if (n == 0) {
- close(sockfd);
- fds[i].fd = -1;
- }
- } else {
- // 這里處理write事件
- }
- if (--nfds <= 0) {
- break;
- }
- }
- }
- }
poll缺點
它沒有最大連接數的限制,原因是它是基于鏈表來存儲的,但是同樣有缺點:
- 每次調用 poll ,都需要把 fd 集合從用戶態拷貝到內核態,這個開銷在 fd 很多時會很大;
- 對 socket 掃描是線性掃描,采用輪詢的方法,效率較低(高并發時)
epoll
epoll可以理解為event poll,不同于忙輪詢和無差別輪詢,epoll會把哪個流發生了怎樣的I/O事件通知我們。所以我們說epoll實際上是**事件驅動(每個事件關聯上fd)**的,此時我們對這些流的操作都是有意義的。(復雜度降低到了O(1))
epoll函數接口
當某一進程調用epoll_create方法時,Linux內核會創建一個eventpoll結構體,這個結構體中有兩個成員與epoll的使用方式密切相關。eventpoll結構體如下所示:
- #include <sys/epoll.h>
- // 數據結構
- // 每一個epoll對象都有一個獨立的eventpoll結構體
- // 用于存放通過epoll_ctl方法向epoll對象中添加進來的事件
- // epoll_wait檢查是否有事件發生時,只需要檢查eventpoll對象中的rdlist雙鏈表中是否有epitem元素即可
- struct eventpoll {
- /*紅黑樹的根節點,這顆樹中存儲著所有添加到epoll中的需要監控的事件*/
- struct rb_root rbr;
- /*雙鏈表中則存放著將要通過epoll_wait返回給用戶的滿足條件的事件*/
- struct list_head rdlist;
- };
- // API
- int epoll_create(int size); // 內核中間加一個 ep 對象,把所有需要監聽的 socket 都放到 ep 對象中
- int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); // epoll_ctl 負責把 socket 增加、刪除到內核紅黑樹
- int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);// epoll_wait 負責檢測可讀隊列,沒有可讀 socket 則阻塞進程
每一個epoll對象都有一個獨立的eventpoll結構體,用于存放通過epoll_ctl方法向epoll對象中添加進來的事件。這些事件都會掛載在紅黑樹中,如此,重復添加的事件就可以通過紅黑樹而高效的識別出來(紅黑樹的插入時間效率是lgn,其中n為紅黑樹元素個數)。
而所有添加到epoll中的事件都會與設備(網卡)驅動程序建立回調關系,也就是說,當相應的事件發生時會調用這個回調方法。這個回調方法在內核中叫ep_poll_callback,它會將發生的事件添加到rdlist雙鏈表中。
在epoll中,對于每一個事件,都會建立一個epitem結構體,如下所示:
- struct epitem{
- struct rb_node rbn;//紅黑樹節點
- struct list_head rdllink;//雙向鏈表節點
- struct epoll_filefd ffd; //事件句柄信息
- struct eventpoll *ep; //指向其所屬的eventpoll對象
- struct epoll_event event; //期待發生的事件類型
- }
當調用epoll_wait檢查是否有事件發生時,只需要檢查eventpoll對象中的rdlist雙鏈表中是否有epitem元素即可。如果rdlist不為空,則把發生的事件復制到用戶態,同時將事件數量返回給用戶。
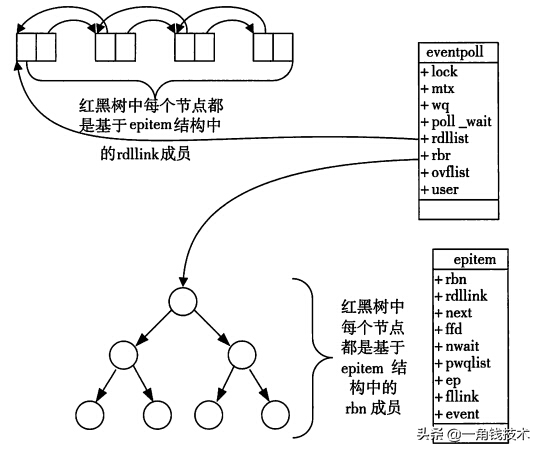
從上面的講解可知:通過紅黑樹和雙鏈表數據結構,并結合回調機制,造就了epoll的高效。 講解完了Epoll的機理,我們便能很容易掌握epoll的用法了。一句話描述就是:三步曲。
- 第一步:epoll_create()系統調用。此調用返回一個句柄,之后所有的使用都依靠這個句柄來標識。
- 第二步:epoll_ctl()系統調用。通過此調用向epoll對象中添加、刪除、修改感興趣的事件,返回0標識成功,返回-1表示失敗。
- 第三部:epoll_wait()系統調用。通過此調用收集收集在epoll監控中已經發生的事件。
epoll使用示例
- int main(int argc, char* argv[])
- {
- /*
- * 在這里進行一些初始化的操作,
- * 比如初始化數據和socket等。
- */
- // 內核中創建ep對象
- epfd=epoll_create(256);
- // 需要監聽的socket放到ep中
- epoll_ctl(epfd,EPOLL_CTL_ADD,listenfd,&ev);
- while(1) {
- // 阻塞獲取
- nfds = epoll_wait(epfd,events,20,0);
- for(i=0;i<nfds;++i) {
- if(events[i].data.fd==listenfd) {
- // 這里處理accept事件
- connfd = accept(listenfd);
- // 接收新連接寫到內核對象中
- epoll_ctl(epfd,EPOLL_CTL_ADD,connfd,&ev);
- } else if (events[i].events&EPOLLIN) {
- // 這里處理read事件
- read(sockfd, BUF, MAXLINE);
- //讀完后準備寫
- epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);
- } else if(events[i].events&EPOLLOUT) {
- // 這里處理write事件
- write(sockfd, BUF, n);
- //寫完后準備讀
- epoll_ctl(epfd,EPOLL_CTL_MOD,sockfd,&ev);
- }
- }
- }
- return 0;
- }
epoll的優點
- 沒有最大并發連接的限制,能打開的FD的上限遠大于1024(1G的內存上能監聽約10萬個端口);
- 效率提升,不是輪詢的方式,不會隨著FD數目的增加效率下降。只有活躍可用的FD才會調用callback函數;即Epoll最大的優點就在于它只管你“活躍”的連接,而跟連接總數無關,因此在實際的網絡環境中,Epoll的效率就會遠遠高于select和poll;
- 內存拷貝,利用mmap()文件映射內存加速與內核空間的消息傳遞;即epoll使用mmap減少復制開銷。
epoll缺點
- epoll只能工作在 linux 下
epoll LT 與 ET 模式的區別
epoll 有 EPOLLLT 和 EPOLLET 兩種觸發模式,LT 是默認的模式,ET 是 “高速” 模式。
- LT 模式下,只要這個 fd 還有數據可讀,每次 epoll_wait 都會返回它的事件,提醒用戶程序去操作;
- ET 模式下,它只會提示一次,直到下次再有數據流入之前都不會再提示了,無論 fd 中是否還有數據可讀。所以在 ET 模式下,read 一個 fd 的時候一定要把它的 buffer 讀完,或者遇到 EAGIN 錯誤。
epoll使用“事件”的就緒通知方式,通過epoll_ctl注冊fd,一旦該fd就緒,內核就會采用類似callback的回調機制來激活該fd,epoll_wait便可以收到通知。
select/poll/epoll之間的區別
select,poll,epoll都是IO多路復用的機制。I/O多路復用就通過一種機制,可以監視多個描述符,一旦某個描述符就緒(一般是讀就緒或者寫就緒),能夠通知程序進行相應的讀寫操作。但select,poll,epoll本質上都是同步I/O,因為他們都需要在讀寫事件就緒后自己負責進行讀寫,也就是說這個讀寫過程是阻塞的,而異步I/O則無需自己負責進行讀寫,異步I/O的實現會負責把數據從內核拷貝到用戶空間。
epoll跟select都能提供多路I/O復用的解決方案。在現在的Linux內核里有都能夠支持,其中epoll是Linux所特有,而select則應該是POSIX所規定,一般操作系統均有實現
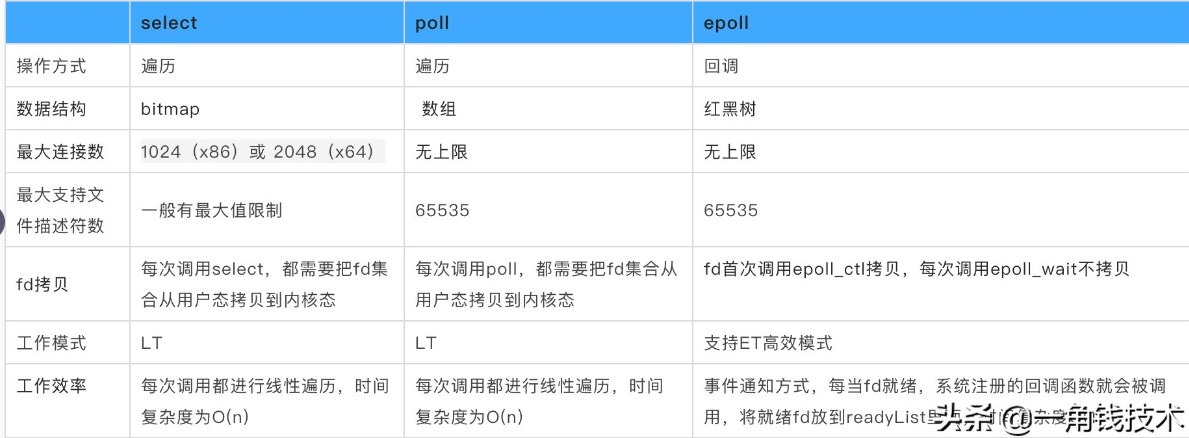
epoll是Linux目前大規模網絡并發程序開發的首選模型。在絕大多數情況下性能遠超select和poll。目前流行的高性能web服務器Nginx正式依賴于epoll提供的高效網絡套接字輪詢服務。但是,在并發連接不高的情況下,多線程+阻塞I/O方式可能性能更好。
支持一個進程所能打開的最大連接數
- select:單個進程所能打開的最大連接數有FD_SETSIZE宏定義,其大小是32個整數的大小(在32位的機器上,大小就是32_32,同理64位機器上FD_SETSIZE為32_64),當然我們可以對進行修改,然后重新編譯內核,但是性能可能會受到影響,這需要進一步的測試。
- poll:poll本質上和select沒有區別,但是它沒有最大連接數的限制,原因是它是基于鏈表來存儲的。
- epoll:雖然連接數有上限,但是很大,1G內存的機器上可以打開10萬左右的連接,2G內存的機器可以打開20萬左右的連接。
FD劇增后帶來的IO效率問題
- select:因為每次調用時都會對連接進行線性遍歷,所以隨著FD的增加會造成遍歷速度慢的“線性下降性能問題”。
- poll:同上
- epoll:因為epoll內核中實現是根據每個fd上的callback函數來實現的,只有活躍的socket才會主動調用callback,所以在活躍socket較少的情況下,使用epoll沒有前面兩者的線性下降的性能問題,但是所有socket都很活躍的情況下,可能會有性能問題。
消息傳遞方式
- select:內核需要將消息傳遞到用戶空間,都需要內核拷貝動作
- poll:同上
- epoll:epoll通過內核和用戶空間共享一塊內存來實現的。
總結
select,poll實現需要自己不斷輪詢所有fd集合,直到設備就緒,期間可能要睡眠和喚醒多次交替。而epoll其實也需要調用epoll_wait不斷輪詢就緒鏈表,期間也可能多次睡眠和喚醒交替,但是它是設備就緒時,調用回調函數,把就緒fd放入就緒鏈表中,并喚醒在epoll_wait中進入睡眠的進程。雖然都要睡眠和交替,但是select和poll在“醒著”的時候要遍歷整個fd集合,而epoll在“醒著”的時候只要判斷一下就緒鏈表是否為空就行了,這節省了大量的CPU時間。這就是回調機制帶來的性能提升。
select,poll每次調用都要把fd集合從用戶態往內核態拷貝一次,并且要把current往設備等待隊列中掛一次,而epoll只要一次拷貝,而且把current往等待隊列上掛也只掛一次(在epoll_wait的開始,注意這里的等待隊列并不是設備等待隊列,只是一個epoll內部定義的等待隊列)。這也能節省不少的開銷。
高頻面試題
什么是IO多路復用?
看完上面的文章,相信你可以回答出來了。
nginx/redis 所使用的IO模型是什么?
Nginx的IO模型
Nginx 支持多種并發模型,并發模型的具體實現根據系統平臺而有所不同。
在支持多種并發模型的平臺上,nginx 自動選擇最高效的模型。但我們也可以使用 use 指令在配置文件中顯式地定義某個并發模型。
NGINX中支持的并發模型:
1、select
IO多路復用、標準并發模型。在編譯 nginx 時,如果所使用的系統平臺沒有更高效的并發模型,select 模塊將被自動編譯。configure 腳本的選項:–with-select_module 和 --without-select_module 可被用來強制性地開啟或禁止 select 模塊的編譯
2、poll
IO多路復用、標準并發模型。與 select 類似,在編譯 nginx 時,如果所使用的系統平臺沒有更高效的并發模型,poll 模塊將被自動編譯。configure 腳本的選項:–with-poll_module 和 --without-poll_module 可用于強制性地開啟或禁止 poll 模塊的編譯
3、epoll
IO多路復用、高效并發模型,可在 Linux 2.6+ 及以上內核可以使用
4、kqueue
IO多路復用、高效并發模型,可在 FreeBSD 4.1+, OpenBSD 2.9+, NetBSD 2.0, and Mac OS X 平臺中使用
5、/dev/poll
高效并發模型,可在 Solaris 7 11/99+, HP/UX 11.22+ (eventport), IRIX 6.5.15+, and Tru64 UNIX 5.1A+ 平臺使用
6、eventport
高效并發模型,可用于 Solaris 10 平臺,PS:由于一些已知的問題,建議 使用/dev/poll替代。
Redis IO多路復用技術
redis 是一個單線程卻性能非常好的內存數據庫, 主要用來作為緩存系統。 redis 采用網絡IO多路復用技術來保證在多連接的時候, 系統的高吞吐量。
為什么 Redis 中要使用 I/O 多路復用這種技術呢?
首先,Redis 是跑在單線程中的,所有的操作都是按照順序線性執行的,但是由于讀寫操作等待用戶輸入或輸出都是阻塞的,所以 I/O 操作在一般情況下往往不能直接返回,這會導致某一文件的 I/O 阻塞導致整個進程無法對其它客戶提供服務,而 I/O 多路復用 就是為了解決這個問題而出現的。
redis的io模型主要是基于epoll實現的,不過它也提供了 select和kqueue的實現,默認采用epoll。
select、poll、epoll之間的區別
看完上面的文章,相信你可以回答出來了。
epoll 水平觸發(LT)與 邊緣觸發(ET)的區別?
EPOLL事件有兩種模型:
- Edge Triggered (ET) 邊緣觸發只有數據到來,才觸發,不管緩存區中是否還有數據。
- Level Triggered (LT) 水平觸發只要有數據都會觸發。
看完上面的文章,相信你可以回答出來了。


























