教你用Python寫(xiě)一個(gè)電信客戶流失預(yù)測(cè)模型
【導(dǎo)讀】
今天教大家如何用Python寫(xiě)一個(gè)電信用戶流失預(yù)測(cè)模型。之前我們用Python寫(xiě)了員工流失預(yù)測(cè)模型,這次我們?cè)囋嘝ython預(yù)測(cè)電信用戶的流失。
01、商業(yè)理解
流失客戶是指那些曾經(jīng)使用過(guò)產(chǎn)品或服務(wù),由于對(duì)產(chǎn)品失去興趣等種種原因,不再使用產(chǎn)品或服務(wù)的顧客。
電信服務(wù)公司、互聯(lián)網(wǎng)服務(wù)提供商、保險(xiǎn)公司等經(jīng)常使用客戶流失分析和客戶流失率作為他們的關(guān)鍵業(yè)務(wù)指標(biāo)之一,因?yàn)榱糇∫粋€(gè)老客戶的成本遠(yuǎn)遠(yuǎn)低于獲得一個(gè)新客戶。
預(yù)測(cè)分析使用客戶流失預(yù)測(cè)模型,通過(guò)評(píng)估客戶流失的風(fēng)險(xiǎn)傾向來(lái)預(yù)測(cè)客戶流失。由于這些模型生成了一個(gè)流失概率排序名單,對(duì)于潛在的高概率流失客戶,他們可以有效地實(shí)施客戶保留營(yíng)銷(xiāo)計(jì)劃。
下面我們就教你如何用Python寫(xiě)一個(gè)電信用戶流失預(yù)測(cè)模型,以下是具體步驟和關(guān)鍵代碼。
02、數(shù)據(jù)理解
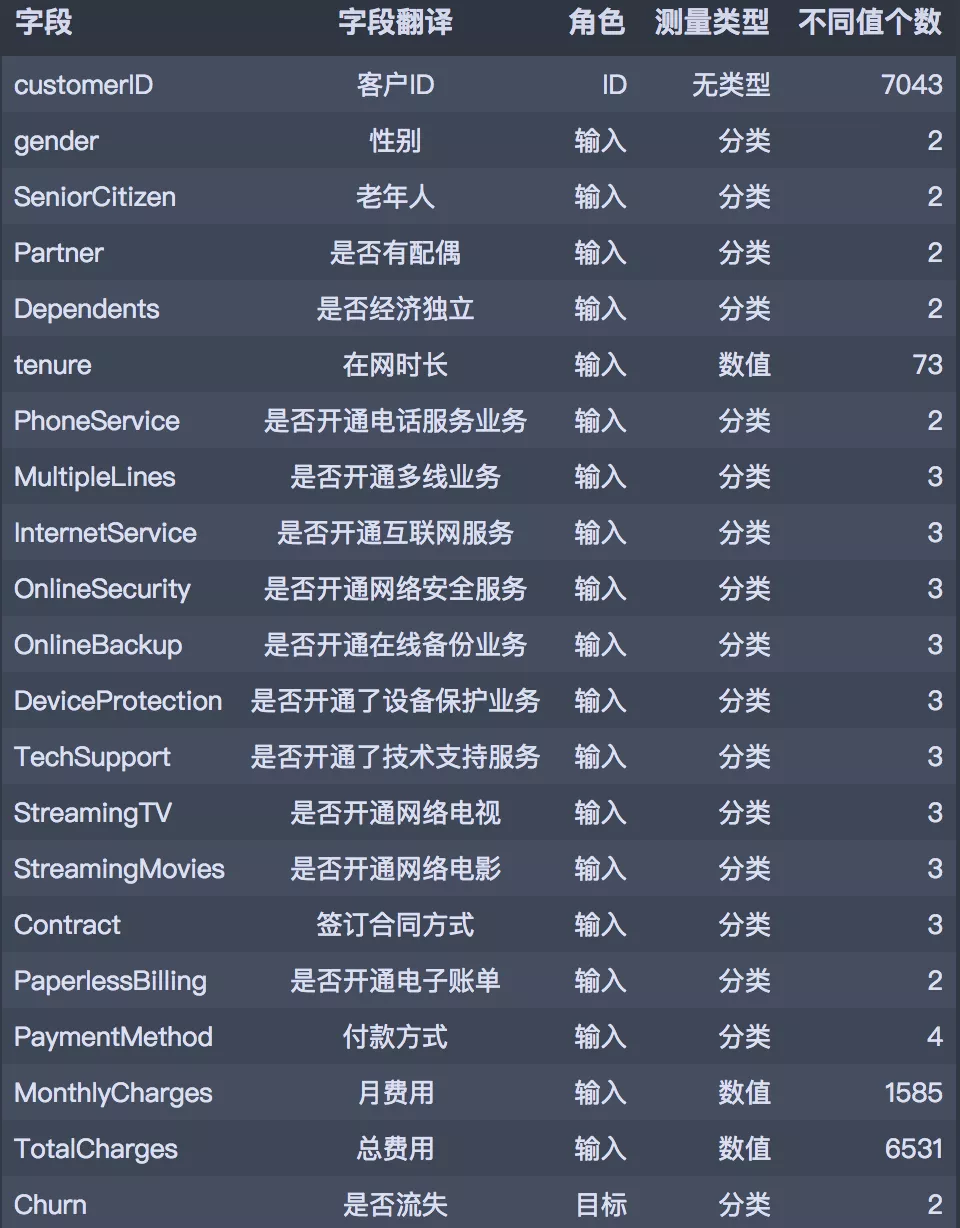
此次分析數(shù)據(jù)來(lái)自于IBM Sample Data Sets,統(tǒng)計(jì)自某電信公司一段時(shí)間內(nèi)的消費(fèi)數(shù)據(jù)。共有7043筆客戶資料,每筆客戶資料包含21個(gè)字段,其中1個(gè)客戶ID字段,19個(gè)輸入字段及1個(gè)目標(biāo)字段-Churn(Yes代表流失,No代表未流失),輸入字段主要包含以下三個(gè)維度指標(biāo):用戶畫(huà)像指標(biāo)、消費(fèi)產(chǎn)品指標(biāo)、消費(fèi)信息指標(biāo)。字段的具體說(shuō)明如下:
03、數(shù)據(jù)讀入和概覽
首先導(dǎo)入所需包。
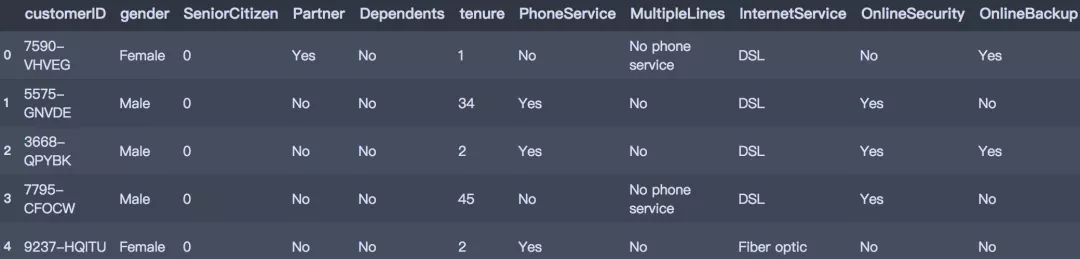
- df = pd.read_csv('./Telco-Customer-Churn.csv')
- df.head()
讀入數(shù)據(jù)集
- df = pd.read_csv('./Telco-Customer-Churn.csv')
- df.head()
04、數(shù)據(jù)初步清洗
首先進(jìn)行初步的數(shù)據(jù)清洗工作,包含錯(cuò)誤值和異常值處理,并劃分類別型和數(shù)值型字段類型,其中清洗部分包含:
- OnlineSecurity、OnlineBackup、DeviceProtection、TechSupport、StreamingTV、StreamingMovies:錯(cuò)誤值處理
- TotalCharges:異常值處理
- tenure:自定義分箱
- 定義類別型和數(shù)值型字段
- # 錯(cuò)誤值處理
- repl_columns = ['OnlineSecurity', 'OnlineBackup', 'DeviceProtection',
- 'TechSupport','StreamingTV', 'StreamingMovies']
- for i in repl_columns:
- df[i] = df[i].replace({'No internet service' : 'No'})
- # 替換值SeniorCitizen
- df["SeniorCitizen"] = df["SeniorCitizen"].replace({1: "Yes", 0: "No"})
- # 替換值TotalCharges
- df['TotalCharges'] = df['TotalCharges'].replace(' ', np.nan)
- # TotalCharges空值:數(shù)據(jù)量小,直接刪除
- df = df.dropna(subset=['TotalCharges'])
- df.reset_index(drop=True, inplace=True) # 重置索引
- # 轉(zhuǎn)換數(shù)據(jù)類型
- df['TotalCharges'] = df['TotalCharges'].astype('float')
- # 轉(zhuǎn)換tenure
- def transform_tenure(x):
- if x <= 12:
- return 'Tenure_1'
- elif x <= 24:
- return 'Tenure_2'
- elif x <= 36:
- return 'Tenure_3'
- elif x <= 48:
- return 'Tenure_4'
- elif x <= 60:
- return 'Tenure_5'
- else:
- return 'Tenure_over_5'
- df['tenure_group'] = df.tenure.apply(transform_tenure)
- # 數(shù)值型和類別型字段
- Id_col = ['customerID']
- target_col = ['Churn']
- cat_cols = df.nunique()[df.nunique() < 10].index.tolist()
- num_cols = [i for i in df.columns if i not in cat_cols + Id_col]
- print('類別型字段:\n', cat_cols)
- print('-' * 30)
- print('數(shù)值型字段:\n', num_cols)
- 類別型字段:
- ['gender', 'SeniorCitizen', 'Partner', 'Dependents', 'PhoneService',
- 'MultipleLines', 'InternetService', 'OnlineSecurity',
- 'OnlineBackup', 'DeviceProtection', 'TechSupport',
- 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling',
- 'PaymentMethod', 'Churn', 'tenure_group']
- ------------------------------
- 數(shù)值型字段:
- ['tenure', 'MonthlyCharges', 'TotalCharges']
05、探索性分析
對(duì)指標(biāo)進(jìn)行歸納梳理,分用戶畫(huà)像指標(biāo),消費(fèi)產(chǎn)品指標(biāo),消費(fèi)信息指標(biāo)。探索影響用戶流失的關(guān)鍵因素。
1. 目標(biāo)變量Churn分布
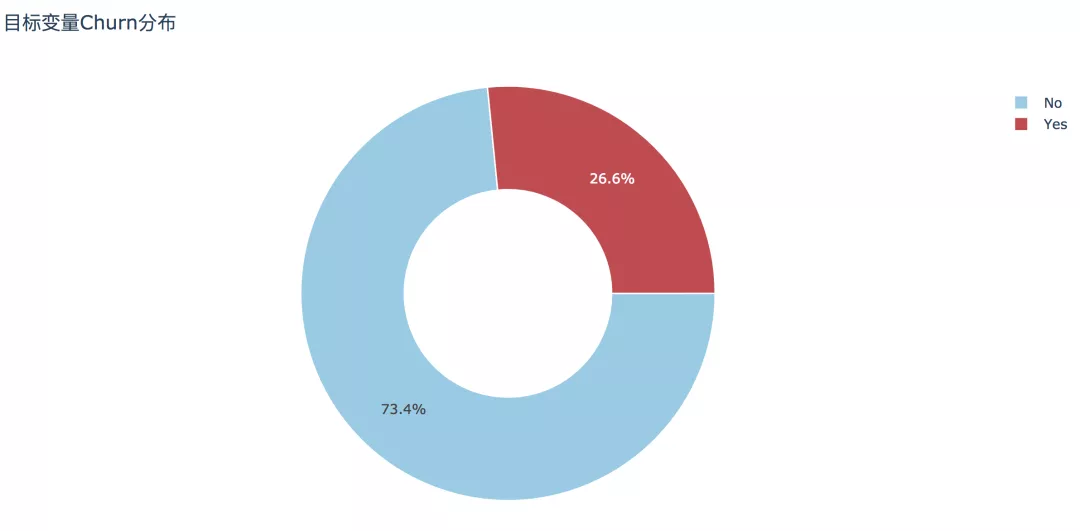
經(jīng)過(guò)初步清洗之后的數(shù)據(jù)集大小為7032條記錄,其中流失客戶為1869條,占比26.6%,未流失客戶占比73.4%。
- df['Churn'].value_counts()
- No 5163
- Yes 1869
- Name: Churn, dtype: int64
- trace0 = go.Pie(labels=df['Churn'].value_counts().index,
- values=df['Churn'].value_counts().values,
- hole=.5,
- rotation=90,
- marker=dict(colors=['rgb(154,203,228)', 'rgb(191,76,81)'],
- line=dict(color='white', width=1.3))
- )
- data = [trace0]
- layout = go.Layout(title='目標(biāo)變量Churn分布')
- fig = go.Figure(data=data, layout=layout)
- py.offline.plot(fig, filename='./html/整體流失情況分布.html')
2.性別
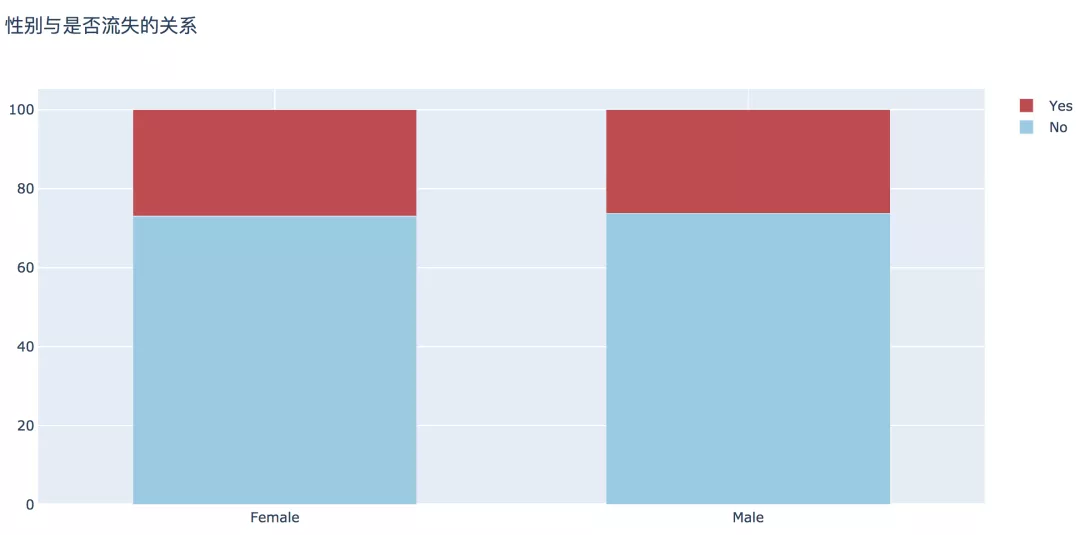
分析可見(jiàn),男性和女性在客戶流失比例上沒(méi)有顯著差異。
- plot_bar(input_col='gender', target_col='Churn', title_name='性別與是否流失的關(guān)系')
3. 老年用戶
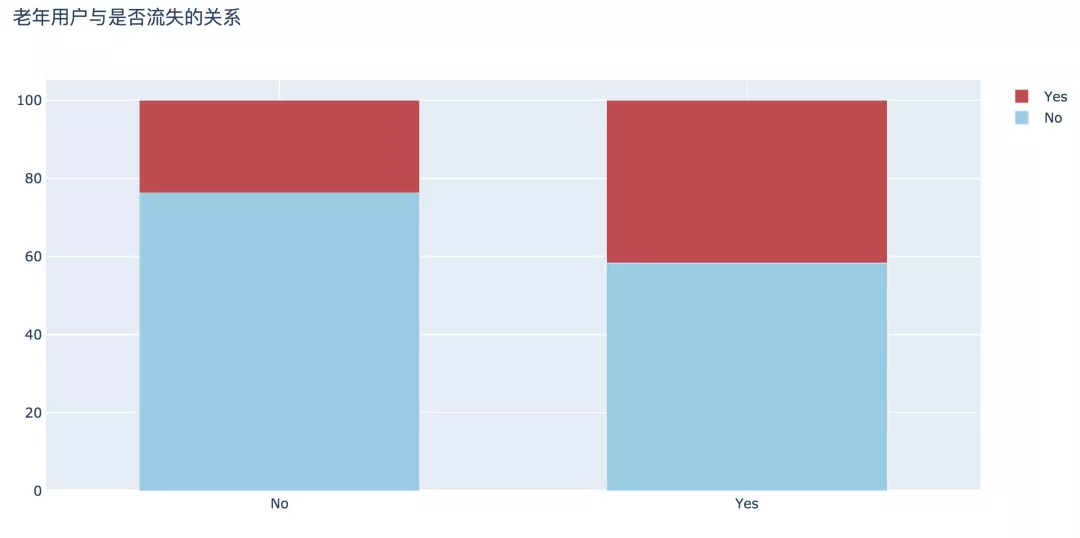
老年用戶流失比例更高,為41.68%,比非老年用戶高近兩倍,此部分原因有待進(jìn)一步探討。
- plot_bar(input_col='SeniorCitizen', target_col='Churn', title_name='老年用戶與是否流失的關(guān)系')
4. 是否有配偶
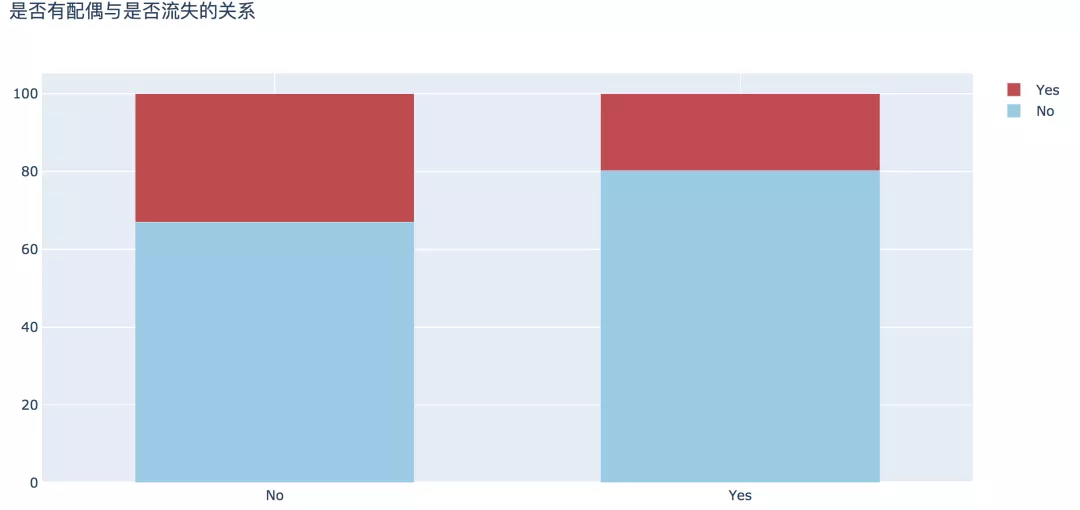
從婚姻情況來(lái)看,數(shù)據(jù)顯示,未婚人群中流失的比例比已婚人數(shù)高出13%。
- plot_bar(input_col='Partner', target_col='Churn', title_name='是否有配偶與是否流失的關(guān)系')
5. 上網(wǎng)時(shí)長(zhǎng)
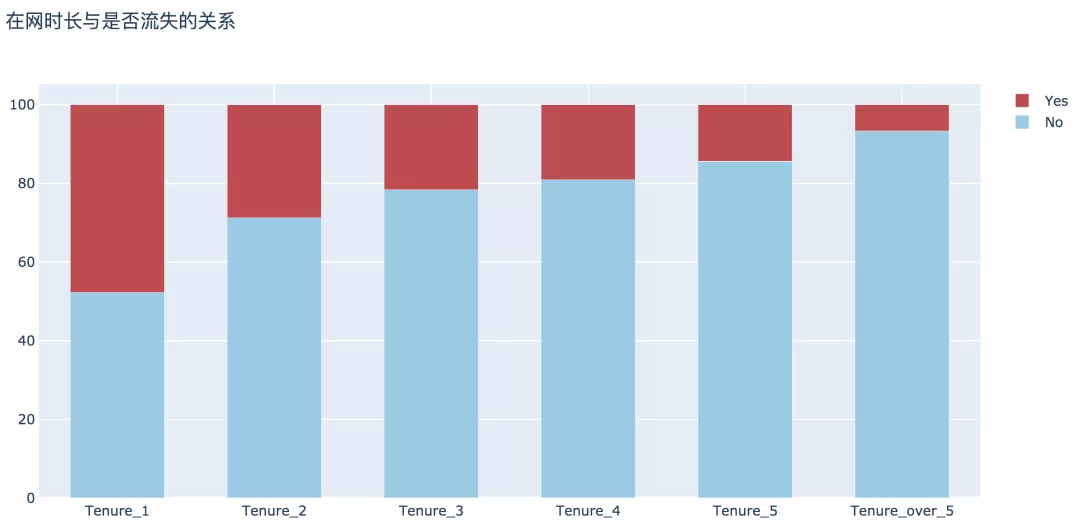
經(jīng)過(guò)分析,這方面可以得出兩個(gè)結(jié)論:
- 用戶的在網(wǎng)時(shí)長(zhǎng)越長(zhǎng),表示用戶的忠誠(chéng)度越高,其流失的概率越低;
- 新用戶在1年內(nèi)的流失率顯著高于整體流失率,為47.68%。
- plot_bar(input_col='tenure_group', target_col='Churn', title_name='在網(wǎng)時(shí)長(zhǎng)與是否流失的關(guān)系')
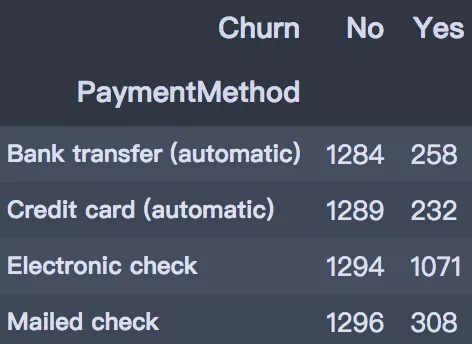
6. 付款方式
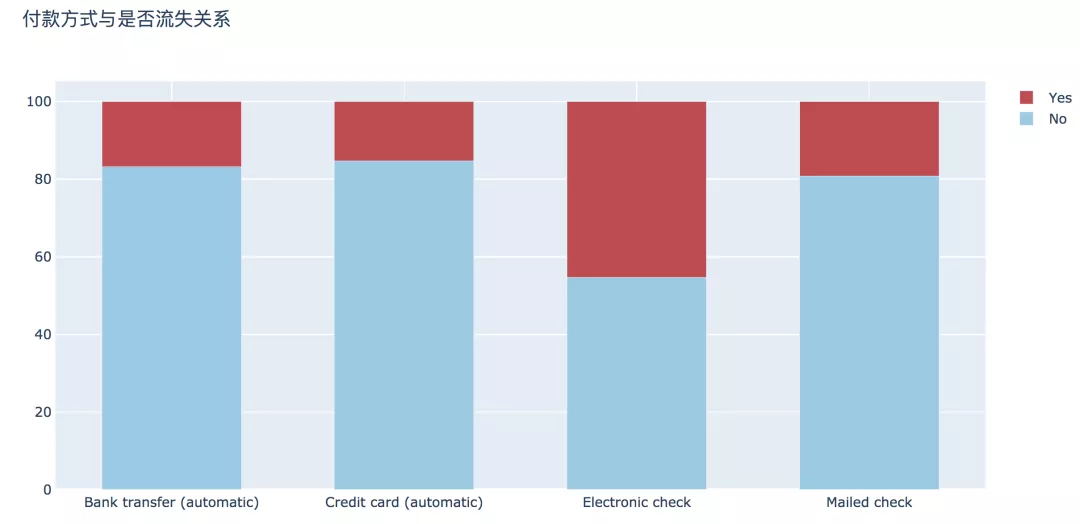
支付方式上,支付上,選擇電子支票支付方式的用戶流失最高,達(dá)到45.29%,其他三種支付方式的流失率相差不大。
- pd.crosstab(df['PaymentMethod'], df['Churn'])
- plot_bar(input_col='PaymentMethod', target_col='Churn', title_name='付款方式與是否流失關(guān)系')
7. 月費(fèi)用
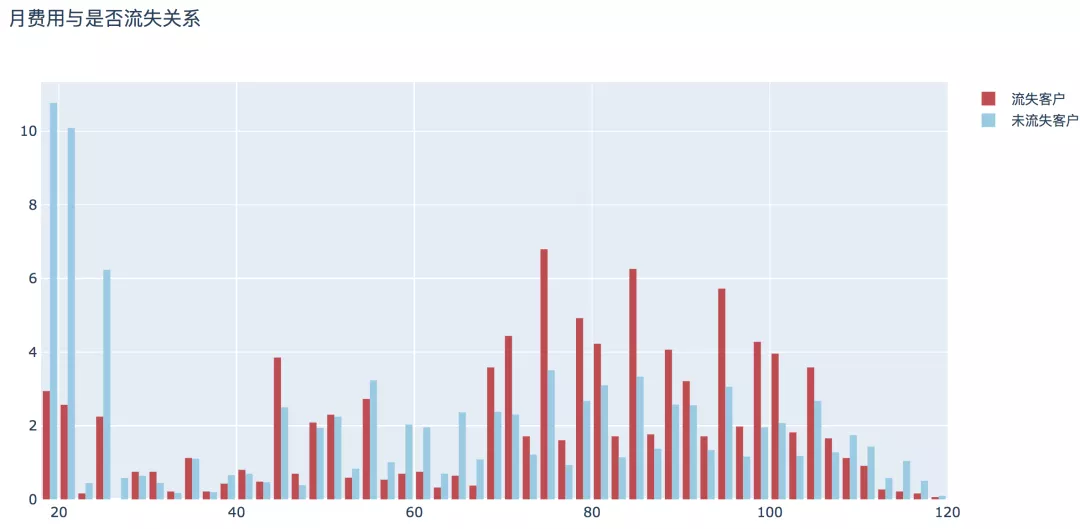
整體來(lái)看,隨著月費(fèi)用的增加,流失用戶的比例呈現(xiàn)高高低低的變化,月消費(fèi)80-100元的用戶相對(duì)較高。
- plot_histogram(input_col='MonthlyCharges', title_name='月費(fèi)用與是否流失關(guān)系')
8. 數(shù)值型屬性相關(guān)性
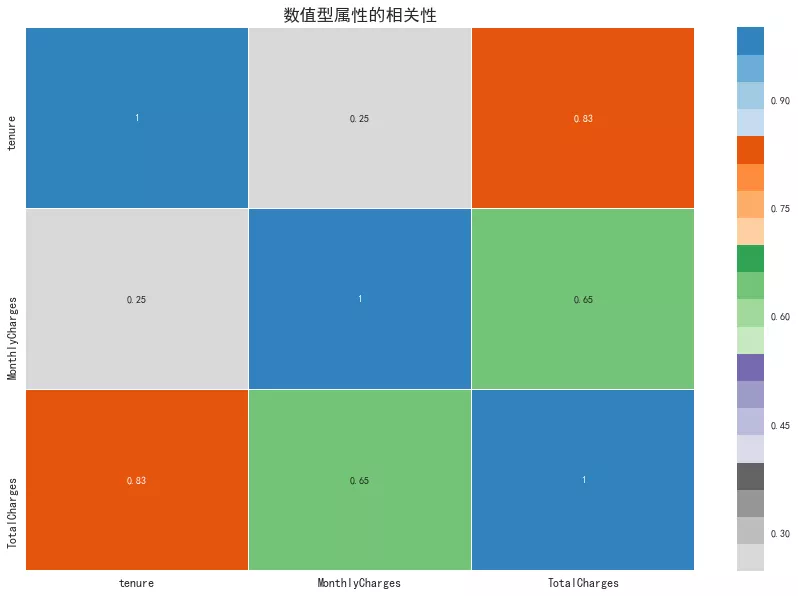
從相關(guān)性矩陣圖可以看出,用戶的往來(lái)期間和總費(fèi)用呈現(xiàn)高度相關(guān),往來(lái)期間越長(zhǎng),則總費(fèi)用越高。月消費(fèi)和總消費(fèi)呈現(xiàn)顯著相關(guān)。
- plt.figure(figsize=(15, 10))
- sns.heatmap(df.corr(), linewidths=0.1, cmap='tab20c_r', annot=True)
- plt.title('數(shù)值型屬性的相關(guān)性', fontdict={'fontsize': 'xx-large', 'fontweight':'heavy'})
- plt.xticks(fontsize=12)
- plt.yticks(fontsize=12)
- plt.show()
06、特征選擇
使用統(tǒng)計(jì)檢定方式進(jìn)行特征篩選。
- # 刪除tenure
- df = df.drop('tenure', axis=1)
- from feature_selection import Feature_select
- # 劃分X和y
- X = df.drop(['customerID', 'Churn'], axis=1)
- y = df['Churn']
- fs = Feature_select(num_method='anova', cate_method='kf', pos_label='Yes')
- x_sel = fs.fit_transform(X, y)
- 2020 09:30:02 INFO attr select success!
- After select attr: ['DeviceProtection', 'MultipleLines', 'OnlineSecurity',
- 'TechSupport', 'tenure_group', 'PaperlessBilling',
- 'InternetService', 'PaymentMethod', 'SeniorCitizen',
- 'MonthlyCharges', 'Dependents', 'Partner', 'Contract',
- 'StreamingTV', 'TotalCharges', 'StreamingMovies', 'OnlineBackup']
經(jīng)過(guò)特征篩選,gender和PhoneService字段被去掉。
07、建模前處理
在python中,為滿足建模需要,一般需要對(duì)數(shù)據(jù)做以下處理:
- 對(duì)于二分類變量,編碼為0和1;
- 對(duì)于多分類變量,進(jìn)行one_hot編碼;
- 對(duì)于數(shù)值型變量,部分模型如KNN、神經(jīng)網(wǎng)絡(luò)、Logistic需要進(jìn)行標(biāo)準(zhǔn)化處理。
- # 篩選變量
- select_features = x_sel.columns
- # 建模數(shù)據(jù)
- df_model = pd.concat([df['customerID'], df[select_features], df['Churn']], axis=1)
- Id_col = ['customerID']
- target_col = ['Churn']
- # 分類型
- cat_cols = df_model.nunique()[df_model.nunique() < 10].index.tolist()
- # 二分類屬性
- binary_cols = df_model.nunique()[df_model.nunique() == 2].index.tolist()
- # 多分類屬性
- multi_cols = [i for i in cat_cols if i not in binary_cols]
- # 數(shù)值型
- num_cols = [i for i in df_model.columns if i not in cat_cols + Id_col]
- # 二分類-標(biāo)簽編碼
- le = LabelEncoder()
- for i in binary_cols:
- df_model[i] = le.fit_transform(df_model[i])
- # 多分類-啞變量轉(zhuǎn)換
- df_model = pd.get_dummies(data=df_model, columns=multi_cols)
- df_model.head()
08、模型建立和評(píng)估
首先使用分層抽樣的方式將數(shù)據(jù)劃分訓(xùn)練集和測(cè)試集。
- # 重新劃分
- X = df_model.drop(['customerID', 'Churn'], axis=1)
- y = df_model['Churn']
- # 分層抽樣
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0, stratify=y)
- print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
- #修正索引
- for i in [X_train, X_test, y_train, y_test]:
- i.index = range(i.shape[0])
- (5625, 31) (1407, 31) (5625,) (1407,)
- # 保存標(biāo)準(zhǔn)化訓(xùn)練和測(cè)試數(shù)據(jù)
- st = StandardScaler()
- num_scaled_train = pd.DataFrame(st.fit_transform(X_train[num_cols]), columns=num_cols)
- num_scaled_test = pd.DataFrame(st.transform(X_test[num_cols]), columns=num_cols)
- X_train_sclaed = pd.concat([X_train.drop(num_cols, axis=1), num_scaled_train], axis=1)
- X_test_sclaed = pd.concat([X_test.drop(num_cols, axis=1), num_scaled_test], axis=1)
然后建立一系列基準(zhǔn)模型并比較效果。
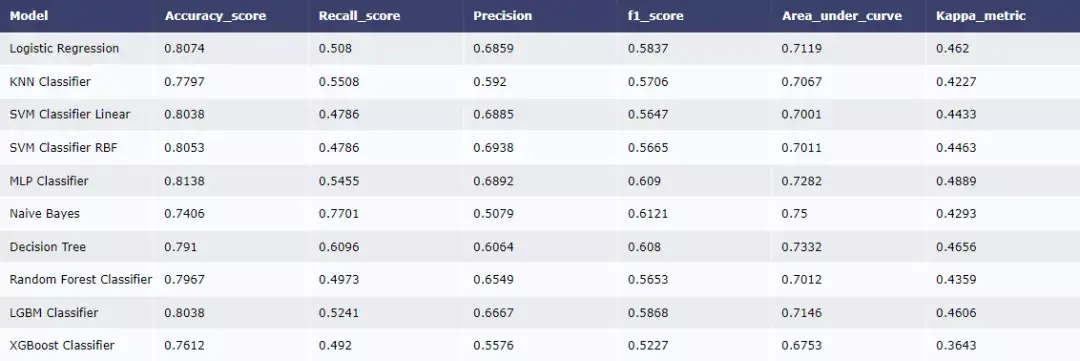
假如我們關(guān)注roc指標(biāo),從模型表現(xiàn)效果來(lái)看,Naive Bayes效果最好。我們也可以對(duì)模型進(jìn)行進(jìn)一步優(yōu)化,比如對(duì)決策樹(shù)參數(shù)進(jìn)行調(diào)優(yōu)。
- parameters = {'splitter': ('best','random'),
- 'criterion': ("gini","entropy"),
- "max_depth": [*range(3, 20)],
- }
- clf = DecisionTreeClassifier(random_state=25)
- GS = GridSearchCV(clf, parameters, scoring='f1', cv=10)
- GS.fit(X_train, y_train)
- print(GS.best_params_)
- print(GS.best_score_)
- {'criterion': 'entropy', 'max_depth': 5, 'splitter': 'best'}
- 0.585900839405024
- clf = GS.best_estimator_
- test_pred = clf.predict(X_test)
- print('測(cè)試集:\n', classification_report(y_test, test_pred))
- 測(cè)試集:
- precision recall f1-score support
- 0 0.86 0.86 0.86 1033
- 1 0.61 0.61 0.61 374
- accuracy 0.79 1407
- macro avg 0.73 0.73 0.73 1407
- weighted avg 0.79 0.79 0.79 1407
將這棵樹(shù)繪制出來(lái)。
- import graphviz
- dot_data = tree.export_graphviz(decision_tree=clf, max_depth=3,
- out_file=None,
- feature_names=X_train.columns,
- class_names=['not_churn', 'churn'],
- filled=True,
- rounded=True
- )
- graph = graphviz.Source(dot_data)
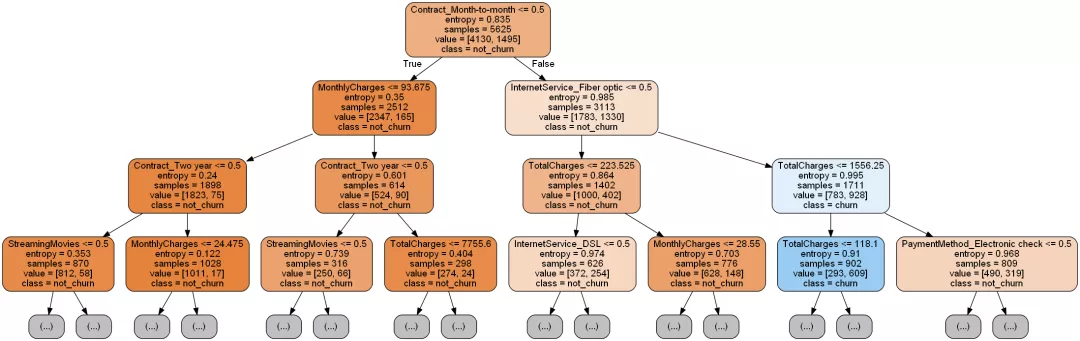
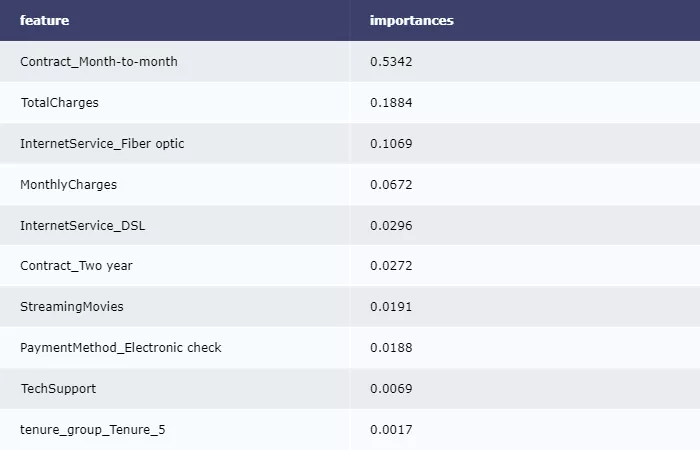
輸出決策樹(shù)屬性重要性排序:
- imp = pd.DataFrame(zip(X_train.columns, clf.feature_importances_))
- imp.columns = ['feature', 'importances']
- imp = imp.sort_values('importances', ascending=False)
- imp = imp[imp['importances'] != 0]
- table = ff.create_table(np.round(imp, 4))
- py.offline.iplot(table)
后續(xù)優(yōu)化方向:
- 數(shù)據(jù):分類技術(shù)應(yīng)用在目標(biāo)類別分布越均勻的數(shù)據(jù)集時(shí),其所建立之分類器通常會(huì)有比較好的分類效能。針對(duì)數(shù)據(jù)在目標(biāo)字段上分布不平衡,可采用過(guò)采樣和欠采樣來(lái)處理類別不平衡問(wèn)題;
- 屬性:進(jìn)一步屬性篩選方法和屬性組合;
- 算法:參數(shù)調(diào)優(yōu);調(diào)整預(yù)測(cè)門(mén)檻值來(lái)增加預(yù)測(cè)效能。