教你用Python實現AutoML
譯文【51CTO.com快譯】我們已經知道,機器學習是一種自動解決復雜問題的方法。但機器學習本身可以自動化嗎?這是我們在本文中將探討的內容。讀完這篇文章時,你將會知道這個問題的答案,并且會掌握實現 AutoML 的方法。
1. Automated Machine Learning(AutoML)
在應用機器學習模型時,我們通常會進行數據預處理,特征工程,特征提取和特征選擇。在此之后,我們將選擇***算法并調整我們的參數以獲得***結果。AutoML 是一系列用于自動化這些過程的概念和技術。
1.1. AutoML 的優勢
將機器學習模型應用于實際問題通常需要很多計算機科學相關技能、領域專業知識和數學專業知識。想找到擁有所有這些技能的專家并不總是一件容易的事情。
AutoML 還可以減少人類設計機器學習模型時出現的偏差和錯誤。企業可以通過在其數據管道中應用 AutoML 來降低雇傭許多專家的成本。AutoML 還可以減少開發和測試機器學習模型所需的時間。
1.2. AutoML 的缺點
AutoML 在機器學習領域是一個相當新的概念。因此,在應用一些當前的 AutoML 解決方案時要謹慎行事,這 是因為其中一些技術仍處于開發階段。
另一個主要的挑戰是運行 AutoML 模型所需的時間成本很高。這實際上取決于我們機器的計算能力。我們很 快就會看到,一些 AutoML 解決方案在我們的本地機器上也可以很好地運行,但有些解決方案還需要更多的加速優化,例如 Google Colab。
2. AutoML 的概念
就 AutoML 而言,需要了解兩個主要概念:神經架構搜索(Neural Architecture Search)和遷移學習(Transfer Learning)。
2.1. 神經架構搜索(Neural Architecture Search)
神經架構搜索是自動化設計神經網絡的過程。通常,在這些網絡的設計中會使用強化學習或進化算法。在強化 學習中,模型因低準確率而受到懲罰,并因高準確率而獲得獎勵。使用這種技術,模型將始終努力獲得更高的 準確率。
目前已經有一些研究神經架構搜索的論文,例如用于可伸縮圖像識別的學習可遷移架構(LearningTransferable Architectures),高效神經架構搜索(Efficient Neural Architecture Search,ENAS)和用于圖像分類器架構搜 索的正則進化(Regularized Evolution)模型。
2.2. 遷移學習
顧名思義,遷移學習是一種技術,使得預先訓練的模型可以將它學習過的知識遷移應用在新的但相似的數據 集上。這使我們能夠用更少的計算時間和計算資源去獲得比較高的準確率。神經架構搜索適用于需要設計新 模型架構的問題,而遷移學習最適用于數據集類似于預訓練模型中使用的數據集的問題。
3. AutoML 解決方案
現在讓我們來看看一些可用的 AutoML 的解決方案吧。
3.1. Auto-Keras
根據官方提供的資料:
Auto-Keras 是一個用于自動化機器學習(AutoML)的開源軟件庫。 它由 Texas A & M 大學的 DATA 實驗室和社區貢獻者開發。 AutoML 的最終目標是為具有有限數據科學或機器學習背景的領域專家提供易于上手的深度學習工具。 Auto-Keras 提供自動搜索深度學習模型架構和超參數的功能。
Auto-Keras 可以用 pip 命令安裝:
- pip install auto-keras
Auto-Keras 在最終版發布之前仍在進行***的測試。官方網站警告說,對于因使用該網站上的庫而導致的任何損失,他們不承擔任何責任。
該軟件包基于 Keras 深度學習軟件包。
3.2. Auto-Sklearn
Auto-Sklearn 是一款基于 Scikit-learn 的 AutoML 軟件包。它是 Scikit-learn estimator 的替代品。它也可以通過一個簡單的 pip 命令安裝:
- pip install auto-sklearn
在 Ubuntu 系統下,需要 C++ 11 構建環境和 SWIG 配置環境才可以運行 Auto-Sklearn。
sudo apt-get install build-essential swig
通過 Anaconda 的安裝方式如下:
- conda install gxx_linux-64 gcc_linux-64 swig
目前還無法在 Windows 上運行 Auto-Sklearn。但是,可以嘗試一些黑科技,例如使用 docker 鏡像或通過虛擬機運行。
3.3. The Tree-Based Pipeline Optimization Tool(TPOT)
根據官方網站資料:
TPOT 的目標是通過將管道的靈活表達樹 (Flexible Expression Tree) 表示與諸如遺傳編程 (Genetic Programming) 的隨機搜索算法相結合來自動化機器學習管道的構建。 TPOT 使用基于 Python 的 scikit-learn 庫作為其機器學習基礎庫。
該軟件是開源的,可在GitHub上獲得。
3.4. 谷歌的 AutoML
官網對它介紹如下:
Cloud AutoML 是一套機器學習產品,通過利用 Google ***進的遷移學習和神經架構搜索技術,使具有有 限機器學習專業知識的開發人員能夠根據業務需求訓練高質量模型。
谷歌的 AutoML 解決方案不是開源的。它的價格可以在這里查看。
3.5. H2O
H2O 是一個開源的分布式內存機器學習平臺。它有 R 和 Python 兩種版本。該軟件包支持眾多的統計和機器 學習算法。
4. 將 AutoML 應用于實際問題
現在讓我們看看應該如何使用 Auto-Keras 和 Auto-Sklearn 來解決一個真正的問題吧。
4.1. Auto-Keras 實現
我強烈建議在 Google Colabunless 上運行以下代碼示例,除非您有一臺具有非常高計算能力的計算機。我也 建議在 Google Colab 上開啟 GPU runtime。 這里的***步是在 Colab 上安裝 Auto-Keras。
- !pip install autokeras
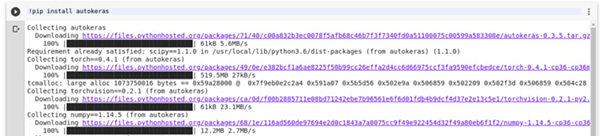
我們將在 MNIST 數據集上運行圖像分類任務。***步是導入該數據集和圖像分類器。數據集從 Keras 導入, 而圖像分類器從 Auto-Keras 導入。由于我們正在構建一個基于預訓練模型識別手寫數字的模型,因此我們將 其歸類為監督學習問題。然后,我們在未遇到的數字圖像上測試模型的準確率。
- from keras.datasets
- import mnist
- from autokeras.image.image_supervised
- import ImageClassifer
在此示例中,圖像和標簽已被格式化為 numpy 數組。下一步是將剛剛加載的數據分成訓練集和測試集,如下所示:
- (x_train, x_test), (x_test, y_test) = mnist.load_data()
- x_train = x_train.reshape(x_train.shape + (1,))
- x_test = x_test.reshape(x_test.shape + (1,))
將數據分成訓練集和測試集后,下一步就是擬合圖像分類器。
- clf = ImageClassifer(verbose=True)
- clf.fit(x_train, y_train, time_limit=12 * 60 * 60)
- clf.final_fit(x_train, y_train, x_test, y_test, retrain=True)
- y = clf.evaluate(x_test, y_test)
- print(y)
1. 將 verbose 指定為 True 意味著搜索過程將打印在屏幕上供我們查看。 2. 在 fit 方法中,time_limit 參數是指以秒為單位的搜索時間限制。 3. final_fit 是模型找到***模型架構后進行的***一次訓練。將 retrain 參數指定為 True 意味著將重新初 始化模型的權重。 4. 在評估模型在測試集上的效果后,print(y) 將顯示模型準確率。
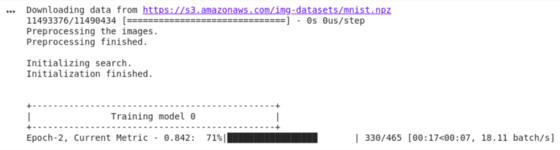
這就是我們使用 Auto-Keras 對圖像進行分類所需的全部步驟。只需要幾行代碼,Auto-Keras 就可以為我們 完成所有繁重的工作。
4.2. Auto-Sklearn 實現
Auto-Sklearn 的實現與上面的 Auto-Keras 實現非常相似。我們在一個數字數據集上做類似的分類任務。首先, 我們需要導入一些庫:
- import autosklearn.classification
- import sklearn.model_selection import sklearn.datasets import sklearn.metrics
像往常一樣,我們加載數據集并將其劃分為訓練集和測試集。然后我們從 autosklearn.classification 導 入 AutoSklearnClassifier。完成此操作后,我們讓分類器擬合數據集,然后進行預測并檢查模型準確率。這 就是所有你需要做的事情。
- X, y = sklearn.datasets.load_digits(return_X_y=True)
- X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X, y, random_state=1)
- automl = autosklearn.classification.AutoSklearnClassifier()
- automl.fit(X_train, y_train)
- y_hat = automl.predict(X_test)
- print("Score of accuracy", sklearn.metrics.accuracy_score(y_test, y_hat))
5. What’s Next?
更多的自動化機器學習包仍在活躍地開發中。我們希望 2019 年該領域會有更多的進展。大家可以通過官方文 檔網站密切關注這些軟件包的進展情況。當然大家也可以在 GitHub 上通過 pull request 來為這些包做出貢獻。
有關 Auto-Keras 和 Auto-Sklearncan 的更多信息和示例,請訪問其官方網站。
【51CTO譯稿,合作站點轉載請注明原文譯者和出處為51CTO.com】