













一口氣搞懂MySQL索引所有知識(shí)點(diǎn)
前言
國(guó)慶期間看了數(shù)據(jù)庫(kù)的很多資料和書(shū)籍,這點(diǎn)我在總結(jié)的數(shù)據(jù)庫(kù)文章里面也提過(guò)了,然后我發(fā)現(xiàn)我對(duì)索引的介紹不全,所以整理了一下自己的筆記,決定來(lái)個(gè)索引完整版,老規(guī)矩可能還是沒(méi)我正常文章風(fēng)格那么跳,但是干貨一定也能讓你有所收獲。
索引介紹
索引是什么
- 官方介紹索引是幫助MySQL高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)。更通俗的說(shuō),數(shù)據(jù)庫(kù)索引好比是一本書(shū)前面的目錄,能加快數(shù)據(jù)庫(kù)的查詢速度。
- 一般來(lái)說(shuō)索引本身也很大,不可能全部存儲(chǔ)在內(nèi)存中,因此索引往往是存儲(chǔ)在磁盤上的文件中的(可能存儲(chǔ)在單獨(dú)的索引文件中,也可能和數(shù)據(jù)一起存儲(chǔ)在數(shù)據(jù)文件中)。
- 我們通常所說(shuō)的索引,包括聚集索引、覆蓋索引、組合索引、前綴索引、唯一索引等,沒(méi)有特別說(shuō)明,默認(rèn)都是使用B+樹(shù)結(jié)構(gòu)組織(多路搜索樹(shù),并不一定是二叉的)的索引。
索引的優(yōu)勢(shì)和劣勢(shì)
優(yōu)勢(shì):
- 可以提高數(shù)據(jù)檢索的效率,降低數(shù)據(jù)庫(kù)的IO成本,類似于書(shū)的目錄。
- 通過(guò)索引列對(duì)數(shù)據(jù)進(jìn)行排序,降低數(shù)據(jù)排序的成本,降低了CPU的消耗。
- 被索引的列會(huì)自動(dòng)進(jìn)行排序,包括【單列索引】和【組合索引】,只是組合索引的排序要復(fù)雜一些。
- 如果按照索引列的順序進(jìn)行排序,對(duì)應(yīng)order by語(yǔ)句來(lái)說(shuō),效率就會(huì)提高很多。
劣勢(shì):
- 索引會(huì)占據(jù)磁盤空間
- 索引雖然會(huì)提高查詢效率,但是會(huì)降低更新表的效率。比如每次對(duì)表進(jìn)行增刪改操作,MySQL不僅要保存數(shù)據(jù),還有保存或者更新對(duì)應(yīng)的索引文件。
索引類型
主鍵索引
索引列中的值必須是唯一的,不允許有空值。
普通索引
MySQL中基本索引類型,沒(méi)有什么限制,允許在定義索引的列中插入重復(fù)值和空值。
唯一索引
索引列中的值必須是唯一的,但是允許為空值。
全文索引
只能在文本類型CHAR,VARCHAR,TEXT類型字段上創(chuàng)建全文索引。字段長(zhǎng)度比較大時(shí),如果創(chuàng)建普通索引,在進(jìn)行l(wèi)ike模糊查詢時(shí)效率比較低,這時(shí)可以創(chuàng)建全文索引。MyISAM和InnoDB中都可以使用全文索引。
空間索引
MySQL在5.7之后的版本支持了空間索引,而且支持OpenGIS幾何數(shù)據(jù)模型。MySQL在空間索引這方面遵循OpenGIS幾何數(shù)據(jù)模型規(guī)則。
前綴索引
在文本類型如CHAR,VARCHAR,TEXT類列上創(chuàng)建索引時(shí),可以指定索引列的長(zhǎng)度,但是數(shù)值類型不能指定。
其他(按照索引列數(shù)量分類)
單列索引
組合索引
組合索引的使用,需要遵循最左前綴匹配原則(最左匹配原則)。一般情況下在條件允許的情況下使用組合索引替代多個(gè)單列索引使用。
索引的數(shù)據(jù)結(jié)構(gòu)
Hash表
Hash表,在Java中的HashMap,TreeMap就是Hash表結(jié)構(gòu),以鍵值對(duì)的方式存儲(chǔ)數(shù)據(jù)。我們使用Hash表存儲(chǔ)表數(shù)據(jù)Key可以存儲(chǔ)索引列,Value可以存儲(chǔ)行記錄或者行磁盤地址。Hash表在等值查詢時(shí)效率很高,時(shí)間復(fù)雜度為O(1);但是不支持范圍快速查找,范圍查找時(shí)還是只能通過(guò)掃描全表方式。
顯然這種并不適合作為經(jīng)常需要查找和范圍查找的數(shù)據(jù)庫(kù)索引使用。
二叉查找樹(shù)
二叉樹(shù),我想大家都會(huì)在心里有個(gè)圖。
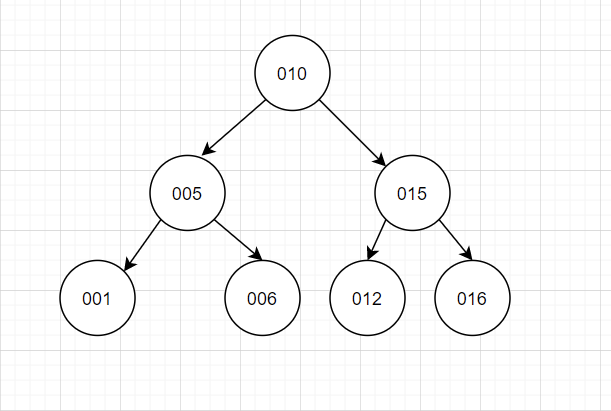
二叉樹(shù)特點(diǎn):每個(gè)節(jié)點(diǎn)最多有2個(gè)分叉,左子樹(shù)和右子樹(shù)數(shù)據(jù)順序左小右大。
這個(gè)特點(diǎn)就是為了保證每次查找都可以這折半而減少IO次數(shù),但是二叉樹(shù)就很考驗(yàn)第一個(gè)根節(jié)點(diǎn)的取值,因?yàn)楹苋菀自谶@個(gè)特點(diǎn)下出現(xiàn)我們并發(fā)想發(fā)生的情況“樹(shù)不分叉了”,這就很難受很不穩(wěn)定。
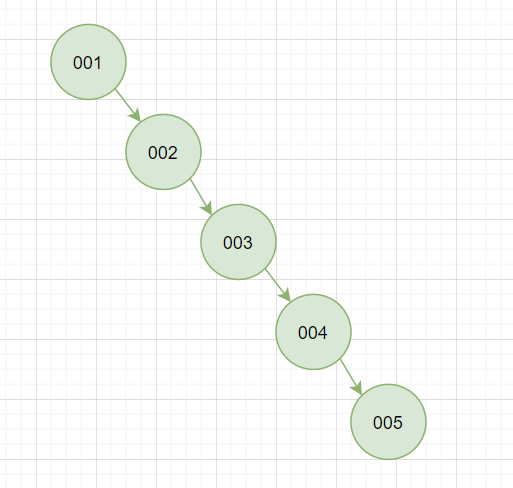
顯然這種情況不穩(wěn)定的我們?cè)龠x擇設(shè)計(jì)上必然會(huì)避免這種情況的
平衡二叉樹(shù)
平衡二叉樹(shù)是采用二分法思維,平衡二叉查找樹(shù)除了具備二叉樹(shù)的特點(diǎn),最主要的特征是樹(shù)的左右兩個(gè)子樹(shù)的層級(jí)最多相差1。在插入刪除數(shù)據(jù)時(shí)通過(guò)左旋/右旋操作保持二叉樹(shù)的平衡,不會(huì)出現(xiàn)左子樹(shù)很高、右子樹(shù)很矮的情況。
使用平衡二叉查找樹(shù)查詢的性能接近于二分查找法,時(shí)間復(fù)雜度是 O(log2n)。查詢id=6,只需要兩次IO。
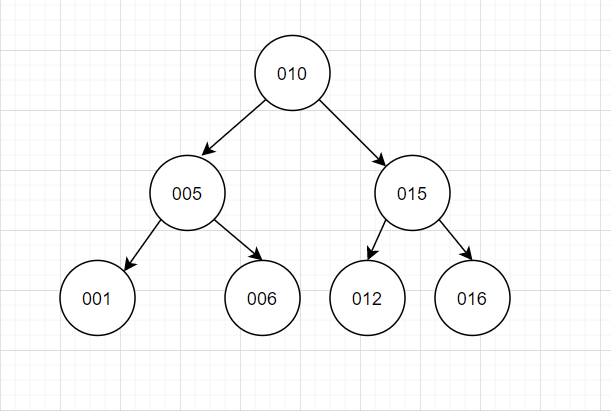
就這個(gè)特點(diǎn)來(lái)看,可能各位會(huì)覺(jué)得這就很好,可以達(dá)到二叉樹(shù)的理想的情況了。然而依然存在一些問(wèn)題:
- 時(shí)間復(fù)雜度和樹(shù)高相關(guān)。樹(shù)有多高就需要檢索多少次,每個(gè)節(jié)點(diǎn)的讀取,都對(duì)應(yīng)一次磁盤 IO 操作。樹(shù)的高度就等于每次查詢數(shù)據(jù)時(shí)磁盤 IO 操作的次數(shù)。磁盤每次尋道時(shí)間為10ms,在表數(shù)據(jù)量大時(shí),查詢性能就會(huì)很差。(1百萬(wàn)的數(shù)據(jù)量,log2n約等于20次磁盤IO,時(shí)間20*10=0.2s)
- 平衡二叉樹(shù)不支持范圍查詢快速查找,范圍查詢時(shí)需要從根節(jié)點(diǎn)多次遍歷,查詢效率不高。
B樹(shù):改造二叉樹(shù)
MySQL的數(shù)據(jù)是存儲(chǔ)在磁盤文件中的,查詢處理數(shù)據(jù)時(shí),需要先把磁盤中的數(shù)據(jù)加載到內(nèi)存中,磁盤IO 操作非常耗時(shí),所以我們優(yōu)化的重點(diǎn)就是盡量減少磁盤 IO 操作。訪問(wèn)二叉樹(shù)的每個(gè)節(jié)點(diǎn)就會(huì)發(fā)生一次IO,如果想要減少磁盤IO操作,就需要盡量降低樹(shù)的高度。那如何降低樹(shù)的高度呢?
假如key為bigint=8字節(jié),每個(gè)節(jié)點(diǎn)有兩個(gè)指針,每個(gè)指針為4個(gè)字節(jié),一個(gè)節(jié)點(diǎn)占用的空間16個(gè)字節(jié)(8+4*2=16)。
因?yàn)樵贛ySQL的InnoDB存儲(chǔ)引擎一次IO會(huì)讀取的一頁(yè)(默認(rèn)一頁(yè)16K)的數(shù)據(jù)量,而二叉樹(shù)一次IO有效數(shù)據(jù)量只有16字節(jié),空間利用率極低。為了最大化利用一次IO空間,一個(gè)簡(jiǎn)單的想法是在每個(gè)節(jié)點(diǎn)存儲(chǔ)多個(gè)元素,在每個(gè)節(jié)點(diǎn)盡可能多的存儲(chǔ)數(shù)據(jù)。每個(gè)節(jié)點(diǎn)可以存儲(chǔ)1000個(gè)索引(16k/16=1000),這樣就將二叉樹(shù)改造成了多叉樹(shù),通過(guò)增加樹(shù)的叉樹(shù),將樹(shù)從高瘦變?yōu)榘帧?gòu)建1百萬(wàn)條數(shù)據(jù),樹(shù)的高度只需要2層就可以(1000*1000=1百萬(wàn)),也就是說(shuō)只需要2次磁盤IO就可以查詢到數(shù)據(jù)。磁盤IO次數(shù)變少了,查詢數(shù)據(jù)的效率也就提高了。
這種數(shù)據(jù)結(jié)構(gòu)我們稱為B樹(shù),B樹(shù)是一種多叉平衡查找樹(shù),如下圖主要特點(diǎn):
- B樹(shù)的節(jié)點(diǎn)中存儲(chǔ)著多個(gè)元素,每個(gè)內(nèi)節(jié)點(diǎn)有多個(gè)分叉。
- 節(jié)點(diǎn)中的元素包含鍵值和數(shù)據(jù),節(jié)點(diǎn)中的鍵值從大到小排列。也就是說(shuō),在所有的節(jié)點(diǎn)都儲(chǔ)存數(shù)據(jù)。
- 父節(jié)點(diǎn)當(dāng)中的元素不會(huì)出現(xiàn)在子節(jié)點(diǎn)中。
- 所有的葉子結(jié)點(diǎn)都位于同一層,葉節(jié)點(diǎn)具有相同的深度,葉節(jié)點(diǎn)之間沒(méi)有指針連接。
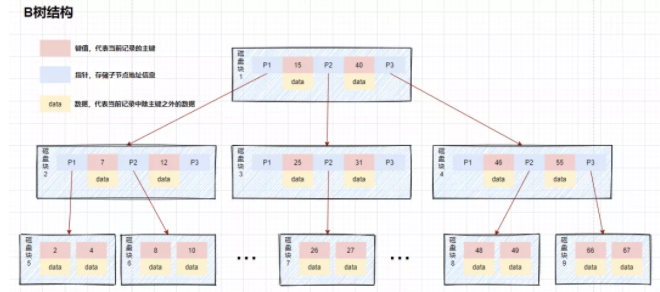
舉個(gè)例子,在b樹(shù)中查詢數(shù)據(jù)的情況:
假如我們查詢值等于10的數(shù)據(jù)。查詢路徑磁盤塊1->磁盤塊2->磁盤塊5。
第一次磁盤IO:將磁盤塊1加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,10<15,走左路,到磁盤尋址磁盤塊2。
第二次磁盤IO:將磁盤塊2加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,7<10,到磁盤中尋址定位到磁盤塊5。
第三次磁盤IO:將磁盤塊5加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,10=10,找到10,取出data,如果data存儲(chǔ)的行記錄,取出data,查詢結(jié)束。如果存儲(chǔ)的是磁盤地址,還需要根據(jù)磁盤地址到磁盤中取出數(shù)據(jù),查詢終止。
相比二叉平衡查找樹(shù),在整個(gè)查找過(guò)程中,雖然數(shù)據(jù)的比較次數(shù)并沒(méi)有明顯減少,但是磁盤IO次數(shù)會(huì)大大減少。同時(shí),由于我們的比較是在內(nèi)存中進(jìn)行的,比較的耗時(shí)可以忽略不計(jì)。B樹(shù)的高度一般2至3層就能滿足大部分的應(yīng)用場(chǎng)景,所以使用B樹(shù)構(gòu)建索引可以很好的提升查詢的效率。
過(guò)程如圖:
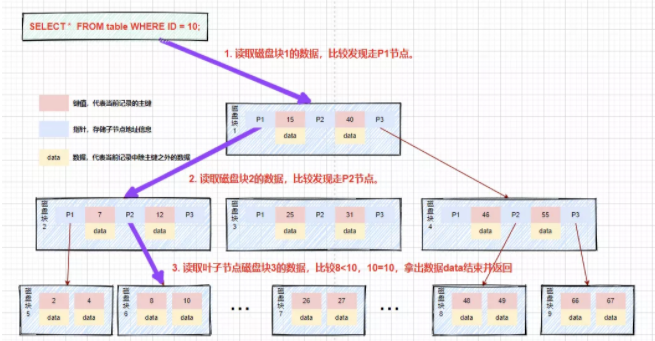
B樹(shù)索引查詢過(guò)程
看到這里一定覺(jué)得B樹(shù)就很理想了,但是前輩們會(huì)告訴你依然存在可以優(yōu)化的地方:
- B樹(shù)不支持范圍查詢的快速查找,你想想這么一個(gè)情況如果我們想要查找10和35之間的數(shù)據(jù),查找到15之后,需要回到根節(jié)點(diǎn)重新遍歷查找,需要從根節(jié)點(diǎn)進(jìn)行多次遍歷,查詢效率有待提高。
- 如果data存儲(chǔ)的是行記錄,行的大小隨著列數(shù)的增多,所占空間會(huì)變大。這時(shí),一個(gè)頁(yè)中可存儲(chǔ)的數(shù)據(jù)量就會(huì)變少,樹(shù)相應(yīng)就會(huì)變高,磁盤IO次數(shù)就會(huì)變大。
B+樹(shù):改造B樹(shù)
B+樹(shù),作為B樹(shù)的升級(jí)版,在B樹(shù)基礎(chǔ)上,MySQL在B樹(shù)的基礎(chǔ)上繼續(xù)改造,使用B+樹(shù)構(gòu)建索引。B+樹(shù)和B樹(shù)最主要的區(qū)別在于非葉子節(jié)點(diǎn)是否存儲(chǔ)數(shù)據(jù)的問(wèn)題
- B樹(shù):非葉子節(jié)點(diǎn)和葉子節(jié)點(diǎn)都會(huì)存儲(chǔ)數(shù)據(jù)。
- B+樹(shù):只有葉子節(jié)點(diǎn)才會(huì)存儲(chǔ)數(shù)據(jù),非葉子節(jié)點(diǎn)至存儲(chǔ)鍵值。葉子節(jié)點(diǎn)之間使用雙向指針連接,最底層的葉子節(jié)點(diǎn)形成了一個(gè)雙向有序鏈表。
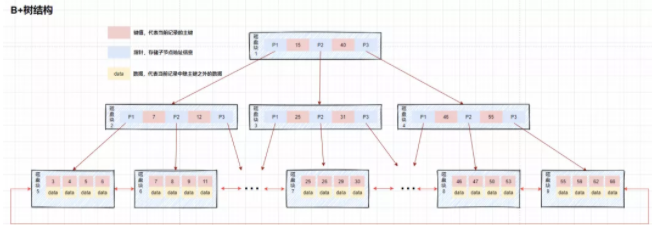
B+樹(shù)數(shù)據(jù)結(jié)構(gòu)
B+樹(shù)的最底層葉子節(jié)點(diǎn)包含了所有的索引項(xiàng)。從圖上可以看到,B+樹(shù)在查找數(shù)據(jù)的時(shí)候,由于數(shù)據(jù)都存放在最底層的葉子節(jié)點(diǎn)上,所以每次查找都需要檢索到葉子節(jié)點(diǎn)才能查詢到數(shù)據(jù)。
所以在需要查詢數(shù)據(jù)的情況下每次的磁盤的IO跟樹(shù)高有直接的關(guān)系,但是從另一方面來(lái)說(shuō),由于數(shù)據(jù)都被放到了葉子節(jié)點(diǎn),放索引的磁盤塊鎖存放的索引數(shù)量是會(huì)跟這增加的,相對(duì)于B樹(shù)來(lái)說(shuō),B+樹(shù)的樹(shù)高理論上情況下是比B樹(shù)要矮的。
也存在索引覆蓋查詢的情況,在索引中數(shù)據(jù)滿足了當(dāng)前查詢語(yǔ)句所需要的全部數(shù)據(jù),此時(shí)只需要找到索引即可立刻返回,不需要檢索到最底層的葉子節(jié)點(diǎn)。
舉個(gè)例子:等值查詢
假如我們查詢值等于9的數(shù)據(jù)。查詢路徑磁盤塊1->磁盤塊2->磁盤塊6。
第一次磁盤IO:將磁盤塊1加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,9<15,走左路,到磁盤尋址磁盤塊2。
第二次磁盤IO:將磁盤塊2加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,7<9<12,到磁盤中尋址定位到磁盤塊6。
第三次磁盤IO:將磁盤塊6加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,在第三個(gè)索引中找到9,取出data,如果data存儲(chǔ)的行記錄,取出data,查詢結(jié)束。如果存儲(chǔ)的是磁盤地址,還需要根據(jù)磁盤地址到磁盤中取出數(shù)據(jù),查詢終止。(這里需要區(qū)分的是在InnoDB中Data存儲(chǔ)的為行數(shù)據(jù),而MyIsam中存儲(chǔ)的是磁盤地址。)
過(guò)程如圖:
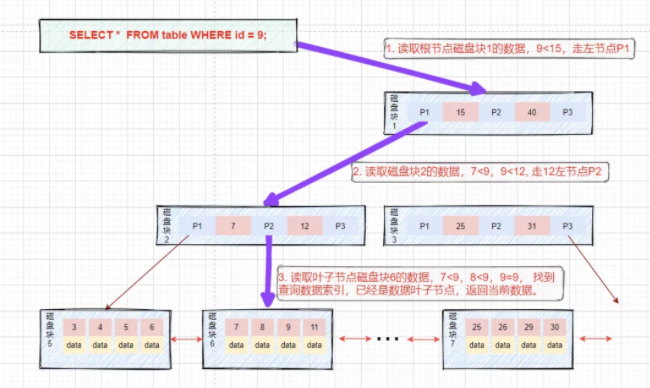
范圍查詢:
假如我們想要查找9和26之間的數(shù)據(jù)。查找路徑是磁盤塊1->磁盤塊2->磁盤塊6->磁盤塊7。
首先查找值等于9的數(shù)據(jù),將值等于9的數(shù)據(jù)緩存到結(jié)果集。這一步和前面等值查詢流程一樣,發(fā)生了三次磁盤IO。
查找到15之后,底層的葉子節(jié)點(diǎn)是一個(gè)有序列表,我們從磁盤塊6,鍵值9開(kāi)始向后遍歷篩選所有符合篩選條件的數(shù)據(jù)。
第四次磁盤IO:根據(jù)磁盤6后繼指針到磁盤中尋址定位到磁盤塊7,將磁盤7加載到內(nèi)存中,在內(nèi)存中從頭遍歷比較,9<25<26,9<26<=26,將data緩存到結(jié)果集。
主鍵具備唯一性(后面不會(huì)有<=26的數(shù)據(jù)),不需再向后查找,查詢終止。將結(jié)果集返回給用戶。
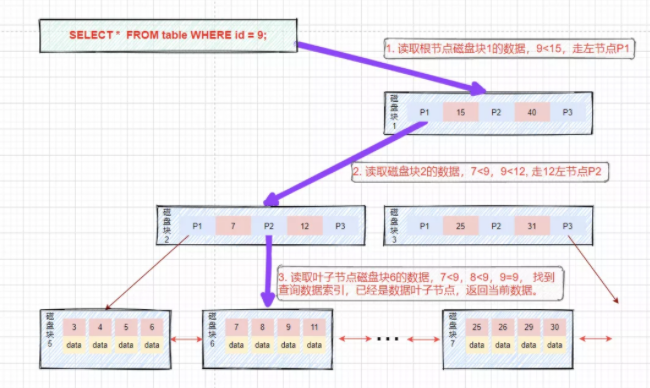
可以看到B+樹(shù)可以保證等值和范圍查詢的快速查找,MySQL的索引就采用了B+樹(shù)的數(shù)據(jù)結(jié)構(gòu)。
Mysql的索引實(shí)現(xiàn)
介紹完了索引數(shù)據(jù)結(jié)構(gòu),那肯定是要帶入到Mysql里面看看真實(shí)的使用場(chǎng)景的,所以這里分析Mysql的兩種存儲(chǔ)引擎的索引實(shí)現(xiàn):MyISAM索引和InnoDB索引
MyIsam索引
以一個(gè)簡(jiǎn)單的user表為例。user表存在兩個(gè)索引,id列為主鍵索引,age列為普通索引
- CREATE TABLE `user`
- (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `username` varchar(20) DEFAULT NULL,
- `age` int(11) DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE,
- KEY `idx_age` (`age`) USING BTREE
- ) ENGINE = MyISAM
- AUTO_INCREMENT = 1
- DEFAULT CHARSET = utf8;
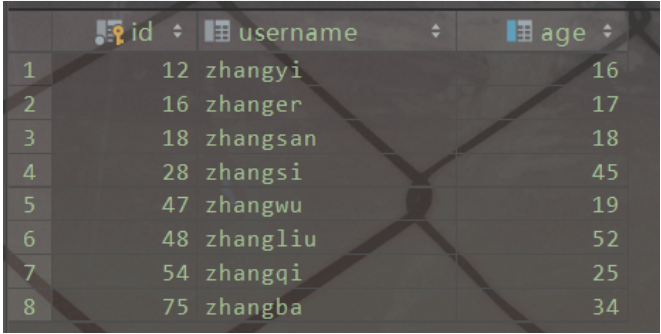
MyIsam_user查詢數(shù)據(jù)
MyISAM的數(shù)據(jù)文件和索引文件是分開(kāi)存儲(chǔ)的。MyISAM使用B+樹(shù)構(gòu)建索引樹(shù)時(shí),葉子節(jié)點(diǎn)中存儲(chǔ)的鍵值為索引列的值,數(shù)據(jù)為索引所在行的磁盤地址。
主鍵索引
MyIsam主鍵索引
表user的索引存儲(chǔ)在索引文件user.MYI中,數(shù)據(jù)文件存儲(chǔ)在數(shù)據(jù)文件 user.MYD中。
簡(jiǎn)單分析下查詢時(shí)的磁盤IO情況:
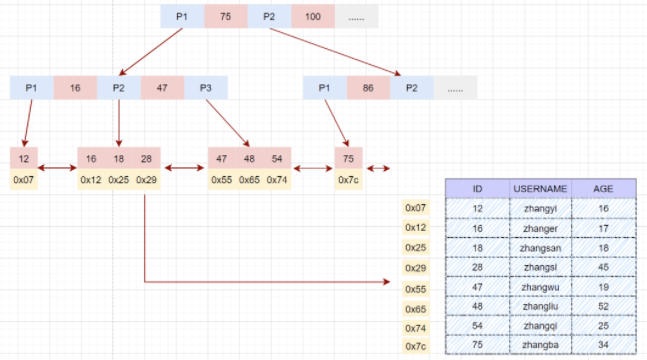
根據(jù)主鍵等值查詢數(shù)據(jù):
- select * from user where id = 28;
- 先在主鍵樹(shù)中從根節(jié)點(diǎn)開(kāi)始檢索,將根節(jié)點(diǎn)加載到內(nèi)存,比較28<75,走左路。(1次磁盤IO)
- 將左子樹(shù)節(jié)點(diǎn)加載到內(nèi)存中,比較16<28<47,向下檢索。(1次磁盤IO)
- 檢索到葉節(jié)點(diǎn),將節(jié)點(diǎn)加載到內(nèi)存中遍歷,比較16<28,18<28,28=28。查找到值等于30的索引項(xiàng)。(1次磁盤IO)
- 從索引項(xiàng)中獲取磁盤地址,然后到數(shù)據(jù)文件user.MYD中獲取對(duì)應(yīng)整行記錄。(1次磁盤IO)
- 將記錄返給客戶端。
磁盤IO次數(shù):3次索引檢索+記錄數(shù)據(jù)檢索。
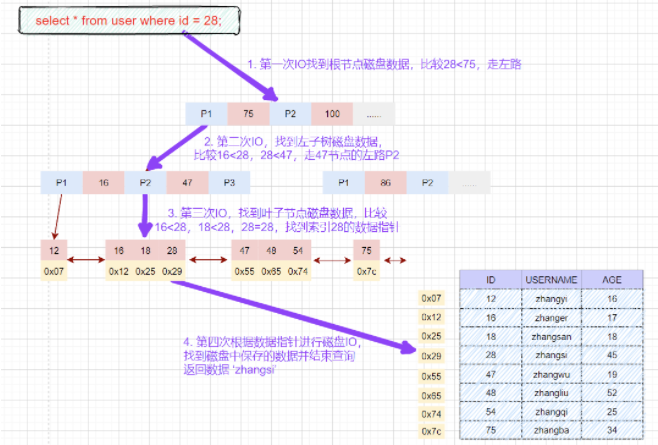
根據(jù)主鍵范圍查詢數(shù)據(jù):
- select * from user where id between 28 and 47;
1.先在主鍵樹(shù)中從根節(jié)點(diǎn)開(kāi)始檢索,將根節(jié)點(diǎn)加載到內(nèi)存,比較28<75,走左路。(1次磁盤IO)
2.將左子樹(shù)節(jié)點(diǎn)加載到內(nèi)存中,比較16<28<47,向下檢索。(1次磁盤IO)
3.檢索到葉節(jié)點(diǎn),將節(jié)點(diǎn)加載到內(nèi)存中遍歷比較16<28,18<28,28=28<47。查找到值等于28的索引項(xiàng)。
根據(jù)磁盤地址從數(shù)據(jù)文件中獲取行記錄緩存到結(jié)果集中。(1次磁盤IO)
我們的查詢語(yǔ)句時(shí)范圍查找,需要向后遍歷底層葉子鏈表,直至到達(dá)最后一個(gè)不滿足篩選條件。
4.向后遍歷底層葉子鏈表,將下一個(gè)節(jié)點(diǎn)加載到內(nèi)存中,遍歷比較,28<47=47,根據(jù)磁盤地址從數(shù)據(jù)文件中獲取行記錄緩存到結(jié)果集中。(1次磁盤IO)
5.最后得到兩條符合篩選條件,將查詢結(jié)果集返給客戶端。
磁盤IO次數(shù):4次索引檢索+記錄數(shù)據(jù)檢索。
備注:以上分析僅供參考,MyISAM在查詢時(shí),會(huì)將索引節(jié)點(diǎn)緩存在MySQL緩存中,而數(shù)據(jù)緩存依賴于操作系統(tǒng)自身的緩存,所以并不是每次都是走的磁盤,這里只是為了分析索引的使用過(guò)程。
輔助索引
在 MyISAM 中,輔助索引和主鍵索引的結(jié)構(gòu)是一樣的,沒(méi)有任何區(qū)別,葉子節(jié)點(diǎn)的數(shù)據(jù)存儲(chǔ)的都是行記錄的磁盤地址。只是主鍵索引的鍵值是唯一的,而輔助索引的鍵值可以重復(fù)。
查詢數(shù)據(jù)時(shí),由于輔助索引的鍵值不唯一,可能存在多個(gè)擁有相同的記錄,所以即使是等值查詢,也需要按照范圍查詢的方式在輔助索引樹(shù)中檢索數(shù)據(jù)。
InnoDB索引
主鍵索引(聚簇索引)
每個(gè)InnoDB表都有一個(gè)聚簇索引 ,聚簇索引使用B+樹(shù)構(gòu)建,葉子節(jié)點(diǎn)存儲(chǔ)的數(shù)據(jù)是整行記錄。一般情況下,聚簇索引等同于主鍵索引,當(dāng)一個(gè)表沒(méi)有創(chuàng)建主鍵索引時(shí),InnoDB會(huì)自動(dòng)創(chuàng)建一個(gè)ROWID字段來(lái)構(gòu)建聚簇索引。InnoDB創(chuàng)建索引的具體規(guī)則如下:
- 在表上定義主鍵PRIMARY KEY,InnoDB將主鍵索引用作聚簇索引。
- 如果表沒(méi)有定義主鍵,InnoDB會(huì)選擇第一個(gè)不為NULL的唯一索引列用作聚簇索引。
- 如果以上兩個(gè)都沒(méi)有,InnoDB 會(huì)使用一個(gè)6 字節(jié)長(zhǎng)整型的隱式字段 ROWID字段構(gòu)建聚簇索引。該ROWID字段會(huì)在插入新行時(shí)自動(dòng)遞增。
除聚簇索引之外的所有索引都稱為輔助索引。在中InnoDB,輔助索引中的葉子節(jié)點(diǎn)存儲(chǔ)的數(shù)據(jù)是該行的主鍵值都。在檢索時(shí),InnoDB使用此主鍵值在聚簇索引中搜索行記錄。
這里以u(píng)ser_innodb為例,user_innodb的id列為主鍵,age列為普通索引。
- CREATE TABLE `user_innodb`
- (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `username` varchar(20) DEFAULT NULL,
- `age` int(11) DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE,
- KEY `idx_age` (`age`) USING BTREE
- ) ENGINE = InnoDB;
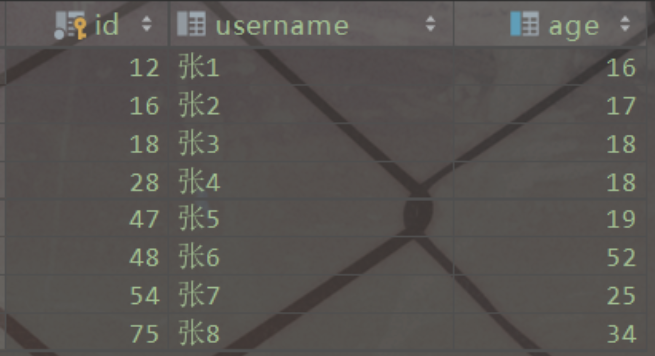
user數(shù)據(jù)
InnoDB的數(shù)據(jù)和索引存儲(chǔ)在一個(gè)文件t_user_innodb.ibd中。InnoDB的數(shù)據(jù)組織方式,是聚簇索引。
主鍵索引的葉子節(jié)點(diǎn)會(huì)存儲(chǔ)數(shù)據(jù)行,輔助索引只會(huì)存儲(chǔ)主鍵值。
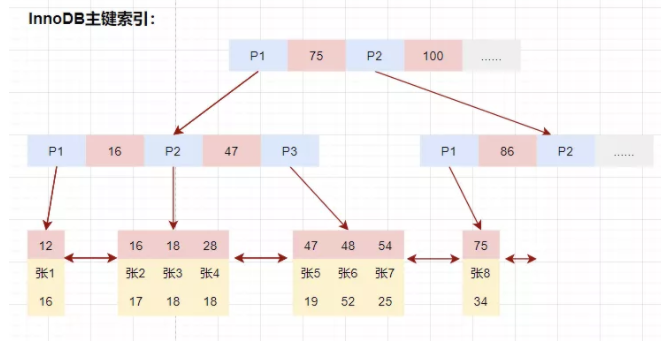
InnoDB主鍵索引
等值查詢數(shù)據(jù):
- select * from user_innodb where id = 28;
1.先在主鍵樹(shù)中從根節(jié)點(diǎn)開(kāi)始檢索,將根節(jié)點(diǎn)加載到內(nèi)存,比較28<75,走左路。(1次磁盤IO)
將左子樹(shù)節(jié)點(diǎn)加載到內(nèi)存中,比較16<28<47,向下檢索。(1次磁盤IO)
檢索到葉節(jié)點(diǎn),將節(jié)點(diǎn)加載到內(nèi)存中遍歷,比較16<28,18<28,28=28。查找到值等于28的索引項(xiàng),直接可以獲取整行數(shù)據(jù)。將改記錄返回給客戶端。(1次磁盤IO)
磁盤IO數(shù)量:3次。
輔助索引
除聚簇索引之外的所有索引都稱為輔助索引,InnoDB的輔助索引只會(huì)存儲(chǔ)主鍵值而非磁盤地址。
以表user_innodb的age列為例,age索引的索引結(jié)果如下圖。
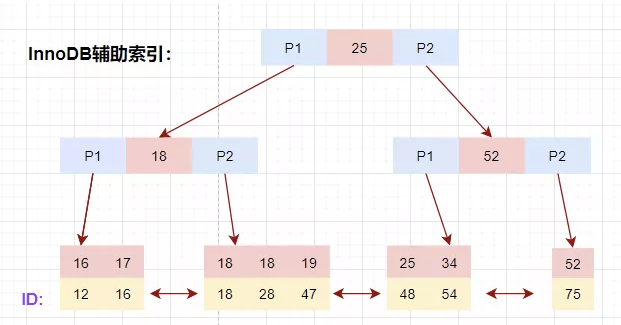
InnoDB輔助索引
底層葉子節(jié)點(diǎn)的按照(age,id)的順序排序,先按照age列從小到大排序,age列相同時(shí)按照id列從小到大排序。
使用輔助索引需要檢索兩遍索引:首先檢索輔助索引獲得主鍵,然后使用主鍵到主索引中檢索獲得記錄。
畫(huà)圖分析等值查詢的情況:
- select * from t_user_innodb where age=19;
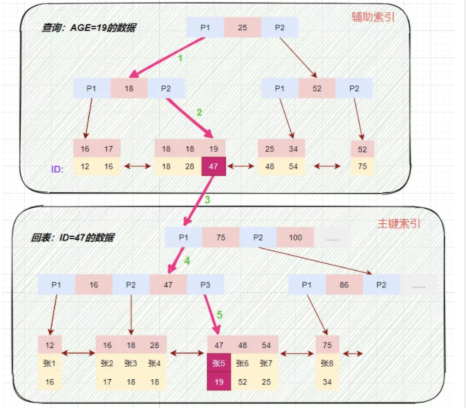
InnoDB輔助索引查詢
根據(jù)在輔助索引樹(shù)中獲取的主鍵id,到主鍵索引樹(shù)檢索數(shù)據(jù)的過(guò)程稱為回表查詢。
磁盤IO數(shù):輔助索引3次+獲取記錄回表3次
組合索引
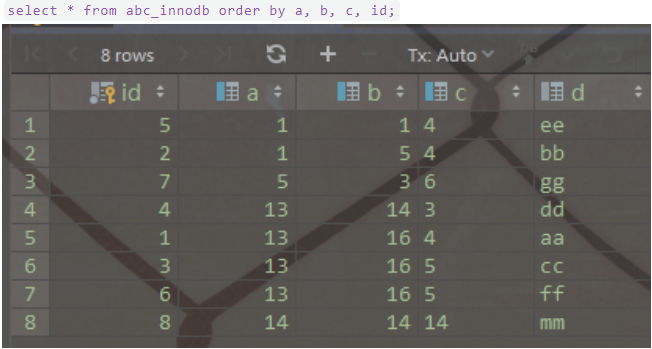
還是以自己創(chuàng)建的一個(gè)表為例:表 abc_innodb,id為主鍵索引,創(chuàng)建了一個(gè)聯(lián)合索引idx_abc(a,b,c)。
- CREATE TABLE `abc_innodb`
- (
- `id` int(11) NOT NULL AUTO_INCREMENT,
- `a` int(11) DEFAULT NULL,
- `b` int(11) DEFAULT NULL,
- `c` varchar(10) DEFAULT NULL,
- `d` varchar(10) DEFAULT NULL,
- PRIMARY KEY (`id`) USING BTREE,
- KEY `idx_abc` (`a`, `b`, `c`)
- ) ENGINE = InnoDB;
組合索引的數(shù)據(jù)結(jié)構(gòu):
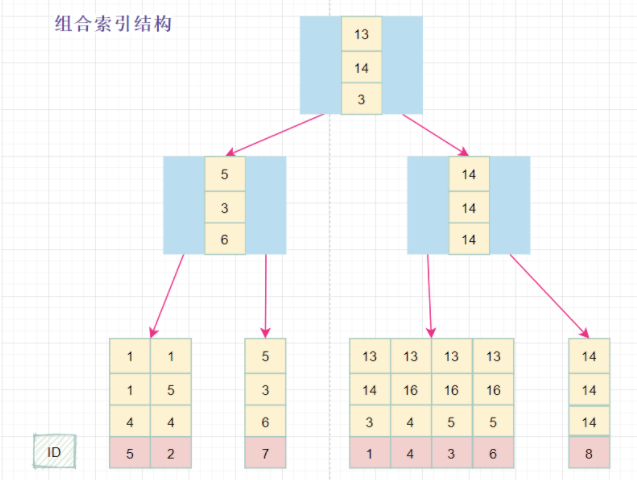
組合索引結(jié)構(gòu)1
組合索引的查詢過(guò)程:
- select * from abc_innodb where a = 13 and b = 16 and c = 4;
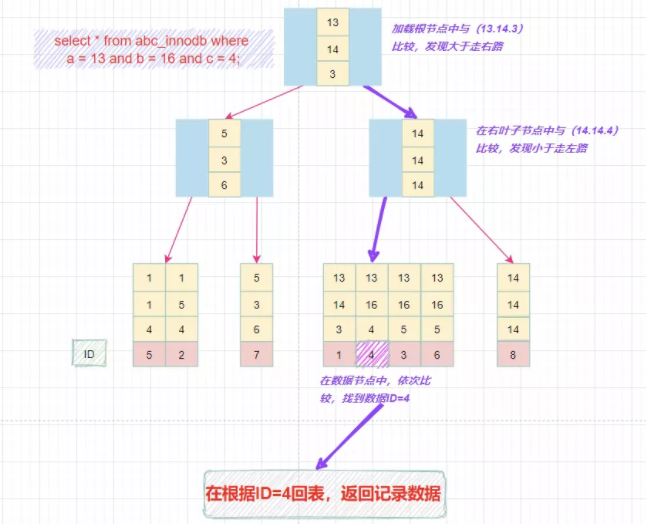
組合索引的查詢過(guò)程
最左匹配原則:
最左前綴匹配原則和聯(lián)合索引的索引存儲(chǔ)結(jié)構(gòu)和檢索方式是有關(guān)系的。
在組合索引樹(shù)中,最底層的葉子節(jié)點(diǎn)按照第一列a列從左到右遞增排列,但是b列和c列是無(wú)序的,b列只有在a列值相等的情況下小范圍內(nèi)遞增有序,而c列只能在a,b兩列相等的情況下小范圍內(nèi)遞增有序。
就像上面的查詢,B+樹(shù)會(huì)先比較a列來(lái)確定下一步應(yīng)該搜索的方向,往左還是往右。如果a列相同再比較b列。但是如果查詢條件沒(méi)有a列,B+樹(shù)就不知道第一步應(yīng)該從哪個(gè)節(jié)點(diǎn)查起。
可以說(shuō)創(chuàng)建的idx_abc(a,b,c)索引,相當(dāng)于創(chuàng)建了(a)、(a,b)(a,b,c)三個(gè)索引。、
組合索引的最左前綴匹配原則:使用組合索引查詢時(shí),mysql會(huì)一直向右匹配直至遇到范圍查詢(>、<、between、like)就停止匹配。
覆蓋索引
覆蓋索引并不是說(shuō)是索引結(jié)構(gòu),覆蓋索引是一種很常用的優(yōu)化手段。因?yàn)樵谑褂幂o助索引的時(shí)候,我們只可以拿到主鍵值,相當(dāng)于獲取數(shù)據(jù)還需要再根據(jù)主鍵查詢主鍵索引再獲取到數(shù)據(jù)。但是試想下這么一種情況,在上面abc_innodb表中的組合索引查詢時(shí),如果我只需要abc字段的,那是不是意味著我們查詢到組合索引的葉子節(jié)點(diǎn)就可以直接返回了,而不需要回表。這種情況就是覆蓋索引。
可以看一下執(zhí)行計(jì)劃:
覆蓋索引的情況:

使用到覆蓋索引
未使用到覆蓋索引:

總結(jié)
看到這里,你是不是對(duì)于自己的sql語(yǔ)句里面的索引的有了更多優(yōu)化想法呢。
比如:
避免回表
在InnoDB的存儲(chǔ)引擎中,使用輔助索引查詢的時(shí)候,因?yàn)檩o助索引葉子節(jié)點(diǎn)保存的數(shù)據(jù)不是當(dāng)前記錄的數(shù)據(jù)而是當(dāng)前記錄的主鍵索引,索引如果需要獲取當(dāng)前記錄完整數(shù)據(jù)就必然需要根據(jù)主鍵值從主鍵索引繼續(xù)查詢。這個(gè)過(guò)程我們成位回表。想想回表必然是會(huì)消耗性能影響性能。那如何避免呢?
使用索引覆蓋,舉個(gè)例子:現(xiàn)有User表(id(PK),name(key),sex,address,hobby...)
如果在一個(gè)場(chǎng)景下,select id,name,sex from user where name ='zhangsan';這個(gè)語(yǔ)句在業(yè)務(wù)上頻繁使用到,而user表的其他字段使用頻率遠(yuǎn)低于它,在這種情況下,如果我們?cè)诮?name 字段的索引的時(shí)候,不是使用單一索引,而是使用聯(lián)合索引(name,sex)這樣的話再執(zhí)行這個(gè)查詢語(yǔ)句是不是根據(jù)輔助索引查詢到的結(jié)果就可以獲取當(dāng)前語(yǔ)句的完整數(shù)據(jù)。
這樣就可以有效地避免了回表再獲取sex的數(shù)據(jù)。
這里就是一個(gè)典型的使用覆蓋索引的優(yōu)化策略減少回表的情況。
聯(lián)合索引的使用
聯(lián)合索引,在建立索引的時(shí)候,盡量在多個(gè)單列索引上判斷下是否可以使用聯(lián)合索引。聯(lián)合索引的使用不僅可以節(jié)省空間,還可以更容易的使用到索引覆蓋。
試想一下,索引的字段越多,是不是更容易滿足查詢需要返回的數(shù)據(jù)呢。比如聯(lián)合索引(a_b_c),是不是等于有了索引:a,a_b,a_b_c三個(gè)索引,這樣是不是節(jié)省了空間,當(dāng)然節(jié)省的空間并不是三倍于(a,a_b,a_b_c)三個(gè)索引,因?yàn)樗饕龢?shù)的數(shù)據(jù)沒(méi)變,但是索引data字段的數(shù)據(jù)確實(shí)真實(shí)的節(jié)省了。
聯(lián)合索引的創(chuàng)建原則,在創(chuàng)建聯(lián)合索引的時(shí)候因該把頻繁使用的列、區(qū)分度高的列放在前面,頻繁使用代表索引利用率高,區(qū)分度高代表篩選粒度大,這些都是在索引創(chuàng)建的需要考慮到的優(yōu)化場(chǎng)景,也可以在常需要作為查詢返回的字段上增加到聯(lián)合索引中,如果在聯(lián)合索引上增加一個(gè)字段而使用到了覆蓋索引,那我建議這種情況下使用聯(lián)合索引。
聯(lián)合索引的使用
- 考慮當(dāng)前是否已經(jīng)存在多個(gè)可以合并的單列索引,如果有,那么將當(dāng)前多個(gè)單列索引創(chuàng)建為一個(gè)聯(lián)合索引。
- 當(dāng)前索引存在頻繁使用作為返回字段的列,這個(gè)時(shí)候就可以考慮當(dāng)前列是否可以加入到當(dāng)前已經(jīng)存在索引上,使其查詢語(yǔ)句可以使用到覆蓋索引。
好啦以上就是我自己對(duì)索引的一些小總結(jié),有點(diǎn)小長(zhǎng)有點(diǎn)枯燥,適合收藏后慢慢看。
我是敖丙,你知道的越多,你不知道的越多,我們下期見(jiàn)。


















