













一口氣搞懂Flink Metrics監(jiān)控指標(biāo)和性能優(yōu)化,全靠這33張圖和7千字
本文轉(zhuǎn)載自微信公眾號「3分鐘秒懂大數(shù)據(jù)」,作者在IT中穿梭旅行。轉(zhuǎn)載本文請聯(lián)系3分鐘秒懂大數(shù)據(jù)公眾號。
前言
大家好,我是土哥。
最近在公司做 Flink 推理任務(wù)的性能測試,要對 job 的全鏈路吞吐、全鏈路時延、吞吐時延指標(biāo)進(jìn)行監(jiān)控和調(diào)優(yōu),其中要使用 Flink Metrics 對指標(biāo)進(jìn)行監(jiān)控。
接下來這篇文章,干貨滿滿,我將帶領(lǐng)讀者全面了解 Flink Metrics 指標(biāo)監(jiān)控,并通過實(shí)戰(zhàn)案例,對全鏈路吞吐、全鏈路時延、吞吐時延的指標(biāo)進(jìn)行性能優(yōu)化,徹底掌握 Flink Metrics 性能調(diào)優(yōu)的方法和 Metrics 的使用。大綱目錄如下:

1 Flink Metrics 簡介
Flink Metrics 是 Flink 集群運(yùn)行中的各項(xiàng)指標(biāo),包含機(jī)器系統(tǒng)指標(biāo),比如:CPU、內(nèi)存、線程、JVM、網(wǎng)絡(luò)、IO、GC 以及任務(wù)運(yùn)行組件(JM、TM、Slot、作業(yè)、算子)等相關(guān)指標(biāo)。
Flink Metrics 包含兩大作用:
- 實(shí)時采集監(jiān)控數(shù)據(jù)。在 Flink 的 UI 界面上,用戶可以看到自己提交的任務(wù)狀態(tài)、時延、監(jiān)控信息等等。
- 對外提供數(shù)據(jù)收集接口。用戶可以將整個 Flink 集群的監(jiān)控數(shù)據(jù)主動上報至第三方監(jiān)控系統(tǒng),如:prometheus、grafana 等,下面會介紹。
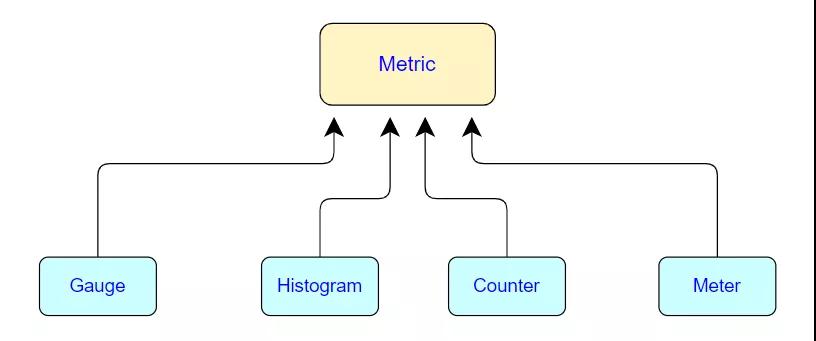
1.1 Flink Metric Types
Flink 一共提供了四種監(jiān)控指標(biāo):分別為 Counter、Gauge、Histogram、Meter。
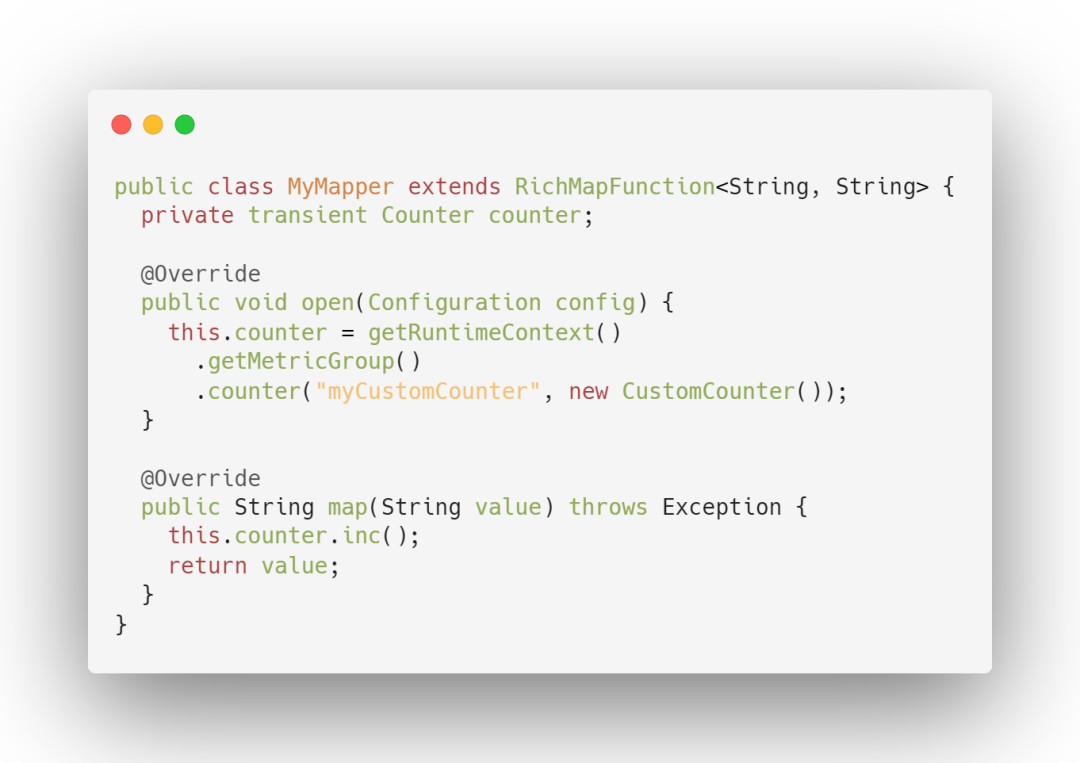
1. Count 計(jì)數(shù)器
統(tǒng)計(jì)一個 指標(biāo)的總量。寫過 MapReduce 的開發(fā)人員就應(yīng)該很熟悉 Counter,其實(shí)含義都是一樣的,就是對一個計(jì)數(shù)器進(jìn)行累加,即對于多條數(shù)據(jù)和多兆數(shù)據(jù)一直往上加的過程。其中 Flink 算子的接收記錄總數(shù) (numRecordsIn) 和發(fā)送記錄總數(shù) (numRecordsOut) 屬于 Counter 類型。
使用方式:可以通過調(diào)用 counter(String name)來創(chuàng)建和注冊 MetricGroup
2. Gauge 指標(biāo)瞬時值
Gauge 是最簡單的 Metrics ,它反映一個指標(biāo)的瞬時值。比如要看現(xiàn)在 TaskManager 的 JVM heap 內(nèi)存用了多少,就可以每次實(shí)時的暴露一個 Gauge,Gauge 當(dāng)前的值就是 heap 使用的量。
使用前首先創(chuàng)建一個實(shí)現(xiàn) org.apache.flink.metrics.Gauge 接口的類。返回值的類型沒有限制。您可以通過在 MetricGroup 上調(diào)用 gauge。

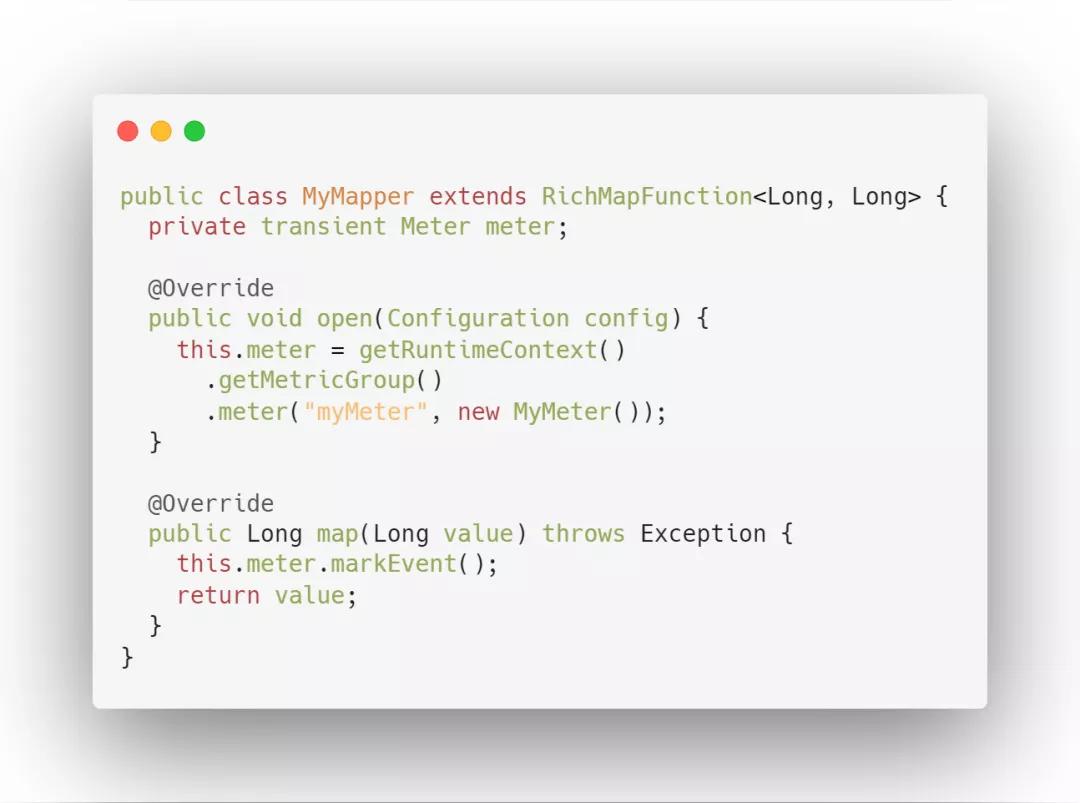
3. Meter 平均值
用來記錄一個指標(biāo)在某個時間段內(nèi)的平均值。Flink 中的指標(biāo)有 Task 算子中的 numRecordsInPerSecond,記錄此 Task 或者算子每秒接收的記錄數(shù)。
使用方式:通過 markEvent() 方法注冊事件的發(fā)生。通過markEvent(long n) 方法注冊同時發(fā)生的多個事件。
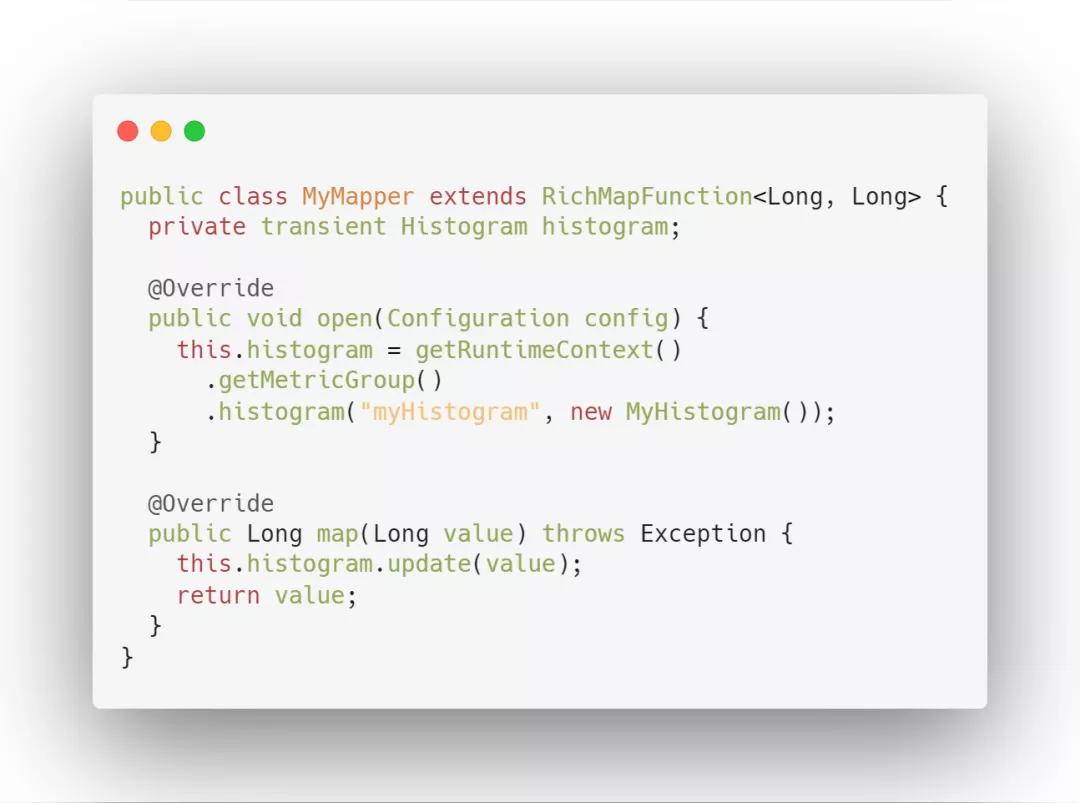
4. Histogram 直方圖
Histogram 用于統(tǒng)計(jì)一些數(shù)據(jù)的分布,比如說 Quantile、Mean、StdDev、Max、Min 等,其中最重要一個是統(tǒng)計(jì)算子的延遲。此項(xiàng)指標(biāo)會記錄數(shù)據(jù)處理的延遲信息,對任務(wù)監(jiān)控起到很重要的作用。
使用方式:通過調(diào)用 histogram(String name, Histogram histogram) 來注冊一個 MetricGroup。
1.2 Scope
Flink 的指標(biāo)體系按樹形結(jié)構(gòu)劃分,域相當(dāng)于樹上的頂點(diǎn)分支,表示指標(biāo)大的分類。每個指標(biāo)都會分配一個標(biāo)識符,該標(biāo)識符將基于 3 個組件進(jìn)行匯報:
- 注冊指標(biāo)時用戶提供的名稱;
- 可選的用戶自定義域;
- 系統(tǒng)提供的域。
例如,如果 A.B 是系統(tǒng)域,C.D 是用戶域,E 是名稱,那么指標(biāo)的標(biāo)識符將是 A.B.C.D.E. 你可以通過設(shè)置 conf/flink-conf.yam 里面的 metrics.scope.delimiter 參數(shù)來配置標(biāo)識符的分隔符(默認(rèn)“.”)。
舉例說明:以算子的指標(biāo)組結(jié)構(gòu)為例,其默認(rèn)為:
算子的輸入記錄數(shù)指標(biāo)為:
hlinkui.taskmanager.1234.wordcount.flatmap.0.numRecordsIn
1.3 Metrics 運(yùn)行機(jī)制
在生產(chǎn)環(huán)境下,為保證對Flink集群和作業(yè)的運(yùn)行狀態(tài)進(jìn)行監(jiān)控,F(xiàn)link 提供兩種集成方式:
1.3.1 主動方式 MetricReport
Flink Metrics 通過在 conf/flink-conf.yaml 中配置一個或者一些 reporters,將指標(biāo)暴露給一個外部系統(tǒng).這些 reporters 將在每個 job 和 task manager 啟動時被實(shí)例化。
1.3.2 被動方式 RestAPI
通過提供 Rest 接口,被動接收外部系統(tǒng)調(diào)用,可以返回集群、組件、作業(yè)、Task、算子的狀態(tài)。Rest API 實(shí)現(xiàn)類是 WebMonitorEndpoint
2 Flink Metrics 監(jiān)控系統(tǒng)搭建
Flink 主動方式共提供了 8 種 Report。
我們使用 PrometheusPushGatewayReporter 方式 通過 prometheus + pushgateway + grafana 組件搭建 Flink On Yarn 可視化監(jiān)控。
當(dāng) 用戶 使用 Flink 通過 session 模式向 yarn 集群提交一個 job 后,F(xiàn)link 會通過 PrometheusPushGatewayReporter 將 metrics push 到 pushgateway 的 9091 端口上,然后使用外部系統(tǒng) prometheus 從 pushgateway 進(jìn)行 pull 操作,將指標(biāo)采集過來,通過 Grafana可視化工具展示出來。原理圖如下:
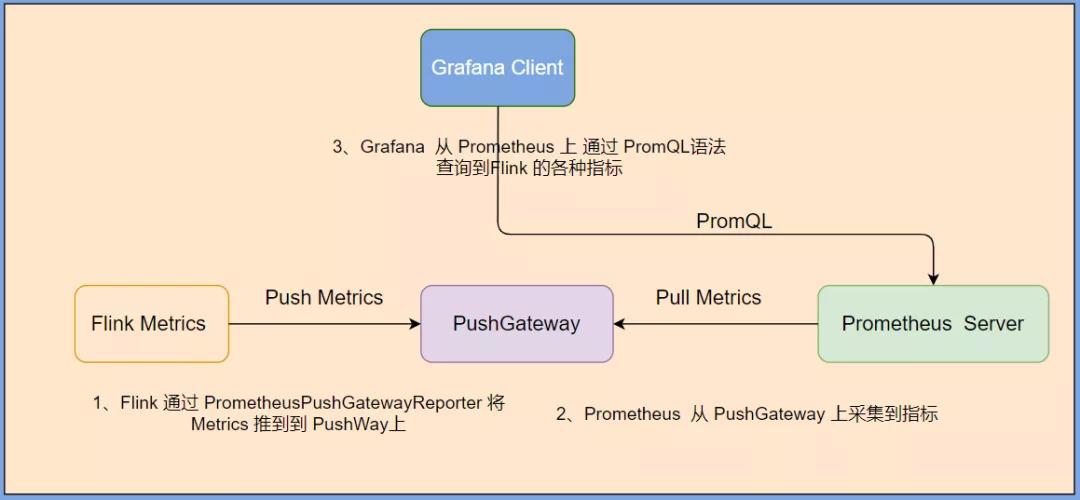
首先,我們先在 Flink On Yarn 集群中提交一個 Job 任務(wù),讓其運(yùn)行起來,然后執(zhí)行下面的操作。
2.1 配置 Reporter
下面所有工具、jar 包已經(jīng)全部下載好,需要的朋友在公眾號后臺回復(fù):02,可以全部獲取到。
2.1.1 導(dǎo)包
將 flink-metrics-prometheus_2.11-1.13.2.jar 包導(dǎo)入 flink-1.13.2/bin 目錄下。
2.1.2 配置 Reporter
選取 PrometheusPushGatewayReporter 方式,通過在官網(wǎng)查詢 Flink 1.13.2 Metrics 的配置后,在 flink-conf.yaml 設(shè)置,配置如下:
- metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
- metrics.reporter.promgateway.host: 192.168.244.129
- metrics.reporter.promgateway.port: 9091
- metrics.reporter.promgateway.jobName: myJob
- metrics.reporter.promgateway.randomJobNameSuffix: true
- metrics.reporter.promgateway.deleteOnShutdown: false
- metrics.reporter.promgateway.groupingKey: k1=v1;k2=v2
- metrics.reporter.promgateway.interval: 60 SECONDS
2.2 部署 pushgateway
Pushgateway 是一個獨(dú)立的服務(wù),Pushgateway 位于應(yīng)用程序發(fā)送指標(biāo)和 Prometheus 服務(wù)器之間。
Pushgateway 接收指標(biāo),然后將其作為目標(biāo)被 Prometheus 服務(wù)器拉取。可以將其看作代理服務(wù),或者與 blackbox exporter 的行為相反,它接收度量,而不是探測它們。
2.2.1 解壓 pushgateway

2.2.2. 啟動 pushgateway
進(jìn)入到 pushgateway-1.4.1 目錄下
- ./pushgateway &
查看是否在后臺啟動成功
- ps aux|grep pushgateway
2.2.3. 登錄 pushgateway webui

2.3 部署 prometheus
Prometheus(普羅米修斯)是一個最初在 SoundCloud 上構(gòu)建的監(jiān)控系統(tǒng)。自 2012 年成為社區(qū)開源項(xiàng)目,擁有非常活躍的開發(fā)人員和用戶社區(qū)。為強(qiáng)調(diào)開源及獨(dú)立維護(hù),Prometheus 于 2016 年加入云原生云計(jì)算基金會(CNCF),成為繼Kubernetes 之后的第二個托管項(xiàng)目。
2.3.1 解壓prometheus-2.30.0

2.3.2 編寫配置文件
- scrape_configs:
- - job_name: 'prometheus'
- static_configs:
- - targets: ['192.168.244.129:9090']
- labels:
- instance: 'prometheus'
- - job_name: 'linux'
- static_configs:
- - targets: ['192.168.244.129:9100']
- labels:
- instance: 'localhost'
- - job_name: 'pushgateway'
- static_configs:
- - targets: ['192.168.244.129:9091']
- labels:
- instance: 'pushgateway'
2.3.3 啟動prometheus
- ./prometheus --config.file=prometheus.yml &
啟動完后,可以通過 ps 查看一下端口:
- ps aux|grep prometheus
2.3.4 登錄prometheus webui
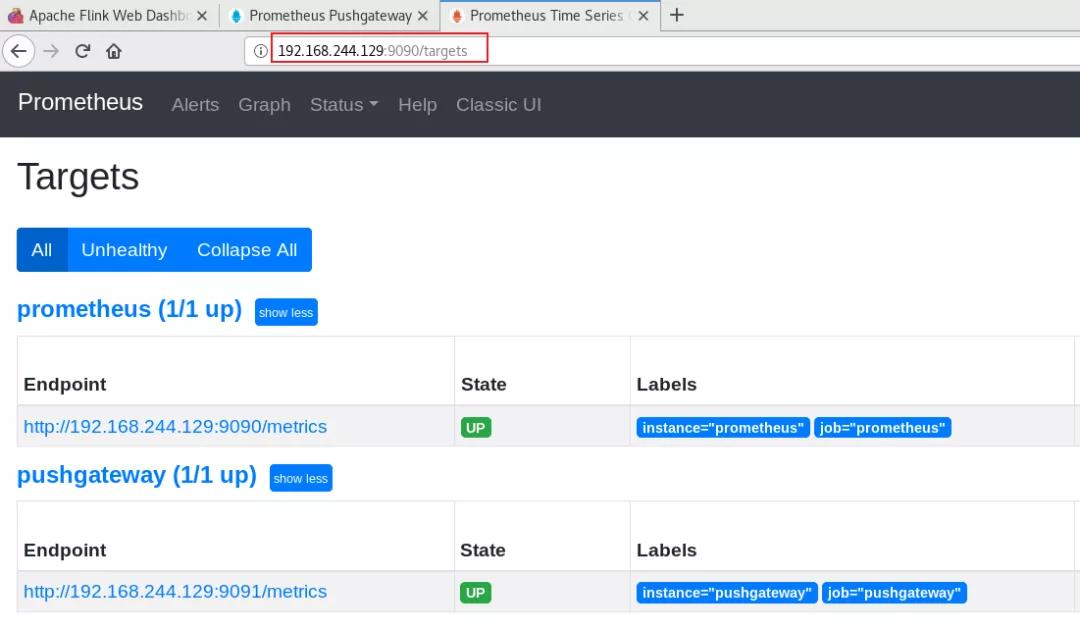
2.4 部署 grafana
Grafana 是一個跨平臺的開源的度量分析和可視化工具,可以通過將采集的數(shù)據(jù)查詢?nèi)缓罂梢暬恼故荆⒓皶r通知。它主要有以下六大特點(diǎn):
- 展示方式:快速靈活的客戶端圖表,面板插件有許多不同方式的可視化指標(biāo)和日志,官方庫中具有豐富的儀表盤插件,比如熱圖、折線圖、圖表等多種展示方式;
- 數(shù)據(jù)源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch 和 KairosDB 等;
- 通知提醒:以可視方式定義最重要指標(biāo)的警報規(guī)則,Grafana將不斷計(jì)算并發(fā)送通知,在數(shù)據(jù)達(dá)到閾值時通過 Slack、PagerDuty 等獲得通知;
- 混合展示:在同一圖表中混合使用不同的數(shù)據(jù)源,可以基于每個查詢指定數(shù)據(jù)源,甚至自定義數(shù)據(jù)源;
- 注釋:使用來自不同數(shù)據(jù)源的豐富事件注釋圖表,將鼠標(biāo)懸停在事件上會顯示完整的事件元數(shù)據(jù)和標(biāo)記;
- 過濾器:Ad-hoc 過濾器允許動態(tài)創(chuàng)建新的鍵/值過濾器,這些過濾器會自動應(yīng)用于使用該數(shù)據(jù)源的所有查詢。
2.4.1 解壓grafana-8.1.5
2.4.2 啟動grafana-8.1.5
- ./bin/grafana-server web &
2.4.3 登錄 grafana
登錄用戶名和密碼都是 admin
grafana 配置中文教程:
https://grafana.com/docs/grafana/latest/datasources/prometheus/
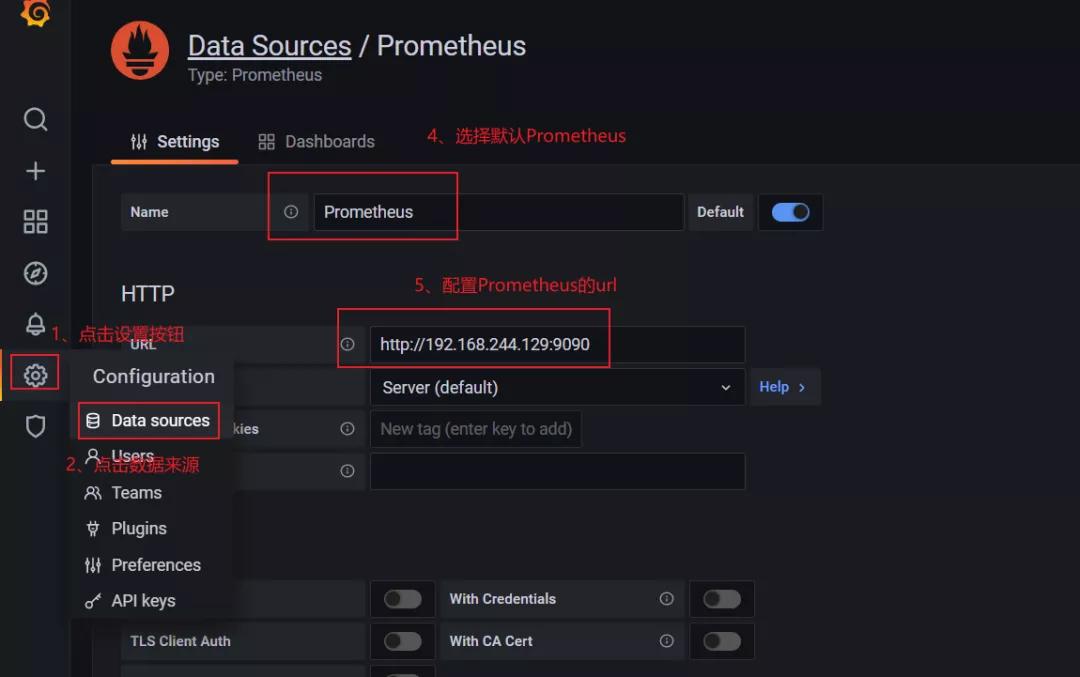
2.4.4 配置數(shù)據(jù)源、創(chuàng)建系統(tǒng)負(fù)載監(jiān)控
要訪問 Prometheus 設(shè)置,請將鼠標(biāo)懸停在配置(齒輪)圖標(biāo)上,然后單擊數(shù)據(jù)源,然后單擊 Prometheus 數(shù)據(jù)源,根據(jù)下圖進(jìn)行操作。
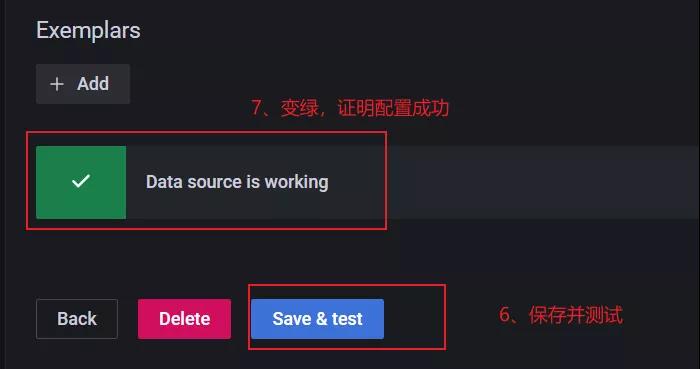
操作完成后,點(diǎn)擊進(jìn)行驗(yàn)證。
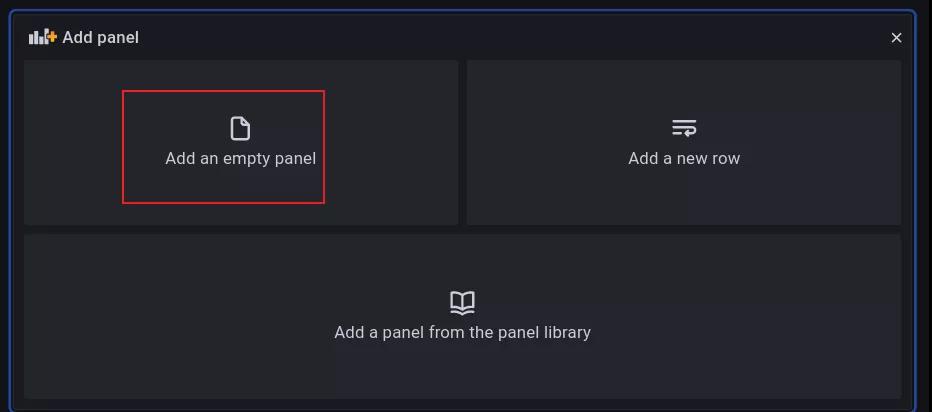
2.4.5 添加儀表盤
點(diǎn)擊最左側(cè) + 號,選擇 DashBoard,選擇新建一個 pannel。

至此,F(xiàn)link 的 metrics 的指標(biāo)展示在 Grafana 中了。
flink 指標(biāo)對應(yīng)的指標(biāo)名比較長,可以在 Legend 中配置顯示內(nèi)容,在{{key}} 將 key 換成對應(yīng)需要展示的字段即可,如:{{job_name}},{{operator_name}}。
3 指標(biāo)性能測試
上述監(jiān)控系統(tǒng)搭建好了之后,我們可以進(jìn)行性能指標(biāo)監(jiān)控了。現(xiàn)在以一個實(shí)戰(zhàn)案例進(jìn)行介紹:
3.1 業(yè)務(wù)場景介紹
金融風(fēng)控場景
3.1.1 業(yè)務(wù)需求:
Flink Source 從 data kafka topic 中讀取推理數(shù)據(jù),通過 sql 預(yù)處理成模型推理要求的數(shù)據(jù)格式,在進(jìn)行 keyBy 分組后流入下游 connect 算子,與模型 connect 后進(jìn)入 Co-FlatMap 算子再進(jìn)行推理,原理圖如下:
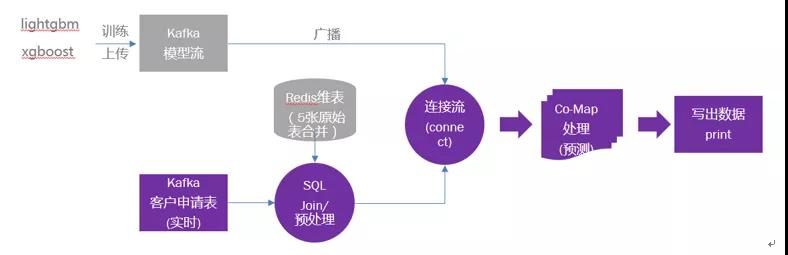
3.1.2 業(yè)務(wù)要求:
根據(jù)模型的復(fù)雜程度,要求推理時延到達(dá) 20ms 以內(nèi),全鏈路耗時 50ms 以內(nèi), 吞吐量達(dá)到每秒 1.2w 條以上。
3.1.3 業(yè)務(wù)數(shù)據(jù):
推理數(shù)據(jù):3000w,推理字段 495 個,機(jī)器學(xué)習(xí) Xgboost 模型字段:495。
3.2 指標(biāo)解析
由于性能測試要求全鏈路耗時 50ms 以內(nèi),應(yīng)該使用 Flink Metrics 的 Latency Marker 進(jìn)行計(jì)算。
3.2.1 全鏈路時延計(jì)算方式 :
全鏈路時延指的是一條推理數(shù)據(jù)進(jìn)入 source 算子到數(shù)據(jù)預(yù)處理算子直到最后一個算子輸出結(jié)果的耗時,即處理一條數(shù)據(jù)需要多長時間,包含算子內(nèi)處理邏輯時間,算子間數(shù)據(jù)傳遞時間,緩沖區(qū)內(nèi)等待時間。
全鏈路時延要使用 latency metric 計(jì)算。latency metric 是由 source 算子根據(jù)當(dāng)前本地時間生成的一個 marker ,并不參與各個算子的邏輯計(jì)算,僅僅跟著數(shù)據(jù)往下游算子流動,每到達(dá)一個算子則算出當(dāng)前本地時間戳并與 source 生成的時間戳相減,得到 source 算子到當(dāng)前算子的耗時,當(dāng)?shù)竭_(dá) sink 算子或者說最后一個算子時,算出當(dāng)前本地時間戳與 source 算子生成的時間戳相減,即得到全鏈路時延。原理圖如下:
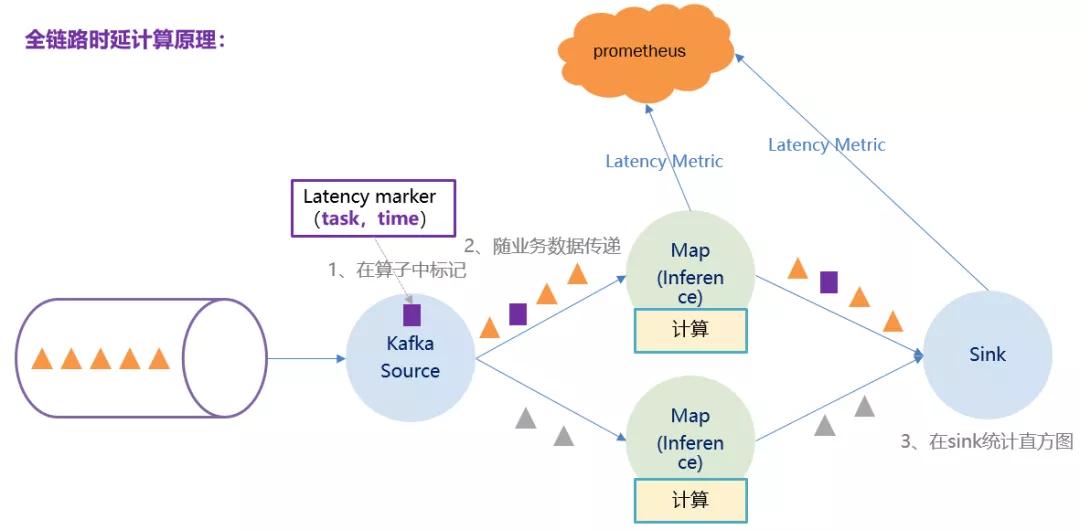
由于使用到 Lateny marker,所有需要在 flink-conf.yaml 配置參數(shù)。
- latency.metrics.interval
系統(tǒng)配置截圖如下:

3.2.2 全鏈路吞吐計(jì)算方式 :
全鏈路吞吐 = 單位時間處理數(shù)據(jù)數(shù)量 / 單位時間。
3.3 提交任務(wù)到Flink on Yarn集群
**3.3.1 直接提交 Job **
- # -m jobmanager 的地址
- # -yjm 1024 指定 jobmanager 的內(nèi)存信息
- # -ytm 1024 指定 taskmanager 的內(nèi)存信息
- bin/flink run \
- -t yarn-per-job -yjm 4096 -ytm 8800 -s 96 \
- --detached -c com.threeknowbigdata.datastream.XgboostModelPrediction \
- examples/batch/WordCount.jar \
提交完成后,我們通過 Flink WEBUI 可以看到 job 運(yùn)行的任務(wù)結(jié)果如下:
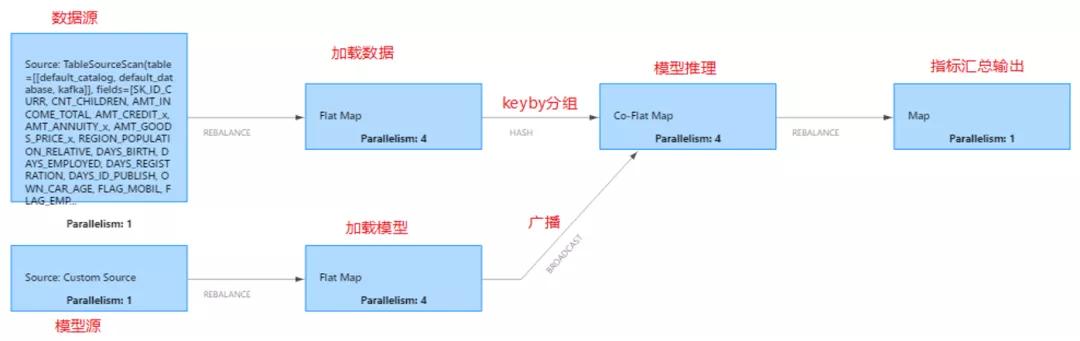
因?yàn)橥评砟P椭皇且粋€ model,存在狀態(tài)中,所以全鏈路吞吐考慮的是每秒有多少條推理數(shù)據(jù)進(jìn)入 source 算子到倒數(shù)第二個算子(最后一個算子只是指標(biāo)匯總)流出,這個條數(shù)就是全鏈路吞吐。
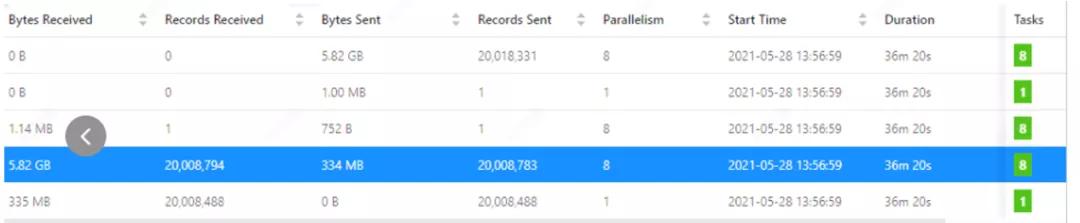
可以看到在處理 2000W 條數(shù)據(jù)時,代碼直接統(tǒng)計(jì)輸出的數(shù)值和 flink webUI 的統(tǒng)計(jì)數(shù)值基本一致,所以統(tǒng)計(jì)數(shù)值是可信的。

Flink WEBUI 跑的結(jié)果數(shù)據(jù)
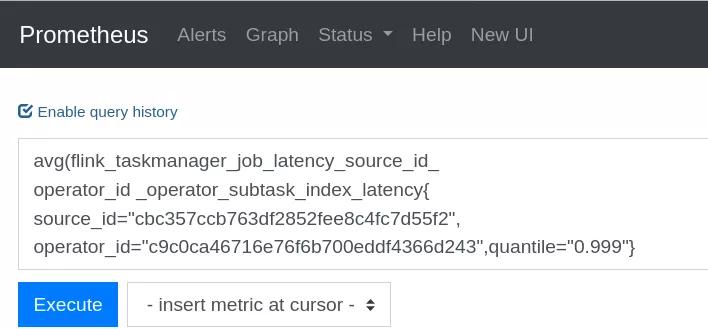
打開 Prometheus 在對話框輸入全鏈路時延計(jì)算公式
- 計(jì)算公式:
- avg(flink_taskmanager_job_latency_source_id_
- operator_id _operator_subtask_index_latency{
- source_id="cbc357ccb763df2852fee8c4fc7d55f2",
- operator_id="c9c0ca46716e76f6b700eddf4366d243",quantile="0.999"})
3.4 優(yōu)化前性能分析
在將任務(wù)提交到集群后,經(jīng)過全鏈路時延計(jì)算公式、吞吐時延計(jì)算公式,最后得到優(yōu)化前的結(jié)果時延指標(biāo)統(tǒng)計(jì)圖如下:

吞吐指標(biāo)統(tǒng)計(jì)圖如下:

通過本次測試完后,從圖中可以發(fā)現(xiàn):
時延指標(biāo):加并行度,吞吐量也跟隨高,但是全鏈路時延大幅增長( 1并行至32并行,時延從 110ms 增加至 3287ms )
這遠(yuǎn)遠(yuǎn)沒有達(dá)到要求的結(jié)果。
3.5 問題分析
通過 Prometheus分析后,結(jié)果如下:

3.5.1 并行度問題 :
反壓現(xiàn)象:在 Flink WEB-UI 上,可以看到應(yīng)用存在著非常嚴(yán)重的反壓,這說明鏈路中存在較為耗時的算子,阻塞了整個鏈路;
數(shù)據(jù)處理慢于拉取數(shù)據(jù):數(shù)據(jù)源消費(fèi)數(shù)據(jù)的速度,大于下游數(shù)據(jù)處理速度;
增加計(jì)算并行度:所以在接下來的測試中會調(diào)大推理算子并行度,相當(dāng)于提高下游數(shù)據(jù)處理能力。
3.5.2 Buffer 超時問題 :
Flink 雖是純流式框架,但默認(rèn)開啟了緩存機(jī)制(上游累積部分?jǐn)?shù)據(jù)再發(fā)送到下游);
緩存機(jī)制可以提高應(yīng)用的吞吐量,但是也增大了時延;
推理場景:為獲取最好的時延指標(biāo),第二輪測試超時時間置 0,記錄吞吐量。
3.5.3 Buffer 數(shù)量問題 :
同上,F(xiàn)link 中的 Buffer 數(shù)量是可以配置的;
Buffer 數(shù)量越多,能緩存的數(shù)據(jù)也就越多;
推理場景:為獲取最好的時延指標(biāo),第二輪測試:減小 Flink 的 Buffer 數(shù)量來優(yōu)化時延指標(biāo)。
3.5.4 調(diào)優(yōu)參數(shù)配置
SOURCE 與 COFLATMAP 的并行度按照 1:12 配置;
Buffer 超時時間配置為 0ms (默認(rèn)100ms);
- //在代碼中設(shè)置
- senv.setBufferTimeout(0);
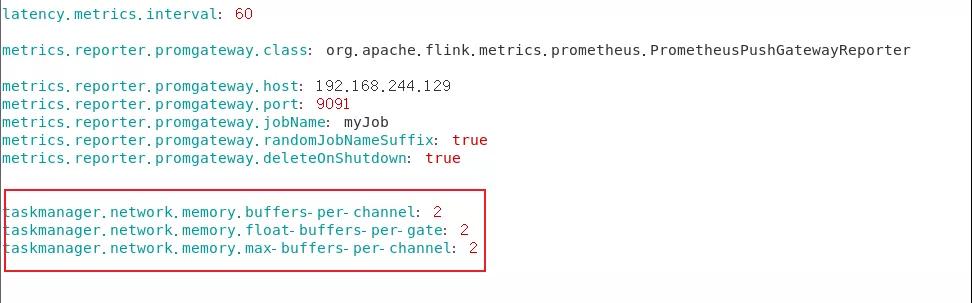
Buffer 數(shù)量的配置如下:
修改flink-conf.yaml
- memory.buffers-per-channel: 2
- memory.float-buffers-per-gate: 2
- memory.max-buffers-per-channel: 2
配置截圖如下:
3.6 優(yōu)化后性能分析
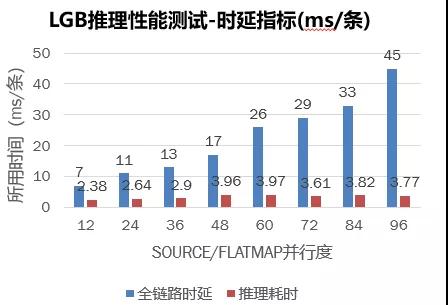
經(jīng)過修改配置后,將任務(wù)再次提交到集群后,經(jīng)過全鏈路時延計(jì)算公式、吞吐時延計(jì)算公式,最后得到優(yōu)化后的結(jié)果。
時延指標(biāo)統(tǒng)計(jì)圖如下:
吞吐指標(biāo)統(tǒng)計(jì)圖如下:

優(yōu)化后 LGB 推理測試總結(jié) :
時延指標(biāo):并行度提升,時延也會增加,但幅度很小(可接受)。實(shí)際上,在測試過程中存在一定反壓,若調(diào)大 SOURCE 與 COFLATMAP 的并行度比例,全鏈路時延可進(jìn)一步降低;吞吐量指標(biāo):隨著并行度的增加,吞吐量也隨著提高,當(dāng)并行度提高至 96 時,吞吐量可以達(dá)到 1.3W,此時的時延維持在 50ms 左右(比較穩(wěn)定)。
3.7 優(yōu)化前后 LGB 分析總結(jié)
如下圖所示:
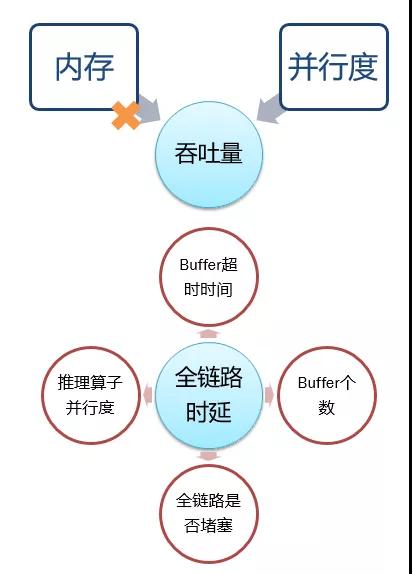
3.7.1吞吐量---影響因素:
內(nèi)存:對吞吐和時延沒什么影響, 并行度與吞吐成正相關(guān)。
- 增大 kafka 分區(qū),吞吐增加
- 增大 source、維表 source 并行度
- 增大 flatmap 推理并行度
3.7.2全鏈路時延---影響因素:
- Buffer 超時越短、個數(shù)越少、時延越低。
- 整個鏈路是否有算子堵塞(車道排隊(duì)模型)。
- 調(diào)大推理算子并行度,時延降低,吞吐升高(即增加了推理的處理能力)。


















