













在預訓練NLP模型上測量性別相關性
在過去的幾年中,自然語言處理(NLP)取得了長足的進步,諸如BERT,ALBERT,ELECTRA和XLNet等預訓練語言模型在各種任務中均取得較高的準確性。預訓練語言模型以Wikipedia這樣的大型文本語料庫為訓練集,通過遮掩一些單詞并對它們進行預測來學習嵌入表示,即遮掩語言建模。實驗結果表明,通過這樣的方式,可以對不同概念(如外科醫生和手術刀)間的豐富語義信息進行編碼。訓練完成后,經過微調就可使模型適用特定任務的訓練數據,通過預訓練嵌入實現分類等特定任務。鑒于這樣的預訓練表示在不同NLP任務中得到廣泛采用,作為從業者,我們需要了解預訓練模型如何對信息編碼以及學習到怎樣的相關性,這些又會怎樣影響下游應用性能,這樣才不至于偏離我們的AI原則。
在“Measuring and Reducing Gendered Correlations in Pre-trained Models”,我們對BERT及精簡版的ALBERT進行實例研究,討論了性別相關性,并為預訓練語言模型的實踐應用提供參考。我們在學術任務數據集進行實驗,并將結果與一些常用模型做了對比,以驗證模型實用性,并為進一步的研究提供參考。我們后續會發布一系列checkpoints,從而可以在保持NLP任務準確性的情況下減少性別相關性。
相關性衡量
為了解預訓練表征中的相關性如何影響下游任務,可以使用多種評估指標來研究性別表征。在這里,我們采用共指消解討論測試結果,該方法旨在使模型能夠理解句子中給定代詞的正確先行詞, 例圖示句子中,模型要識別出他指護士而不是患者。

OntoNotes(Hovy等,2006)是最常用得標準驗證數據集,同時F1分數用來衡量模型在共指消解中的準確性(Tenney等。2019)。由于OntoNotes僅表示一種數據分布,因此我們還使用WinoGender基準測試,該基準提供了一些其他數據,通過該基準可以判別性別和職業何時會產生錯誤的共指消解。WinoGender的得分較高(接近1),表明模型基于性別與職業間的關聯(如將護士與女性而不是男性關聯)進行決策;當性別和職業之間沒有一致的關聯時(得分為零),此時模型決策基于句子結構或語義等其他信息。
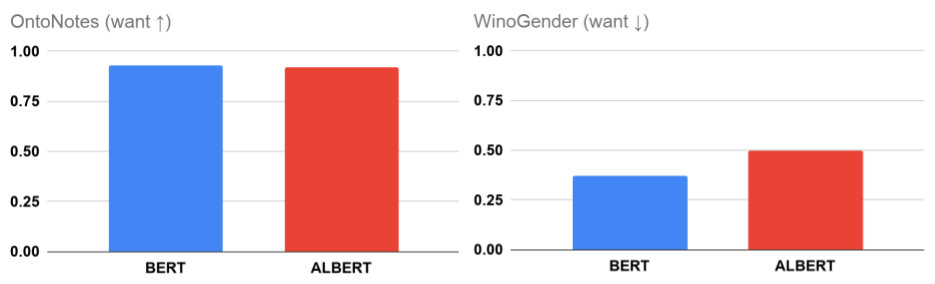
研究發現,BERT或ALBERT在WinoGender上都沒有零得分,而在OntoNotes上獲得了極高的準確性(接近100%)。實驗表明,在一些情況下,模型在推理決策中會考慮性別相關性。這符合我們的預期,模型可以使用多種線索來理解文本,可以只采用其中的一種或是選擇全部線索。當然,在實際應用中我們還是要謹慎,不能寄希望于模型根據先驗的性別相關性進行預測,其他可用信息對于預測也非常重要。
實踐指南
鑒于預訓練模型嵌入中的隱式關聯有可能影響下游任務,因此在開發新的NLP模型時,我們要考慮可以采取哪些措施來減輕這種風險?
- 隱式相關性的衡量非常重要:雖然可以使用準確性度量來評估模型質量,但是這樣度量方式僅從單一角度評估模型,在測試數據與訓練數據分布相同時其不足尤為顯著。例如,BERT和ALBERT檢查點的準確度相差1%以內,但使用性別相關性進行共指解析的相對偏差為26%。這意味著,對于某些任務,這樣的差異尤為重要。在處理一些反固定思維的文本時(如男護士),選擇WinoGender分數較低的模型更加合理。
- 更改任何模型配置時都要謹慎,哪怕看似影響不大:神經網絡模型訓練由許多超參數控制,一般通過選擇合理的超參數以最大化訓練目標。盡管某些參數選擇看似不會對模型產生什么影響,但我們卻發現,它們可能會導致性別相關性發生重大變化。例如,Dropout正則化用于避免模型的過度擬合,當我們在BERT和ALBERT訓練過程中增大Dropout參數,即使進行微調,性別相關性還是會顯著降低。這意味著微小的配置更改就可以影響訓練模型,從而降低相關性風險,但同時也表明,在對模型配置進行任何更改時,我們應該謹慎行事、仔細評估。
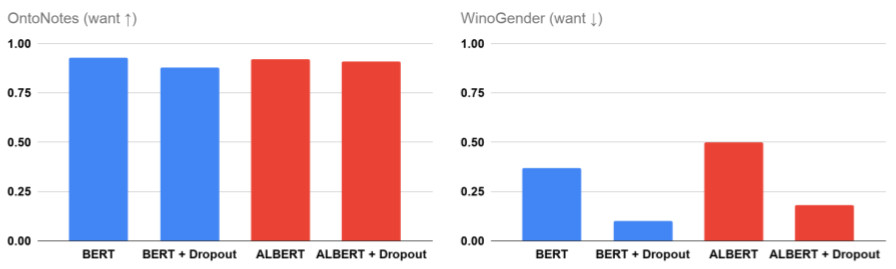
相關性的緩解:前文以介紹了Dropout對性別相關性的影響,據此,我們進一步推論得到通過這樣的方式可能減少額外的相關性:通過增加dropout參數,我們可以改進模型對WinoGender的推理方式,而無需手動指定任何內容,甚至不需要更改微調階段。然而,隨著dropout的增加,OneNotes的準確性也會開始下降(見BERT的結果),但我們認為可以在預訓練階段避免這種情況,通過更改dropout改進模型,而無需針對特定任務進行更新。在論文中,我們基于反事實數據增強,提出了另一種具有差異化權重的緩解策略。
展望
我們認為,以上這些實踐指南為開發強大的NLP系統提供了參考,從而使其適用于更廣泛的語言和應用范圍。當然,由于技術本身的不足,難以捕獲和消除所有潛在的問題。因此,在現實環境中部署的任何模型都應經過嚴格測試,即嘗試不同方法,并通過一些保護措施以確保符合道德規范,如Google的AI原則。我們期待評估框架與數據取得更進一步的發展,使語言模型適用于各種任務,為更多人提供優質服務。
致謝
本文的合作者包括Xuezhi Wang,Ian Tenney,Ellie Pavlick,Alex Beutel,Jilin Chen,Emily Pitler和Slav Petrov。同時感謝Fernando Pereira,Ed Chi,Dipanjan Das,Vera Axelrod,Jacob Eisenstein,Tulsee Doshi和James Wexler等人。



















