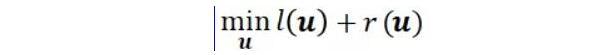顛覆大規模預訓練!清華楊植麟組提出全新NLP學習框架TLM,學習效率×100倍
近期,清華大學團隊提出一種無需預訓練的高效 NLP 學習框架,在僅使用了1% 的算力和1% 的訓練語料的條件下,在眾多 NLP 任務上實現了比肩甚至超越預訓練模型的性能。這一研究結果對大規模預訓練語言模型的必要性提出了質疑:我們真的需要大規模預訓練來達到最好的效果嗎?
基于預訓練語言模型(PLM)的方法在自然語言處理領域蓬勃發展,已經在多種標準自然語言任務上實現了最優(SOTA)性能。強大的性能使其成為解決 NLP 任務的標準方法之一。
盡管如此,預訓練嚴重依賴大量的計算資源的現狀,導致只有極少數資源充足的機構或者組織有能力開展對于預訓練的探索,多數研究者則轉向所需資源較少的下游微調算法的研究。 然而,微調算法性能的上限也是很大程度受到預訓練模型性能的約束。
這種「昂貴而集權」的研究模式限制了平民研究者們為 NLP 社區做出貢獻的邊界,也極大制約了該領域的長期發展。
清華大學的研究者們針對這一問題提出的一種全新的高效學習框架:「TLM(Task-driven Language Modeling)」。

論文地址:https://arxiv.org/pdf/2111.04130.pdf
項目地址:https://github.com/yaoxingcheng/TLM
TLM 框架無需進行大規模預訓練,僅需要相較于傳統預訓練模型(例如 RoBERTa)約 1% 的訓練時間與 1% 的語料, 即可在眾多任務上實現和預訓練模型比肩甚至更好的性能。
作者希望 TLM 的提出能夠引發 NLP 研究者們對現有預訓練-微調范式的重新審視,并促進 NLP 民主化的進程,加速 NLP 領域的進一步發展。
語言模型也可以「臨時抱佛腳」?
任務驅動的語言建模
我們有這樣的觀察:人類可以以有限的時間和精力高效掌握某種技能,這整個過程并不需要掌握所有可能的知識和信息,而是只需要對核心的部分有針對性地學習。
例如,考生考試前臨時抱佛腳,僅需要突擊學習重點內容即可應對考試。受到這一現象的啟發,我們不禁發問:預訓練語言模型可以「臨時抱佛腳」嗎?
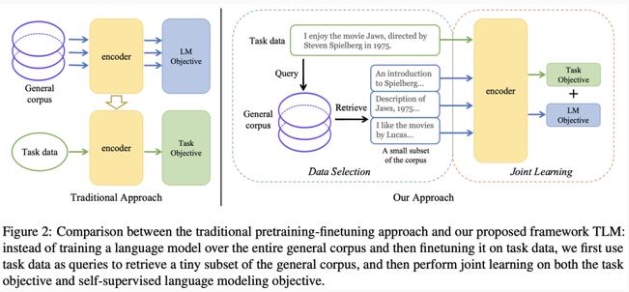
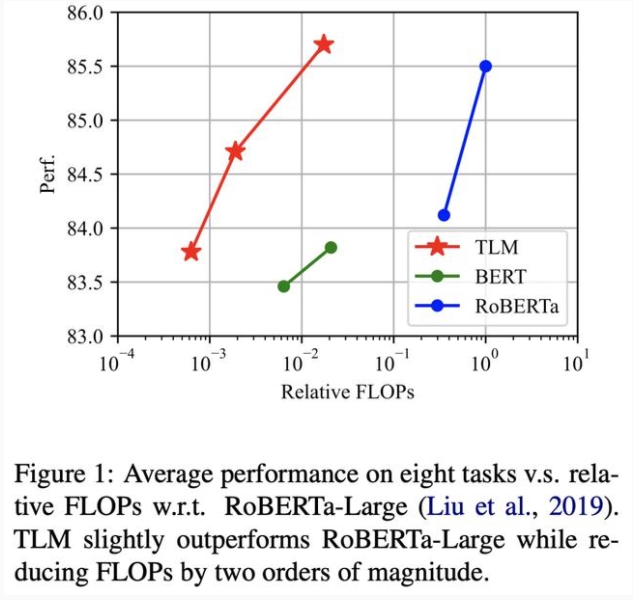
傳統的預訓練-微調方法與 TLM 框架之間的比較
類似地,作者提出假設:預訓練語言模型在特定任務上的性能,僅受益于大規模通用語料中僅與任務相關的部分,而不需要大規模的全量數據。
該方法主要包含兩個階段:
為了從大規模通用語料中抽取關鍵數據,TLM 首先以任務數據作為查詢,對通用語料庫進行相似數據的召回;
TLM 基于任務數據和召回數據,從零開始進行基于任務目標和語言建模目標的聯合訓練。
基于任務數據的語料召回
首先根據任務數據,從大規模通用語料中抽取相關數據。
相比于大多數文本匹配算法傾向于采用稠密特征,本文作者另辟蹊徑,采用了使用基于稀疏特征的 BM25 算法[2] 作為召回算法,它簡單高效,并且不依賴于下游任務給出的監督信號。
同時該算法完全不依賴預訓練模型,從而可以公平地與傳統的大規模預訓練進行比較。
自監督任務與下游任務的聯合訓練
TLM 基于篩選后的通用預料數據和任務數據,進行了自監督任務與下游任務的聯合訓練。
作者采用了傳統的掩碼語言模型(Masked Language Modeling)作為自監督訓練任務。

訓練的損失函數
實驗結果:小資源比肩大規模預訓練語言
主要結果
作者在 8 個自然語言分類任務上,從三個不同的規模分別開展了對比實驗。這些任務涵蓋了生物醫藥、新聞、評論、計算機等領域,并且覆蓋了情感分類、實體關系抽取、話題分類等任務類型。
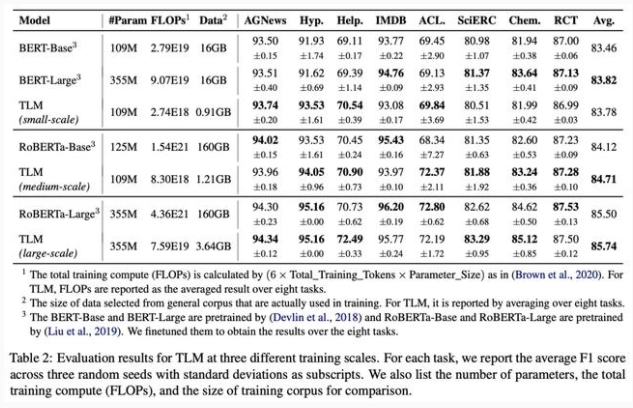
TLM 在三種不同訓練規模下的評估結果
和傳統的預訓練-微調范式相比,TLM 在多領域多任務類型的數據集上實現了大致相當甚至更優的結果。
而更大的優勢在于,TLM 實現該相當甚至更優的結果所使用的資源(包括計算量 FLOPs 和使用的訓練數據量),相較于對應預訓練-微調基準的資源使用量極大減少約兩個數量級規模。
參數高效性分析
為了探究 TLM 高效性更本質的來源,作者們對模型的每個注意力頭所輸出的注意力結果進行了可視化分析。
已有研究[1]指出,呈現「對角線」模式的注意力結果(如紅框所示)是對模型性能影響的關鍵因素,因為「對角線」模式把注意力關注于此前或者此后的符號(token)上,從而可以捕捉和建模相鄰符號之間的關聯性。

注意力結果可視化分析
從可視化結果可以觀察到,TLM 中包含了更多「對角線」模式,即有更多的符號位置都將注意力分散賦予了其相鄰的其他符號。
對比之下,原始的大規模預訓練模型(BERT-Base 和 RoBERTa-Base)「對角線」模式較少,而「垂直」模式更多(如灰色所示),這意味著更多符號位置將注意力關注到[CLS]、[SEP]或者標點符號這種不具備語法或者語義信息的符號上。
可以看出,TLM 的參數高效性要顯著優于預訓練語言模型,任務驅動使得 TLM 針對下游任務學習到了更豐富的語法語義信息。
消融實驗
此外作者還分別在數據選取策略、數據召回數量、多任務學習目標權重等多個角度進行了消融實驗探究,以此考察模型性能的穩定性和最優配置。
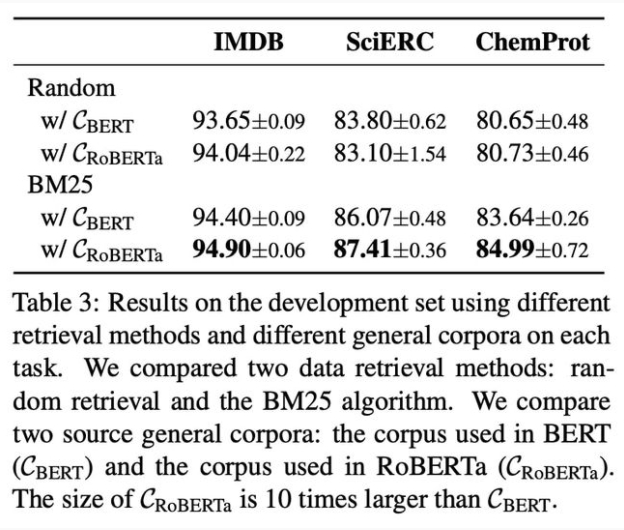
數據選取策略消融實驗結果
在數據召回策略上,相比起同等數量的隨機選取,基于稀疏特征的 BM25 算法最終結果有顯著提升(約1-4 個點),證明其在召回和任務數據相似的通用數據上的有效性。
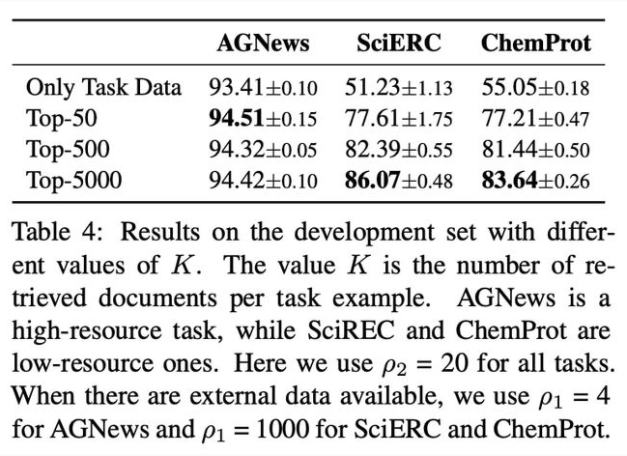
最優數據召回量消融實驗結果
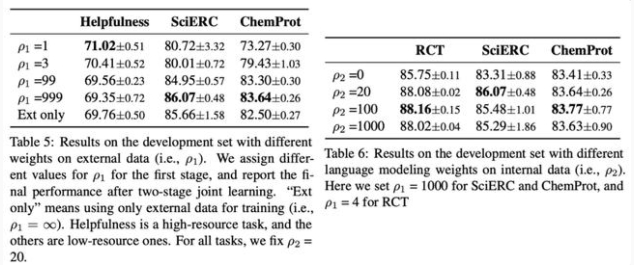
召回通用數據無監督訓練目標權重(ρ1) 和任務數據無監督訓練目標權重(ρ2) 消融實驗結果
對于最優數據召回量和多任務學習目標權重兩因素的消融實驗結果展示出一致的結論:即兩因素的選擇顯示出和任務數據規模強相關性:
對于數據規模較大的任務(如 AGNews,RCT),它需要召回相對更少的相似通用數據,同時應賦予任務數據目標更大的比重;
對于數據規模較小的任務(如 ChemProt,SciERC),它需要召回相對更多的通用數據提供充足信息,同時賦予召回通用數據上的無監督訓練目標更大的權重。
TLM vs PLM:優勢如何?
總結來說,PLM 以極高的成本學習盡可能多的任務無關的知識,而 TLM 以非常低的成本針對每個任務學習相關知識。
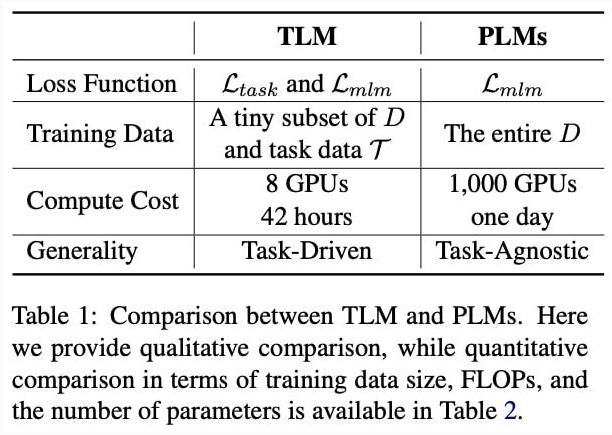
TLM 和 PLM 的對比
具體來說,TLM 和 PLM 相比還具有如下特點:
1. 民主化
TLM 的提出打破了 NLP 研究受限于大規模計算資源,以及只能由極少數機構和人員開展相關探索的現狀。基于 TLM 框架,大多數 NLP 研究者都可以以較低代價以及較高效率,對目前最先進的解決方案做更進一步的自由探索和研究。
2. 靈活性
相比 PLM,TLM 允許研究者以更加靈活的方式根據具體的任務自定義標記策略、數據表示、序列長度、超參數等等。這使得進一步提升性能和效率成為可能。
3. 高效性
如實驗結果所示,TLM 的每個任務上的 FLOPs 消耗顯著少于 PLM。TLM 和 PLM 分別適用不同情況——當面臨少數目標任務或者領域特定的稀有任務(例如,NLP 科研工作開展過程對少數數據集進行實驗和研究;工業界面臨極其特殊領域問題的解決),TLM 是非常高效的選擇;當需要一次性解決大量相似且常見任務時(例如,公司需要構建統一平臺為多方提供相似服務),PLM 的可重復利用使其仍然具備優勢。
4. 通用性
PLM 學習任務無關的一般性表示,即強調通用性,而 TLM 通過學習任務相關的表示一定程度犧牲通用性換取更高的效率。當然,也可以將 PLM 和 TLM 結合從而實現通用性和效率之間更好的權衡。
總結展望
TLM 的提出給自然語言處理領域帶來「新面貌」,它使得現有 NLP 的研究可以脫離代價高昂的預訓練,也使得更多獨立 NLP 研究者們可以在更廣闊的空間進行自由探索成為可能。
未來可以進一步開展更多基于 TLM 框架的研究,例如:如何進一步提升 TLM 的通用性和可遷移性;如何更加經濟地達到更大規模預訓練模型的表現效果等等。
作者介紹
論文一作為清華大學姚班大四本科生姚星丞,他也是今年大火的 EMNLP 接收論文 SimCSE 的共同一作。

論文地址:https://arxiv.org/pdf/2104.08821.pdf
論文的通訊作者為清華大學交叉信息院助理教授、Recurrent AI 聯合創始人楊植麟,曾做出 Transformer-XL、XLNet、HotpotQA 等諸多 NLP 領域大受歡迎的工作。
論文的另外兩名作者鄭亞男和楊小驄也來自清華大學,其中鄭亞男是今年年初備受矚目的P-tuning(GPT Understands, Too)的共同一作。

論文地址:https://arxiv.org/pdf/2103.10385.pdf