谷歌130億參數(shù)多語(yǔ)言模型mT5重磅來(lái)襲,101種語(yǔ)言輕松遷移
Facebook剛剛開(kāi)源多語(yǔ)種機(jī)器翻譯模型「M2M-100」,這邊谷歌也來(lái)了。谷歌宣布,基于T5的mT5多語(yǔ)言模型正式開(kāi)源,最大模型130億參數(shù),與Facebook的M2M相比,參數(shù)少了,而且支持更多語(yǔ)種。
前幾天,F(xiàn)acebook發(fā)了一個(gè)百種語(yǔ)言互譯的模型M2M-100,這邊谷歌著急了,翻譯可是我的老本行啊。
剛剛,谷歌也放出了一個(gè)名為 mT5的模型,在一系列英語(yǔ)自然處理任務(wù)上制服了各種SOTA。
你發(fā),我也發(fā),你支持100種,我支持101種!(雖然多這一種沒(méi)有多大意義,但氣勢(shì)上不能輸)
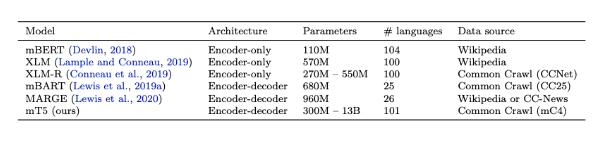
mT5是谷歌 T5模型的多語(yǔ)種變體,訓(xùn)練的數(shù)據(jù)集涵蓋了101種語(yǔ)言,包含3億至130億個(gè)參數(shù),從參數(shù)量來(lái)看,的確是一個(gè)超大模型。
多語(yǔ)言模型是AI的橋梁,但難以避免「有毒」輸出
世界上成體系的語(yǔ)言現(xiàn)在大概有7000種,縱然人工智能在計(jì)算機(jī)視覺(jué)、語(yǔ)音識(shí)別等領(lǐng)域已經(jīng)超越了人類,但只局限在少數(shù)幾種語(yǔ)言。
想把通用的AI能力,遷移到一個(gè)小語(yǔ)種上,幾乎相當(dāng)于從頭再來(lái),有點(diǎn)得不償失。
所以跨語(yǔ)種成為了AI能力遷移的重要橋梁。
多語(yǔ)言人工智能模型設(shè)計(jì)的目標(biāo)就是建立一個(gè)能夠理解世界上大部分語(yǔ)言的模型。
多語(yǔ)言人工智能模型可以在相似的語(yǔ)言之間共享信息,降低對(duì)數(shù)據(jù)和資源的依賴,并且允許少樣本或零樣本學(xué)習(xí)。隨著模型規(guī)模的擴(kuò)大,往往需要更大的數(shù)據(jù)集。
C4是從公共網(wǎng)站獲得的大約750gb 的英文文本的集合,mC4是 C4的一個(gè)變體,C4數(shù)據(jù)集主要為英語(yǔ)任務(wù)設(shè)計(jì),mC4搜集了過(guò)去71個(gè)月的網(wǎng)頁(yè)數(shù)據(jù),涵蓋了107種語(yǔ)言,這比 C4使用的源數(shù)據(jù)要多得多。
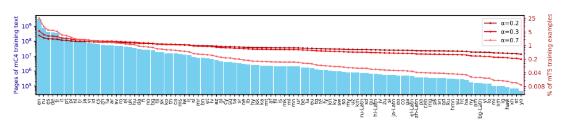
mC4中各種語(yǔ)言的網(wǎng)頁(yè)數(shù)量
有證據(jù)表明,語(yǔ)言模型會(huì)放大數(shù)據(jù)集中存在的偏差。
雖然一些研究人員聲稱,目前的機(jī)器學(xué)習(xí)技術(shù)難以避免「有毒」的輸出,但是谷歌的研究人員一直在試圖減輕 mT5的偏見(jiàn),比如過(guò)濾數(shù)據(jù)中含有偏激語(yǔ)言的頁(yè)面,使用 cld3檢測(cè)頁(yè)面的語(yǔ)言,將置信度低于70% 的頁(yè)面直接刪除。
mT5:使用250000詞匯,多語(yǔ)言數(shù)據(jù)采樣策略是關(guān)鍵
mT5的模型架構(gòu)和訓(xùn)練過(guò)程與T5十分相似,mT5基于T5中的一些技巧,比如使用GeGLU的非線性(Shazeer,2020年),在較大模型中縮放dmodel而不是dff來(lái)對(duì)T5進(jìn)行改進(jìn),并且僅對(duì)未標(biāo)記的數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練而不會(huì)出現(xiàn)信息丟失。
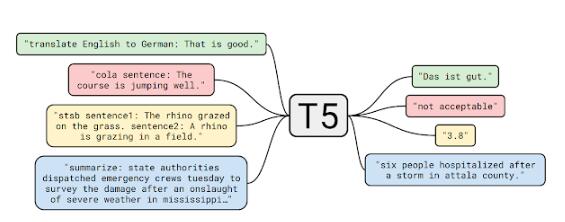
訓(xùn)練多語(yǔ)言模型的最重要的一點(diǎn)是如何從每種語(yǔ)言中采樣數(shù)據(jù)。
但是,這種選擇是零和博弈:如果對(duì)低資源語(yǔ)言的采樣過(guò)于頻繁,則該模型可能會(huì)過(guò)擬合;如果對(duì)高資源語(yǔ)言的訓(xùn)練不夠充分,則模型的通用性會(huì)受限。
因此,研究團(tuán)隊(duì)采用Devlin和Arivazhagan等人使用的方法,并根據(jù)概率p(L)∝ | L |^α,對(duì)資源較少的語(yǔ)言進(jìn)行采樣。其中p(L)是在預(yù)訓(xùn)練期間從給定語(yǔ)言中采樣的概率,| L |是該語(yǔ)言中樣本的數(shù)量,α是個(gè)超參數(shù),谷歌經(jīng)過(guò)實(shí)驗(yàn)發(fā)現(xiàn)α取0.3的效果最好。
為了適應(yīng)更多的語(yǔ)言,mT5將詞匯量增加到250,000個(gè)單詞。與T5一樣,使用SentencePiece和wordPiece來(lái)訓(xùn)練模型。

Sentencepiece示意
那采樣之后有的字符沒(méi)覆蓋到怎么辦?
研究團(tuán)隊(duì)為了適應(yīng)具有大字符集的語(yǔ)言(比如中文),使用了0.99999的字符覆蓋率,但還啟用了SentencePiece的「字節(jié)后退」功能,以確保可以唯一編碼任何字符串。
為了讓結(jié)果更直觀,研究人員與現(xiàn)有的大規(guī)模多語(yǔ)言預(yù)訓(xùn)練語(yǔ)言模型進(jìn)行了簡(jiǎn)要比較,主要是支持?jǐn)?shù)十種語(yǔ)言的模型。
mT5專治各種SOTA,但基準(zhǔn)測(cè)試未必能代表實(shí)力
截至2020年10月,實(shí)驗(yàn)中最大 mT5模型擁有130億個(gè)參數(shù),超過(guò)了所有測(cè)試基準(zhǔn),包括來(lái)自 XTREME 多語(yǔ)言基準(zhǔn)測(cè)試的5個(gè)任務(wù),涵蓋14種語(yǔ)言的 XNLI 衍生任務(wù),分別有10種、7種和11種語(yǔ)言的 XQuAD、 MLQA 和 TyDi QA/閱讀理解基準(zhǔn)測(cè)試,以及有7種語(yǔ)言的 PAWS-X 釋義識(shí)別。
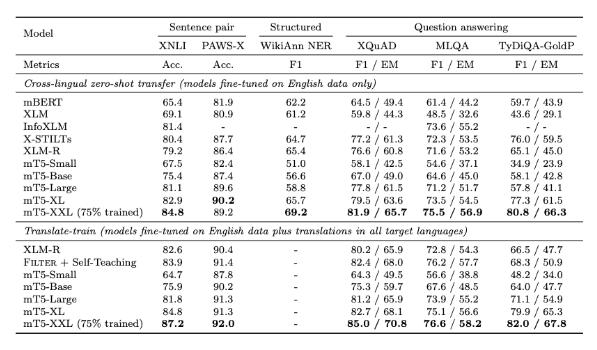
實(shí)驗(yàn)結(jié)果可以看到,在閱讀理解、機(jī)器問(wèn)答等各項(xiàng)基準(zhǔn)測(cè)試中mT5模型都優(yōu)于之前的預(yù)訓(xùn)練語(yǔ)言模型。
至于基準(zhǔn)測(cè)試能否充分反映模型在生產(chǎn)環(huán)境中的表現(xiàn),就另當(dāng)別論了。
對(duì)預(yù)訓(xùn)練語(yǔ)言模型最直白的測(cè)試方法就是開(kāi)放域問(wèn)答,看訓(xùn)練后的模型能否回答沒(méi)見(jiàn)過(guò)的新問(wèn)題,目前來(lái)看,即使強(qiáng)如GPT-3,也經(jīng)常答非所問(wèn)。
但是谷歌的研究人員斷言,mT5是向功能強(qiáng)大的模型邁出的一步,而這些模型不需要復(fù)雜的建模技術(shù)。
總的來(lái)說(shuō),mT5展示出了跨語(yǔ)言表征學(xué)習(xí)中的重要性,并表明了通過(guò)過(guò)濾、并行數(shù)據(jù)或其他一些調(diào)優(yōu)技巧,實(shí)現(xiàn)跨語(yǔ)言能力遷移是可行的。
這個(gè)源自T5的模型,完全適用于多語(yǔ)言環(huán)境。