一個(gè)數(shù)據(jù)爬取和分析系統(tǒng)的演變過(guò)程
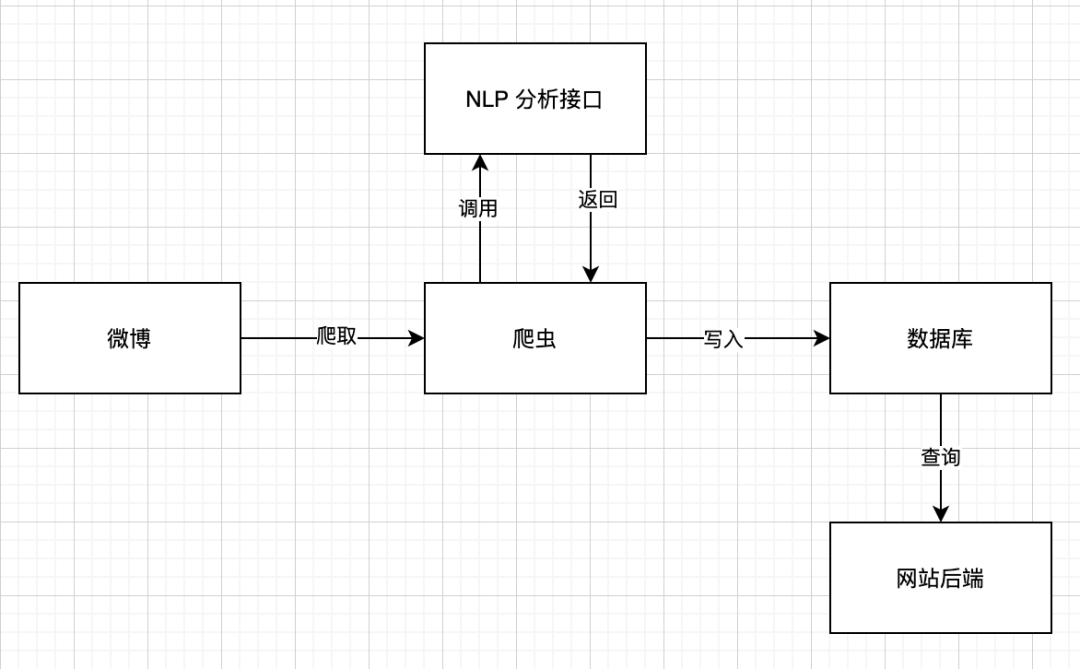
假設(shè)有這樣一個(gè)需求,需要你寫一個(gè)爬蟲,爬取微博中關(guān)于某個(gè)話題的討論,然后分析情感,最后用一個(gè)網(wǎng)頁(yè)來(lái)展示分析結(jié)果。那么你一開(kāi)始的數(shù)據(jù)流程可能是這樣的:
后來(lái),老板發(fā)現(xiàn)只有微博一個(gè)源不夠,于是又給你加了100000個(gè)源。現(xiàn)在你的系統(tǒng)是這樣的:
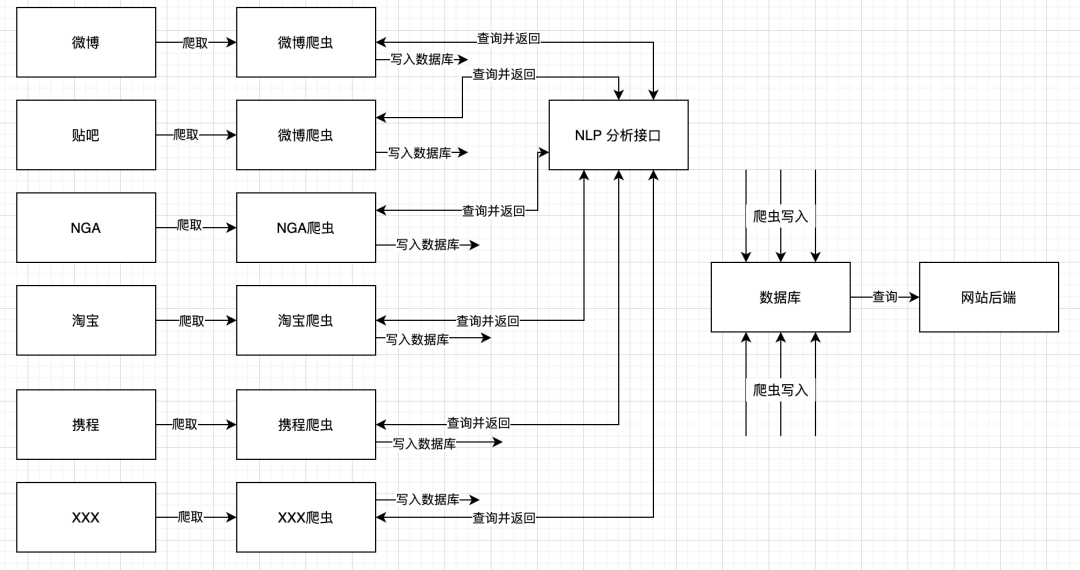
為了防止太多的線做交叉,我做了一些處理。
一開(kāi)始你調(diào)用 NLP 分析接口的時(shí)候,傳入的參數(shù)只有爬取內(nèi)容的正文,但有一天,NLP 研究員希望做一個(gè)情感衰減分析。于是你要修改每一個(gè)爬蟲,讓每一個(gè)爬蟲在調(diào)用 NLP 分析接口的時(shí)候,都帶上時(shí)間參數(shù)。這花了你幾天的時(shí)間。
你一想,這不行啊,豈不是每次增加修改字段,都要改每一個(gè)爬蟲?為了避免動(dòng)到爬蟲,于是你對(duì)系統(tǒng)架構(gòu)做了一些修改:
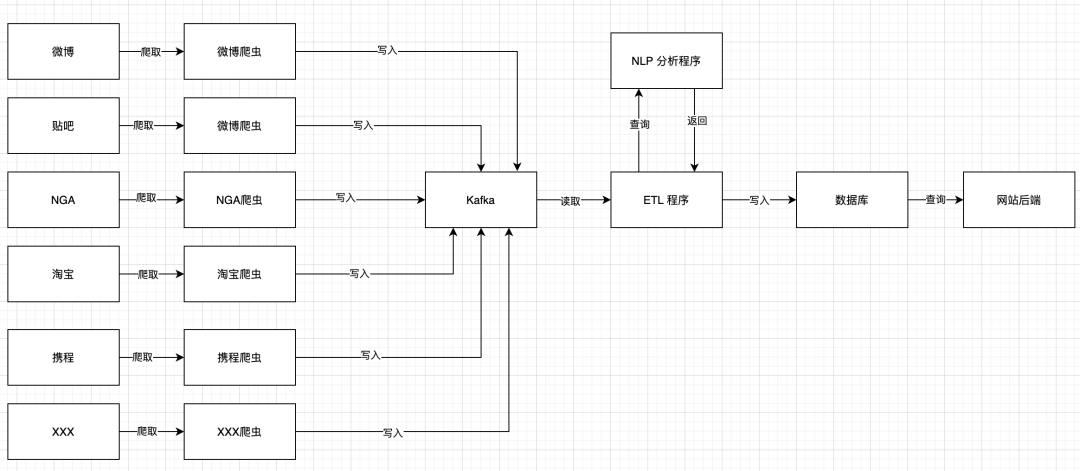
現(xiàn)在,爬蟲這邊總是會(huì)把它能爬到的全部數(shù)據(jù)都寫進(jìn) Kafka 里面。你的 ETL 程序只挑選需要的字段傳給 NLP 接口進(jìn)行分析,分析完成以后,寫入數(shù)據(jù)庫(kù)中。程序的處理線條變得清晰了。
你以為這樣就完了?還早呢。
有一天,你發(fā)現(xiàn)網(wǎng)頁(yè)上的數(shù)據(jù)很久沒(méi)有更新了。說(shuō)明數(shù)據(jù)在某個(gè)地方停了。現(xiàn)在,你首先去 Kafka 檢查爬蟲的數(shù)據(jù),發(fā)現(xiàn)爬蟲數(shù)據(jù)是正常入庫(kù)的。那么,說(shuō)明問(wèn)題出現(xiàn)在下圖這一塊:
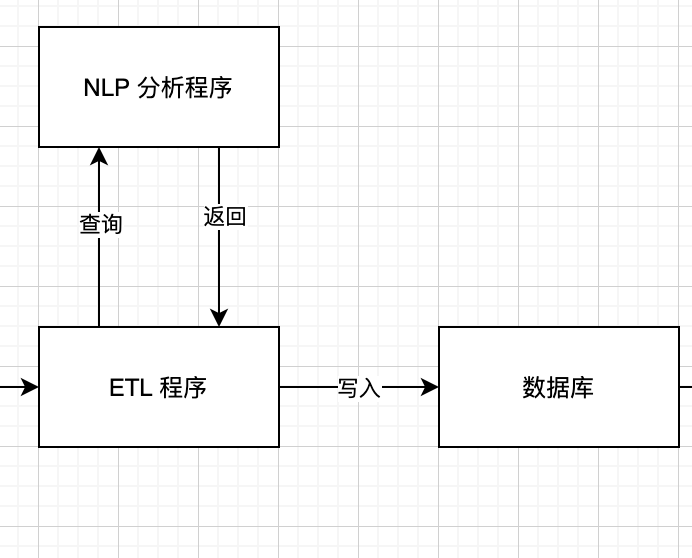
那么,請(qǐng)問(wèn)是 ETL 在處理數(shù)據(jù)的時(shí)候出現(xiàn)問(wèn)題導(dǎo)致數(shù)據(jù)丟失了,還是 NLP 接口出了問(wèn)題,導(dǎo)致你傳給他的數(shù)據(jù)沒(méi)有返回?還是數(shù)據(jù)庫(kù)不堪重負(fù),寫入數(shù)據(jù)庫(kù)的時(shí)候出錯(cuò)了?
你現(xiàn)在根本不知道哪里出了問(wèn)題。于是互相甩鍋。
為了避免這個(gè)問(wèn)題,你再一次修改了系統(tǒng)架構(gòu):
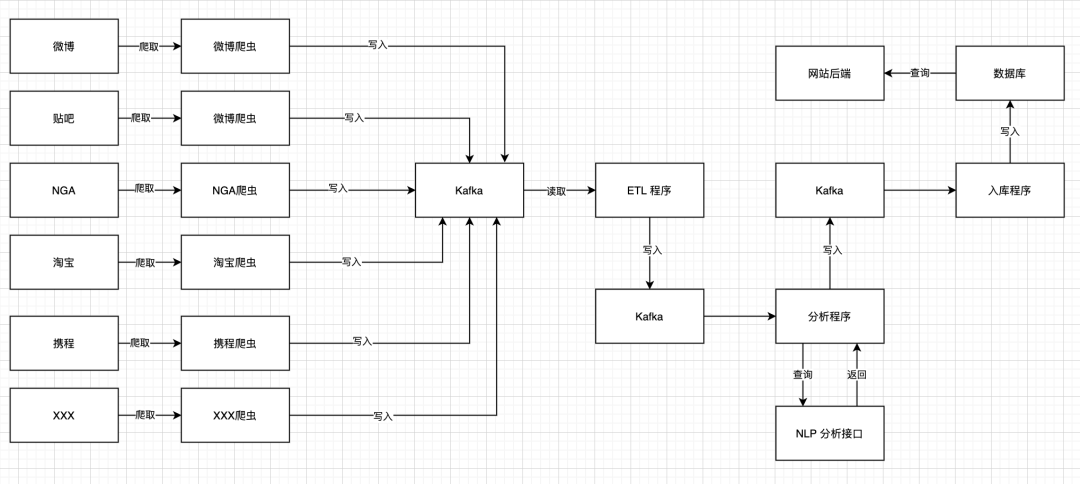
現(xiàn)在通過(guò)檢查 Kafka 的數(shù)據(jù),我可以知道 ETL 程序是否正常輸出內(nèi)容。也可以知道 NLP 分析程序是否正常返回?cái)?shù)據(jù)。我還可以對(duì)比兩邊的數(shù)據(jù)變化率進(jìn)行監(jiān)控。甚至還可以通過(guò)監(jiān)控 Kafka,發(fā)現(xiàn)負(fù)面內(nèi)容太多時(shí),及時(shí)報(bào)警。
當(dāng)然,這還沒(méi)有完,如果還需要發(fā)現(xiàn)新的鏈接,并自動(dòng)抓取,那么又需要增加新的節(jié)點(diǎn)。又或者有一些內(nèi)容需要用瀏覽器渲染,又要增加新的節(jié)點(diǎn)……
大家可以看到,數(shù)據(jù)會(huì)反復(fù)進(jìn)出 Kafka,那么它的效率顯然會(huì)比直接用爬蟲串聯(lián)萬(wàn)物的寫法慢。但我認(rèn)為這樣的效率損失是值得的。因?yàn)橥ㄟ^(guò)把系統(tǒng)拆解成不同的小塊,我們可以對(duì)系統(tǒng)運(yùn)行的每一個(gè)階段進(jìn)行監(jiān)控,從而能夠更好地了解系統(tǒng)的運(yùn)行狀態(tài)。并且,每一個(gè)小塊也能夠更方便地進(jìn)行維護(hù),無(wú)論是修 bug 還是增加新功能,都能減小對(duì)其他部分的影響,并且可以提高修復(fù)的速度。