













數據科學面試中應了解的十種機器學習概念
如您本文轉載自公眾號“讀芯術”(ID:AI_Discovery)。
如您所知,數據科學和機器學習必須提供無窮無盡的信息和知識。 話雖如此,大多數公司都只測試少數核心思想。 這是因為這十個概念是更復雜的思想和概念的基礎。
話雖如此,我們開始吧!
1. 有監督與無監督學習
您可能想知道為什么我什至不愿意將其放入,因為它是如此的基礎。 但是,我認為重要的是,您必須真正了解兩者之間的差異并能夠傳達差異:
監督學習涉及在已知目標變量的標記數據集上學習。
無監督學習用于從輸入數據中得出推論和查找模式,而無需引用標記結果—沒有目標變量。
既然您知道了兩者之間的區別,那么您應該知道機器學習模型是有監督的還是無監督的,并且還應該知道給定的場景是需要監督學習算法還是無監督學習算法。
例如,如果我想預測客戶是否已經購買了谷物,那么他們是否需要購買牛奶,這是否需要有監督或無監督的學習算法?
2. 偏差-偏差權衡
為了了解偏差-方差的權衡,您需要知道什么是偏差和方差。
偏差是由于模型的簡化假設而導致的錯誤。 例如,使用簡單的線性回歸對病毒的指數增長進行建模將導致較高的偏差。
方差是指如果使用不同的訓練數據,則預測值將更改的量。 換句話說,更加重視訓練數據的模型將具有更大的方差。
現在,偏差方差折衷實質上表明在給定的機器學習模型中偏差量和方差之間存在反比關系。 這意味著,當您減少模型的偏差時,方差會增加,反之亦然。 但是,有一個最佳點,其中特定數量的偏差和方差導致總誤差最小(請參見下文)。
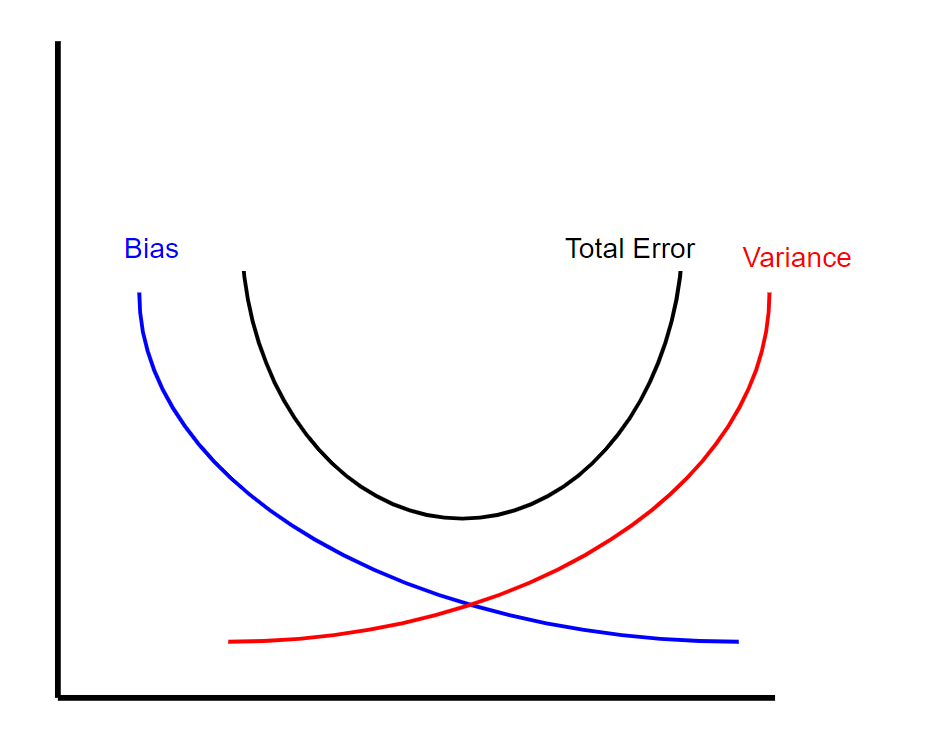
> Visual of bias variance tradeoff (created by author)
3. 正則化
最常見的正則化方法類型稱為L1和L2。 L1和L2正則化都是用于減少訓練數據過度擬合的方法。
L2正則化(也稱為脊回歸)可將殘差平方加λ乘以斜率平方的總和最小化。 這個附加術語稱為"嶺回歸罰分"。 這會增加模型的偏差,使訓練數據的擬合度變差,但也會減少方差。
如果采用嶺回歸罰分并將其替換為斜率的絕對值,則將獲得套索回歸或L1正則化。
L2不那么健壯,但具有穩定的解決方案,并且始終是一個解決方案。 L1更健壯,但解決方案不穩定,可能有多個解決方案。
4. 交叉驗證
交叉驗證本質上是一種用于評估模型在新的獨立數據集上的性能的技術。
交叉驗證的最簡單示例是將數據分為三類:訓練數據,驗證數據和測試數據,其中使用訓練數據構建模型,驗證數據調整超參數以及測試數據 評估您的最終模型。
這引出了下一點-機器學習模型的評估指標。
5. 評估指標
您可以選擇多種度量來評估您的機器學習模型,最終選擇哪種度量取決于問題的類型和模型的目標。
如果您正在評估回歸模型,那么重要的指標包括:
- R平方:一種度量,它告訴您因變量的方差比例在多大程度上由自變量的方差解釋。 用簡單的話來說,雖然系數估計趨勢,但R平方代表最佳擬合線周圍的分散。
- 調整后的R平方:添加到模型中的每個其他自變量始終會增加R²值-因此,具有多個自變量的模型似乎更適合,即使不是。 因此,調整后的R 2補償了每個附加的自變量,并且僅在每個給定變量使模型的改進超出概率范圍時才增加。
- 平均絕對誤差(MAE):絕對誤差是預測值和實際值之間的差。 因此,平均絕對誤差是絕對誤差的平均值。
- 均方誤差(MSE):均方誤差或MSE與MAE相似,不同之處在于,您對預測值和實際值之間的平方差取平均值。
分類模型的指標包括:
- 真陰性:模型正確預測負面類別的結果。
- 誤報(類型1錯誤):模型錯誤地預測正類的結果。
- 假陰性(類型2錯誤):模型錯誤地預測陰性類別的結果。
- 準確性:等于模型正確的預測分數。
- 回想一下:嘗試回答"正確識別了實際陽性的比例是多少?"
- 精確度:嘗試回答"陽性識別的正確比例是多少?"
- F1分數:衡量測試準確性的指標,它是準確性和召回率的諧和平均值。 它的最高分數為1(完美的準確性和查全率),最低分數為0。總體而言,它是模型準確性和健壯性的度量。
- AUC-ROC曲線是對分類問題的一種性能度量,它告訴我們模型能夠區分多個類別。 較高的AUC表示模型更準確。
6. 降維
降維是減少數據集中要素數量的過程。 這一點很重要,主要是在您要減少模型中的方差(過度擬合)的情況下。
最流行的降維技術之一是主成分分析或PCA。 從最簡單的意義上講,PCA涉及將較高維度的數據(例如3個維度)投影到較小的空間(例如2個維度)。 這樣會導致數據維度較低(2維而不是3維),同時將所有原始變量保留在模型中。
PCA通常用于壓縮目的,以減少所需的內存并加快算法的速度,還用于可視化目的,從而使匯總數據更加容易。
7. 數據準備
數據準備是清除原始數據并將其轉換為更可用狀態的過程。 在采訪中,可能會要求您列出整理數據集時要采取的一些步驟。
數據準備中一些最常見的步驟包括:
- 檢查異常值并可能將其刪除
- 估算缺失數據
- 編碼分類數據
- 標準化或標準化您的數據
- 特征工程
- 通過對數據進行欠采樣或過采樣來處理數據不平衡
8. 自舉采樣
Bootstrap采樣方法是一個非常簡單的概念,并且是一些更高級的機器學習算法(例如AdaBoost和XGBoost)的構建塊。
從技術上講,自舉采樣方法是一種重采樣方法,它使用隨機采樣進行替換。
別擔心這聽起來令人困惑,讓我用一個圖表來解釋一下:
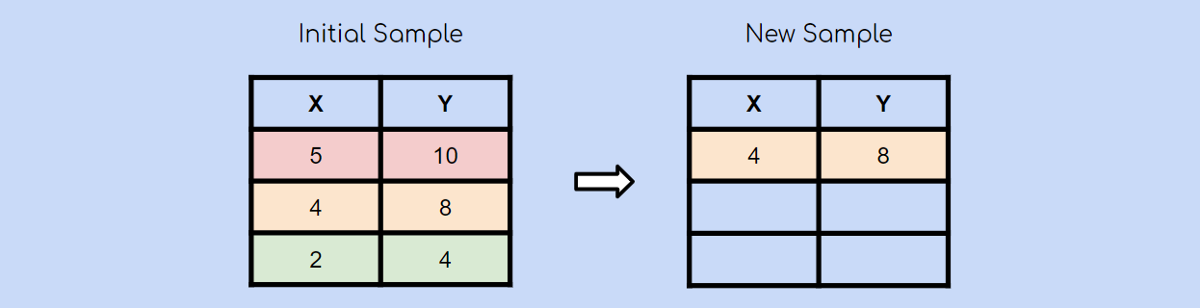
假設您有一個包含3個觀測值的初始樣本。 使用自舉抽樣方法,您還將創建一個包含3個觀測值的新樣本。 每個觀察都有被選擇的平等機會(1/3)。 在這種情況下,第二個觀察值是隨機選擇的,它將是我們新樣本中的第一個觀察值。
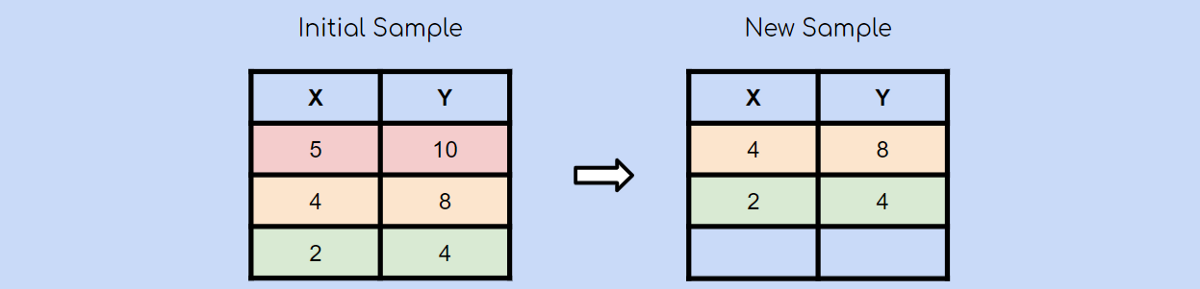
隨機選擇另一個觀察值后,您選擇了綠色觀察值。
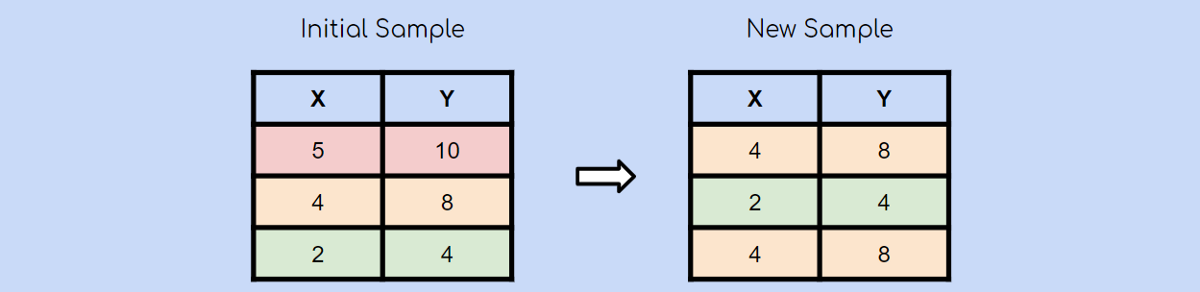
最后,再次隨機選擇黃色觀察值。 請記住,引導抽樣是使用隨機抽樣和替換抽樣。 這意味著很有可能再次選擇已經選擇的觀測值。
這就是自舉采樣的精髓!
9. 神經網絡
盡管并不是每個數據科學工作都需要深度學習,但無疑需求在不斷增長。 因此,對神經網絡是什么以及它們如何工作有一個基本的了解可能是一個好主意。
從根本上說,神經網絡本質上是數學方程式的網絡。 它采用一個或多個輸入變量,并通過方程式網絡得出一個或多個輸出變量。
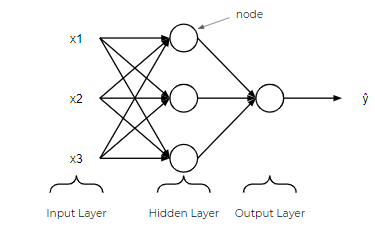
在神經網絡中,有一個輸入層,一個或多個隱藏層和一個輸出層。 輸入層由一個或多個表示為x1,x2,…,xn的特征變量(或輸入變量或自變量)組成。 隱藏層由一個或多個隱藏節點或隱藏單元組成。 節點只是上圖中的圓圈之一。 同樣,輸出變量由一個或多個輸出單元組成。
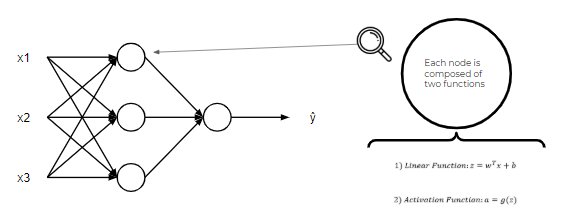
就像我在開始時說的那樣,神經網絡不過是方程網絡。 神經網絡中的每個節點都由兩個函數組成,一個線性函數和一個激活函數。 在這里,事情可能會有些混亂,但是現在,將線性函數視為最合適的直線。 另外,將激活功能想像成一個電燈開關,它會導致數字介于1或0之間。
10. 集成學習,Bagging,Boosting
某些最佳的機器學習算法結合了這些術語,因此,您必須了解什么是集成學習,裝袋和增強。
集成學習是一種結合使用多種學習算法的方法。 這樣做的目的是,與單獨使用單個算法相比,它可以實現更高的預測性能。
套袋,也稱為引導程序聚合,是一個過程,其中使用原始數據集的自舉樣本來訓練同一學習算法的多個模型。 然后,就像上面的隨機森林示例一樣,對所有模型的輸出進行表決。
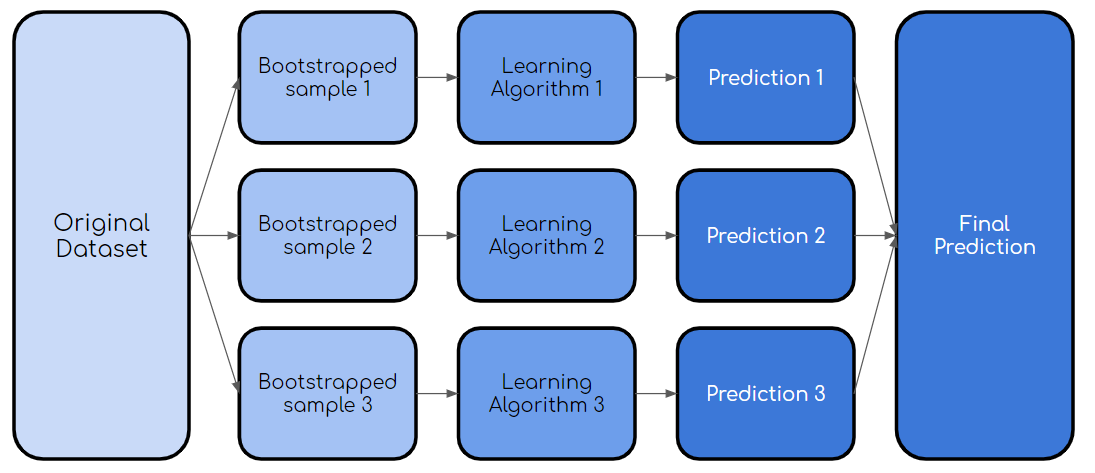
> Bagging Process (created by author)
Boosting是套袋的一種變體,其中每個單獨的模型都按順序構建,并在前一個模型上進行迭代。 具體而言,在以下模型中強調由先前模型錯誤分類的任何數據點。 這樣做是為了提高模型的整體準確性。 這是一個使過程更有意義的圖:
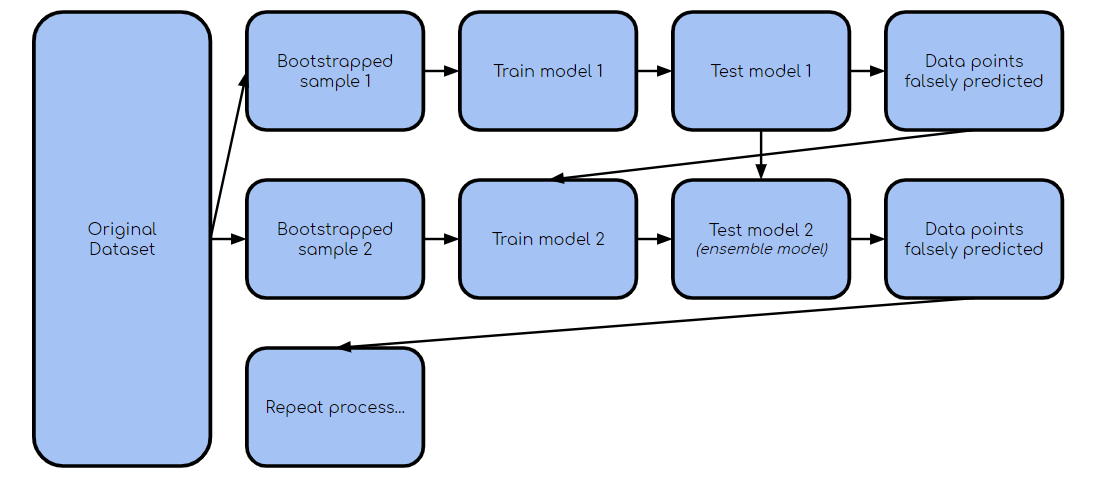
> boosting process (created by author)
一旦建立了第一個模型,除第二個自舉樣本外,還要獲取錯誤分類/預測的點,以訓練第二個模型。 然后,針對測試數據集使用集成模型(模型1和2),然后繼續該過程。




















