













CPU有緩存一致性協(xié)議MESI,為何還需要Volatile?

前言
- 并發(fā)編程從操作系統(tǒng)底層工作的整體認識開始
- 深入理解Java內(nèi)存模型(JMM)及volatile關(guān)鍵字
前面我們從操作系統(tǒng)底層了解了現(xiàn)代計算機結(jié)構(gòu)模型中的CPU指令結(jié)構(gòu)、CPU緩存結(jié)構(gòu)、CPU運行調(diào)度以及操作系統(tǒng)內(nèi)存管理,并且學(xué)習(xí)了Java內(nèi)存模型(JMM)和 volatile 關(guān)鍵字的一些特性。本篇來深入理解CPU緩存一致性協(xié)議(MESI),最后來討論既然CPU有緩存一致性協(xié)議(MESI),為什么JMM還需要volatile關(guān)鍵字?
CPU高速緩存(Cache Memory)
CPU為何要有高速緩存
CPU在摩爾定律的指導(dǎo)下以每18個月翻一番的速度在發(fā)展,然而內(nèi)存和硬盤的發(fā)展速度遠遠不及CPU。這就造成了高性能能的內(nèi)存和硬盤價格及其昂貴。然而CPU的高度運算需要高速的數(shù)據(jù)。為了解決這個問題,CPU廠商在CPU中內(nèi)置了少量的高速緩存以解決I\O速度和CPU運算速度之間的不匹配問題。
在CPU訪問存儲設(shè)備時,無論是存取數(shù)據(jù)抑或存取指令,都趨于聚集在一片連續(xù)的區(qū)域中,這就被稱為局部性原理。
時間局部性(Temporal Locality):如果一個信息項正在被訪問,那么在近期它很可能還會被再次訪問。
比如循環(huán)、遞歸、方法的反復(fù)調(diào)用等。
空間局部性(Spatial Locality):如果一個存儲器的位置被引用,那么將來他附近的位置也會被引用。
比如順序執(zhí)行的代碼、連續(xù)創(chuàng)建的兩個對象、數(shù)組等。
帶有高速緩存的CPU執(zhí)行計算的流程
- 程序以及數(shù)據(jù)被加載到主內(nèi)存
- 指令和數(shù)據(jù)被加載到CPU的高速緩存
- CPU執(zhí)行指令,把結(jié)果寫到高速緩存
- 高速緩存中的數(shù)據(jù)寫回主內(nèi)存
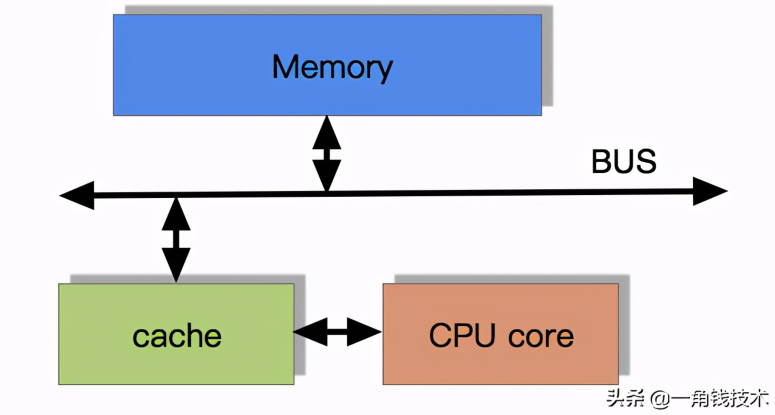
目前流行的多級緩存結(jié)構(gòu)
由于CPU的運算速度超越了1級緩存的數(shù)據(jù)I/O能力,CPU廠商又引入了多級的緩存結(jié)構(gòu)。多級緩存結(jié)構(gòu)示意圖如下:
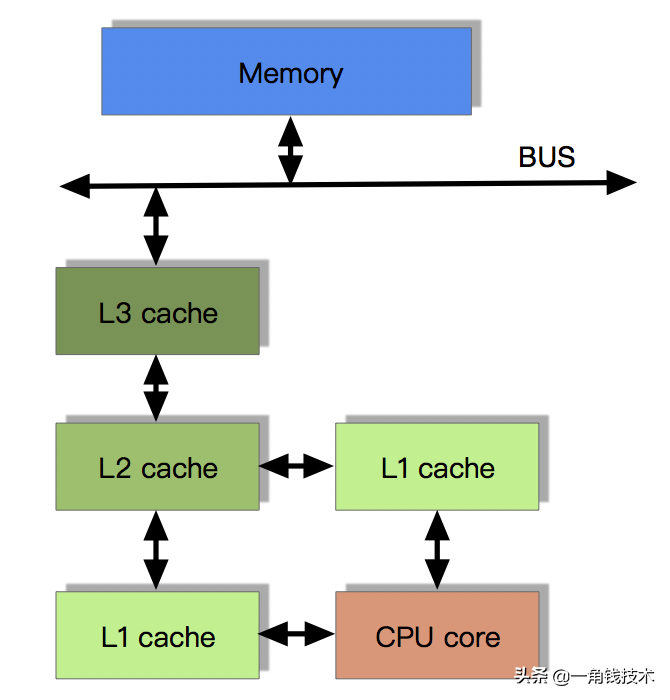
多核CPU多級緩存一致性協(xié)議MESI
多核CPU的情況下有多個一級緩存,如果保證緩存內(nèi)部數(shù)據(jù)的一致,不讓系統(tǒng)數(shù)據(jù)混亂。這里就引出了一個一致性的協(xié)議MESI。
MESI 協(xié)議緩存狀態(tài)
MESI 是指4個狀態(tài)的首字母。每個 Cache line 有4個狀態(tài),可用2個bit表示,它們分別是:
緩存行(Cache line):緩存存儲數(shù)據(jù)的單元
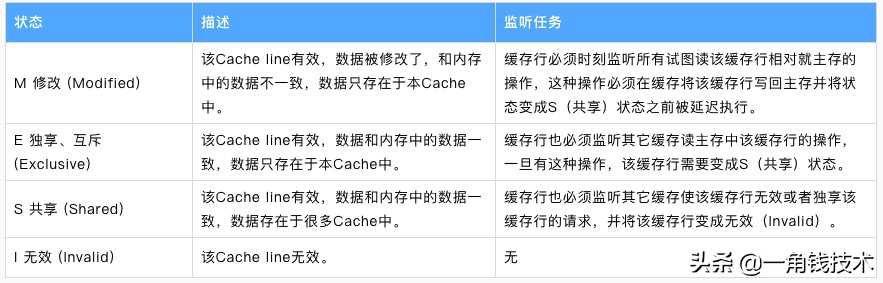
注意:對于M 和 E 狀態(tài)而言是精確的,它們在和該緩存行的真正狀態(tài)是一致的,而 S 狀態(tài)可能是非一致的。
如果一個緩存將處于S狀態(tài)的緩存行作廢了,而另一個緩存實際上可能已經(jīng)獨享了該緩存行,但是該緩存卻不會將緩存行升遷為E狀態(tài),這是因為其他緩存不會廣播它們作廢掉該緩存行的通知,同樣由于緩存并沒有保存該緩存行的copy數(shù)量,因此(即使有這種通知)也沒有辦法確定自己是否已經(jīng)獨享了該緩存行。
從上面的意義來看 E狀態(tài) 是一種投機性的優(yōu)化:如果一個CPU想修改一個處于 S狀態(tài) 的緩存行,總線事物需要將所有該緩存行的 copy 變成 invalid 狀態(tài),而修改 E狀態(tài) 的緩存不需要使用總線事物。
MESI 狀態(tài)轉(zhuǎn)換
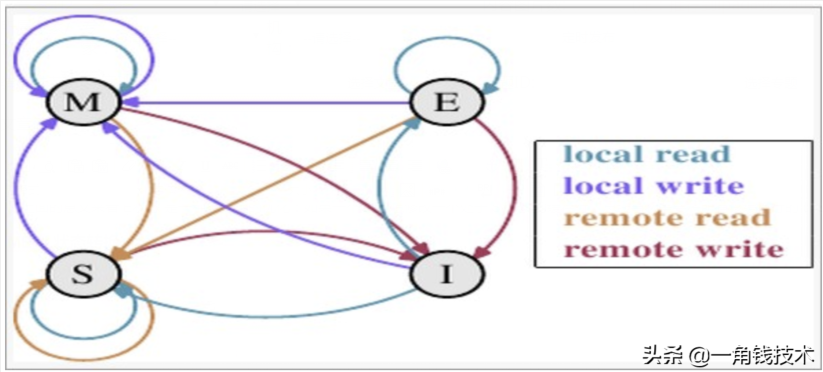
理解該圖的前置說明:
1.觸發(fā)事件
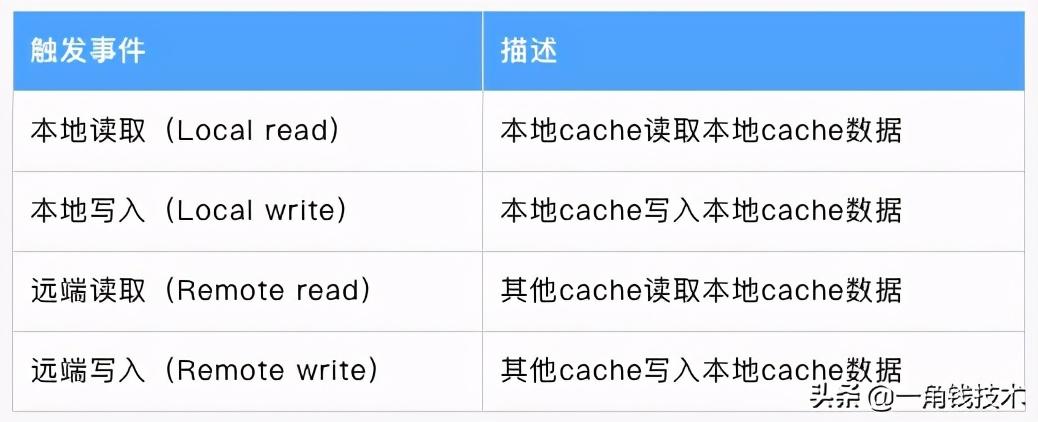
1.cache分類
- 前提:所有的cache共同緩存了主內(nèi)存中的某一條數(shù)據(jù)。
- 本地cache:指當前cpu的cache。
- 觸發(fā)cache:觸發(fā)讀寫事件的cache。
- 其他cache:指既除了以上兩種之外的cache。
- 注意:本地的事件觸發(fā) 本地cache和觸發(fā)cache為相同。
上圖的切換解釋:
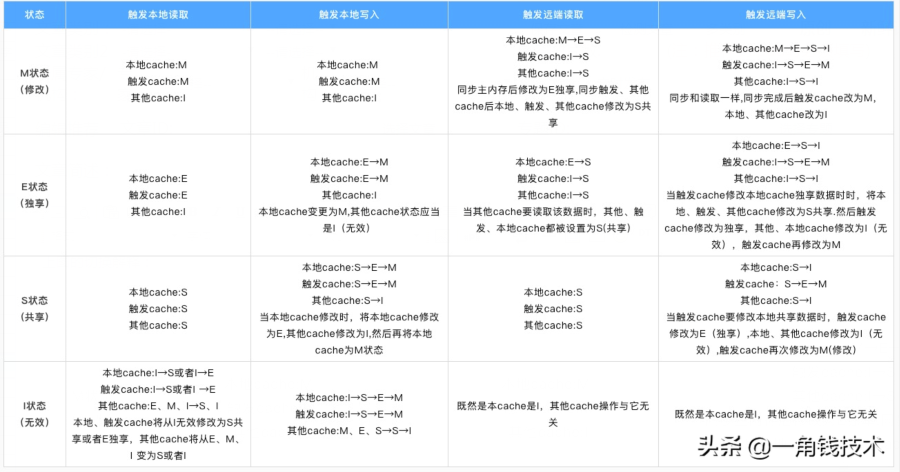
下圖示意了,當一個cache line的調(diào)整的狀態(tài)的時候,另外一個cache line 需要調(diào)整的狀態(tài)。
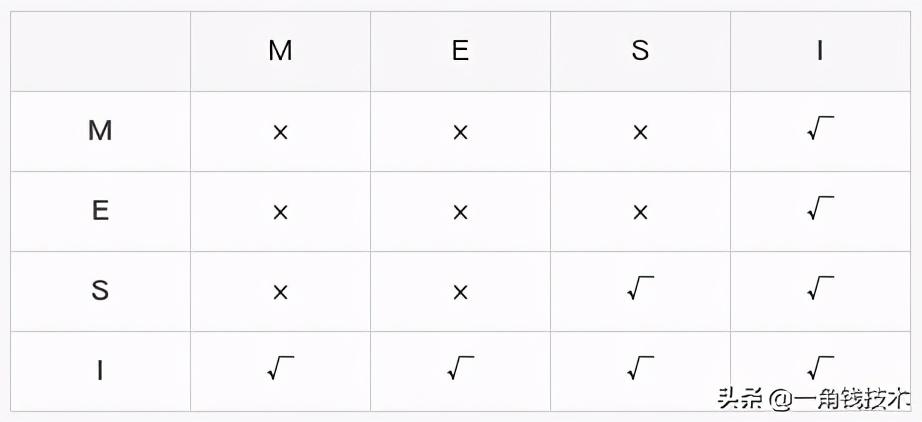
舉例子來說:假設(shè) cache 1 中有一個變量 x = 0 的 cache line 處于 S狀態(tài)(共享)。 那么其他擁有 x 變量的 cache 2 、cache 3 等 x 的cache line 調(diào)整為 S狀態(tài)(共享)或者調(diào)整為 I狀態(tài)(無效)。
多核緩存協(xié)同操作
假設(shè)有三個CPU A、B、C,對應(yīng)三個緩存分別是cache a、b、 c。在主內(nèi)存中定義了x的引用值為0。
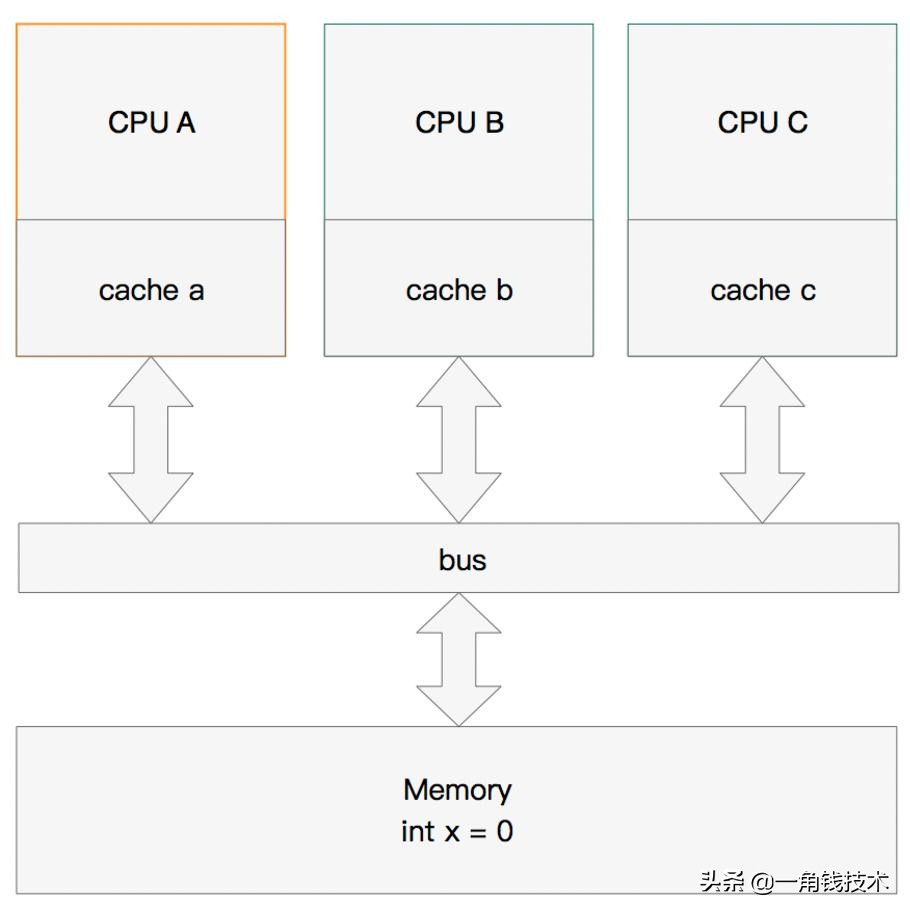
單核讀取
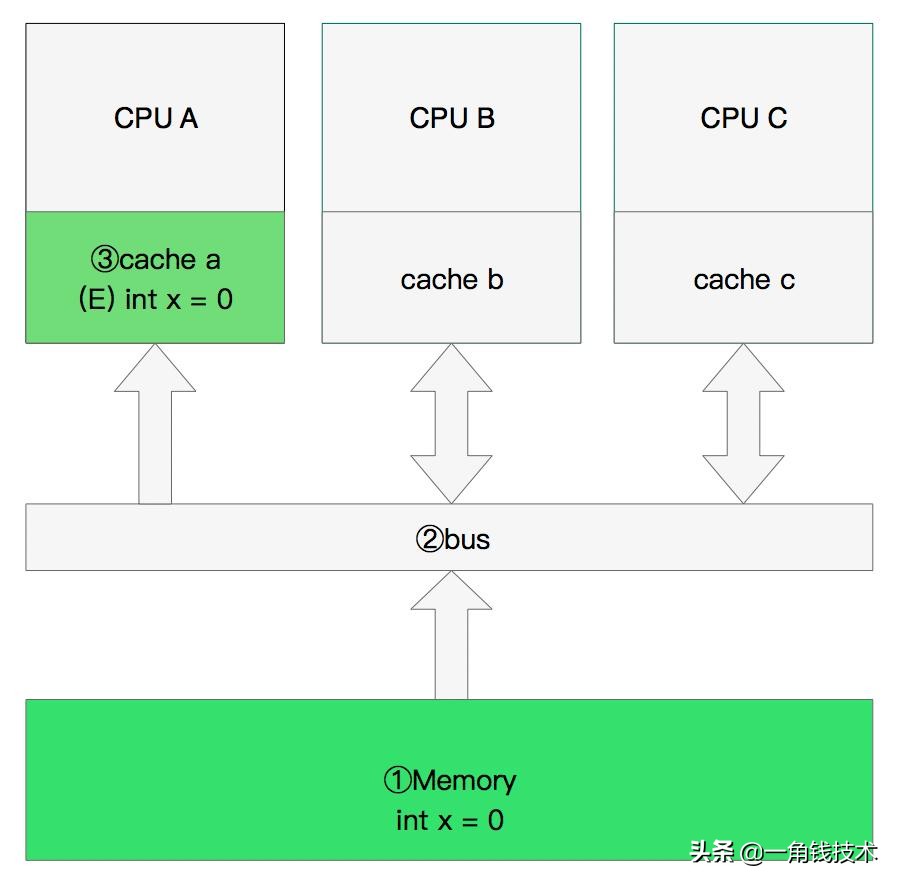
那么執(zhí)行流程是: CPU A 發(fā)出了一條指令,從主內(nèi)存中讀取x。
從主內(nèi)存通過bus讀取到緩存中(遠端讀取Remote read),這是該 Cache line 修改為 E狀態(tài)(獨享).
雙核讀取
那么執(zhí)行流程是:
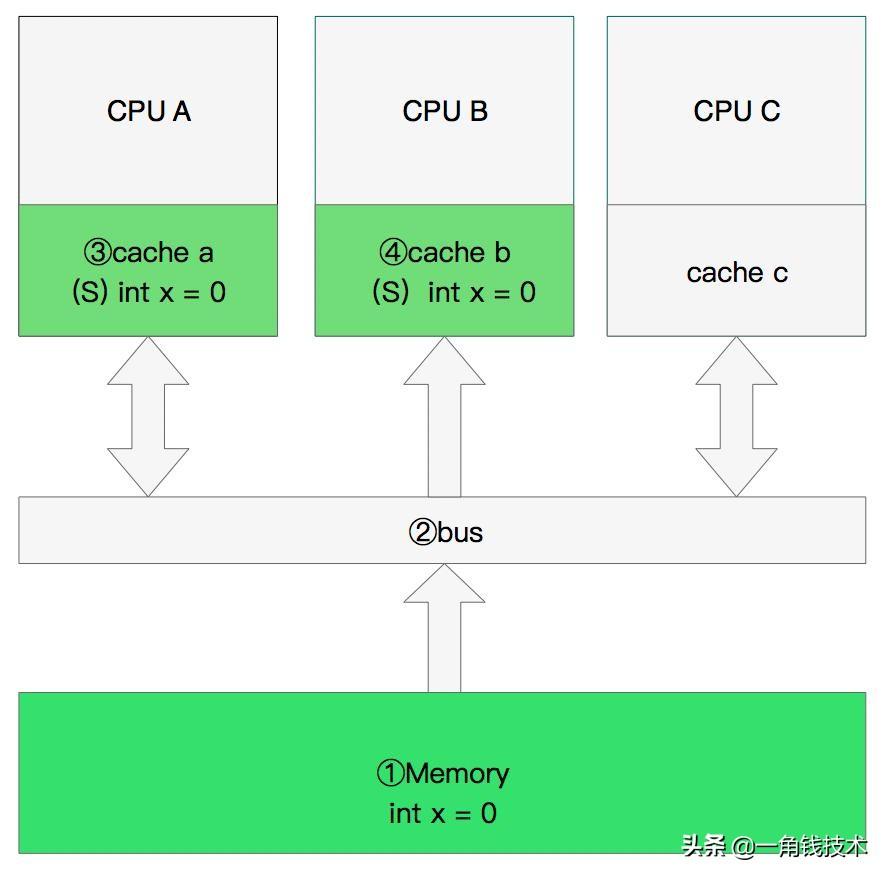
- CPU A 發(fā)出了一條指令,從主內(nèi)存中讀取x。
- CPU A 從主內(nèi)存通過bus讀取到 cache a 中并將該 cache line 設(shè)置為 E狀態(tài)。
- CPU B 發(fā)出了一條指令,從主內(nèi)存中讀取x。
- CPU B 試圖從主內(nèi)存中讀取x時,CPU A 檢測到了地址沖突。這時CPU A對相關(guān)數(shù)據(jù)做出響應(yīng)。此時x 存儲于cache a和cache b中,x在chche a和cache b中都被設(shè)置為S狀態(tài)(共享)。
修改數(shù)據(jù)
那么執(zhí)行流程是:
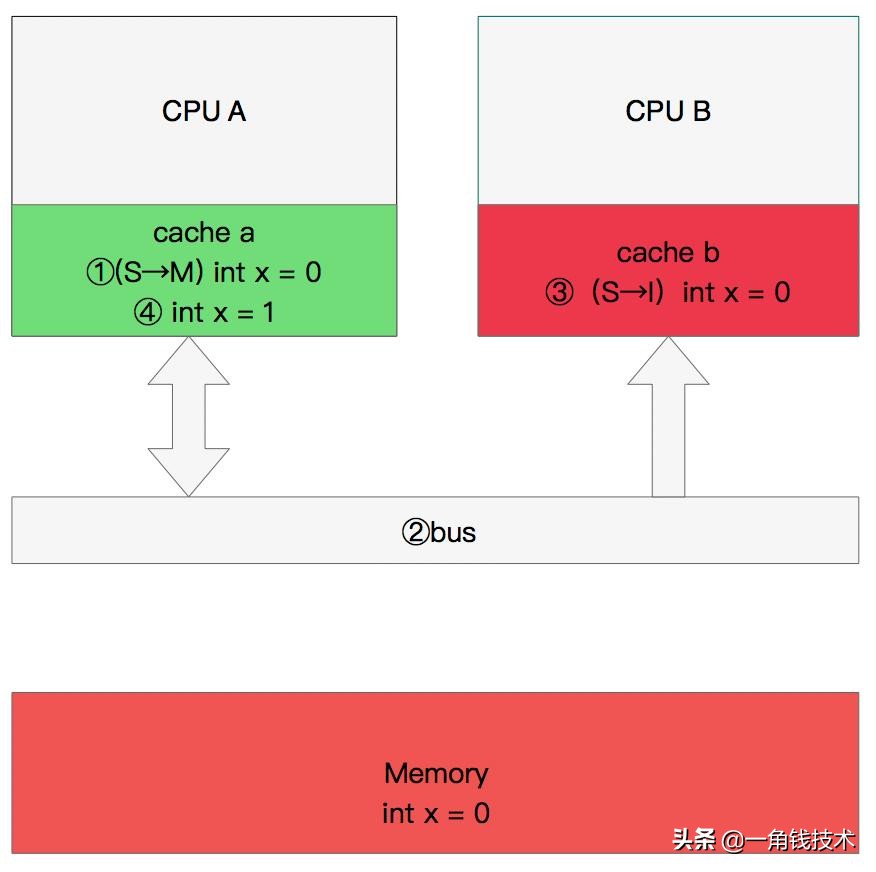
- CPU A 計算完成后發(fā)指令需要修改x.
- CPU A 將x設(shè)置為 M狀態(tài)(修改)并通知緩存了x的CPU B, CPU B將本地cache b中的x設(shè)置為 I狀態(tài)(無效)
- CPU A 對x進行賦值。
同步數(shù)據(jù)
那么執(zhí)行流程是:
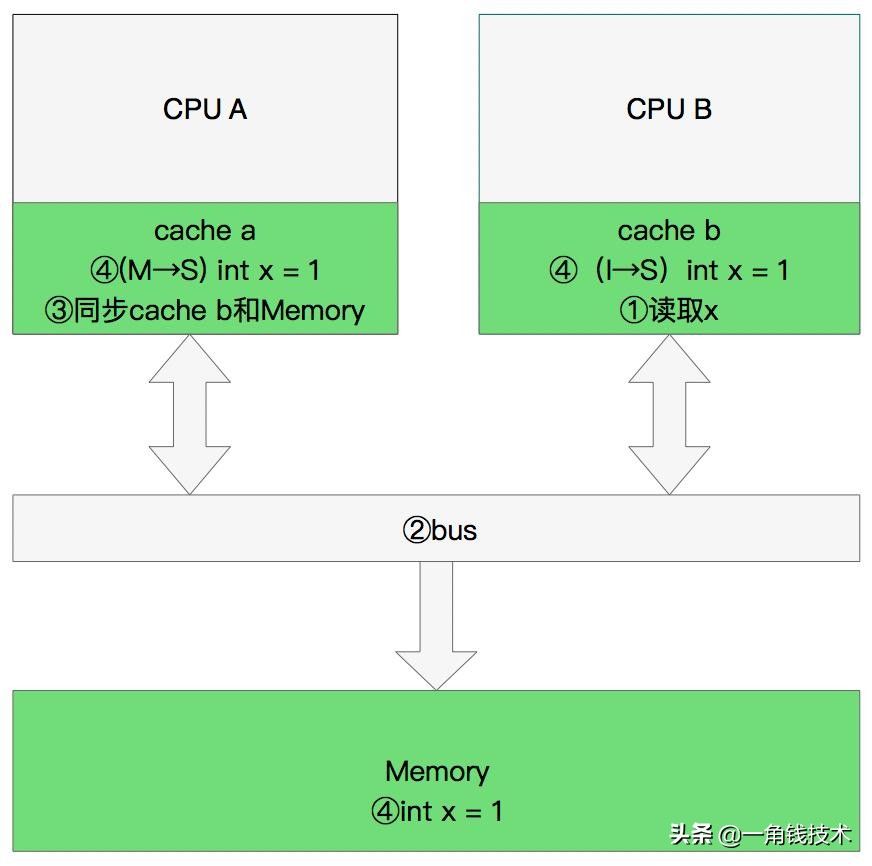
- CPU B 發(fā)出了要讀取x的指令。
- CPU B 通知 CPU A,CPU A將修改后的數(shù)據(jù)同步到主內(nèi)存時 cache a 修改為 E(獨享)
- CPU A同步CPU B的x,將cache a和同步后cache b中的x設(shè)置為 S狀態(tài)(共享)。
緩存行偽共享
什么是偽共享?
CPU緩存系統(tǒng)中是以緩存行(cache line)為單位存儲的。目前主流的CPU Cache 的 Cache Line 大小都是64Bytes。在多線程情況下,如果需要修改“共享同一個緩存行的變量”,就會無意中影響彼此的性能,這就是偽共享(False Sharing)。
舉個例子: 現(xiàn)在有2個long 型變量 a 、b,如果有t1在訪問a,t2在訪問b,而a與b剛好在同一個cache line中,此時t1先修改a,將導(dǎo)致b被刷新!
怎么解決偽共享?
Java8中新增了一個注解: @sun.misc.Contended 。加上這個注解的類會自動補齊緩存行,需要注意的是此注解默認是無效的,需要在jvm啟動時設(shè)置 -XX:-RestrictContended 才會生效。
- @sun.misc.Contended
- public final static class VolatileLong {
- public volatile long value = 0L;
- //public long p1, p2, p3, p4, p5, p6;
- }
MESI優(yōu)化和他們引入的問題
緩存的一致性消息傳遞是要時間的,這就使其切換時會產(chǎn)生延遲。當一個緩存被切換狀態(tài)時其他緩存收到消息完成各自的切換并且發(fā)出回應(yīng)消息這么一長串的時間中CPU都會等待所有緩存響應(yīng)完成。可能出現(xiàn)的阻塞都會導(dǎo)致各種各樣的性能問題和穩(wěn)定性問題。
CPU切換狀態(tài)阻塞解決-存儲緩存(Store Bufferes)
比如你需要修改本地緩存中的一條信息,那么你必須將 **I(無效)狀態(tài) **通知到其他擁有該緩存數(shù)據(jù)的CPU緩存中,并且等待確認。等待確認的過程會阻塞處理器,這會降低處理器的性能。因為這個等待遠遠比一個指令的執(zhí)行時間長得多。
Store Bufferes
為了避免這種CPU運算能力的浪費,**Store Bufferes** 被引入使用。處理器把它想要寫入到主存的值寫到緩存,然后繼續(xù)去處理其他事情。當所有失效確認(Invalidate Acknowledge)都接收到時,數(shù)據(jù)才會最終被提交。但這么做有兩個風(fēng)險。
Store Bufferes的風(fēng)險
- 第一:就是處理器會嘗試從存儲緩存(Store buffer)中讀取值,但它還沒有進行提交。這個的解決方案稱為 Store Forwarding,它使得加載的時候,如果存儲緩存中存在,則進行返回。
- 第二:保存什么時候會完成,這個并沒有任何保證。
- value = 3;
- void exeToCPUA(){
- value = 10;
- isFinsh = true;
- }
- void exeToCPUB(){
- if(isFinsh){
- //value一定等于10?!
- assert value == 10;
- }
- }
試想一下開始執(zhí)行時,CPU A 保存著 isFinsh 在 E(獨享)狀態(tài),而 value 并沒有保存在它的緩存中。(例如,Invalid)。在這種情況下,value 會比 isFinsh 更遲地拋棄存儲緩存。完全有可能 CPU B 讀取 isFinsh 的值為true,而value的值不等于10。即isFinsh的賦值在value賦值之前。
這種在可識別的行為中發(fā)生的變化稱為重排序(reordings)。注意,這不意味著你的指令的位置被惡意(或者好意)地更改。 它只是意味著其他的CPU會讀到跟程序中寫入的順序不一樣的結(jié)果。
硬件內(nèi)存模型
執(zhí)行失效也不是一個簡單的操作,它需要處理器去處理。另外,存儲緩存(Store Buffers)并不是無窮大的,所以處理器有時需要等待失效確認的返回。這兩個操作都會使得性能大幅降低。為了應(yīng)付這種情況,引入了失效隊列(invalid queue)。它們的約定如下:
- 對于所有的收到的Invalidate請求,Invalidate Acknowlege消息必須立刻發(fā)送
- Invalidate并不真正執(zhí)行,而是被放在一個特殊的隊列中,在方便的時候才會去執(zhí)行。
- 處理器不會發(fā)送任何消息給所處理的緩存條目,直到它處理Invalidate。
即便是這樣處理器已然不知道什么時候優(yōu)化是允許的,而什么時候并不允許。
干脆處理器將這個任務(wù)丟給了寫代碼的人。這就是內(nèi)存屏障(Memory Barriers)。
- 寫屏障 Store Memory Barrier(a.k.a. ST, SMB, smp_wmb)是一條告訴處理器在執(zhí)行這之后的指令之前,應(yīng)用所有已經(jīng)在存儲緩存(store buffer)中的保存的指令。
- 讀屏障Load Memory Barrier (a.k.a. LD, RMB, smp_rmb)是一條告訴處理器在執(zhí)行任何的加載前,先應(yīng)用所有已經(jīng)在失效隊列中的失效操作的指令。
- void executedOnCpu0() {
- value = 10;
- //在更新數(shù)據(jù)之前必須將所有存儲緩存(store buffer)中的指令執(zhí)行完畢。
- storeMemoryBarrier();
- finished = true;
- }
- void executedOnCpu1() {
- while(!finished);
- //在讀取之前將所有失效隊列中關(guān)于該數(shù)據(jù)的指令執(zhí)行完畢。
- loadMemoryBarrier();
- assert value == 10;
- }
總結(jié)
既然CPU有緩存一致性協(xié)議(MESI),為什么JMM還需要volatile關(guān)鍵字?
volatile是java語言層面給出的保證,MSEI協(xié)議是多核cpu保證cache一致性的一種方法,中間隔得還很遠,我們可以先來做幾個假設(shè):
1.回到遠古時候,那個時候cpu只有單核,或者是多核但是保證sequence consistency,當然也無所謂有沒有MESI協(xié)議了。那這個時候,我們需要java語言層面的volatile的支持嗎?
當然是需要的,因為在語言層面編譯器和虛擬機為了做性能優(yōu)化,可能會存在指令重排的可能,而volatile給我們提供了一種能力,我們可以告訴編譯器,什么可以重排,什么不可以。
2.那好,假設(shè)更進一步,假設(shè)java語言層面不會對指令做任何的優(yōu)化重排,那在多核cpu的場景下,我們還需要volatile關(guān)鍵字嗎?
答案仍然是需要的。因為 MESI只是保證了多核cpu的獨占cache之間的一致性,但是cpu的并不是直接把數(shù)據(jù)寫入L1 cache的,中間還可能有store buffer。有些arm和power架構(gòu)的cpu還可能有l(wèi)oad buffer或者invalid queue等等。因此,有MESI協(xié)議遠遠不夠。
3.再接著,讓我們再做一個更大膽的假設(shè)。假設(shè)cpu中這類store buffer/invalid queue等等都不存在了,cpu是數(shù)據(jù)是直接寫入cache的,讀取也是直接從cache讀的,那還需要volatile關(guān)鍵字嗎?
你猜得沒錯,還需要的。原因就在這個“一致性”上。consistency和coherence都可以被翻譯為一致性,但是MSEI協(xié)議這里保證的僅僅coherence而不是consistency。那consistency和cohence有什么區(qū)別呢?
下面取自wiki的一段話: Coherence deals with maintaining a global order in which writes to a single location or single variable are seen by all processors. Consistency deals with the ordering of operations to multiple locations with respect to all processors.
因此,MESI協(xié)議最多只是保證了對于一個變量,在多個核上的讀寫順序,對于多個變量而言是沒有任何保證的。很遺憾,還是需要volatile~~
4.好的,到了現(xiàn)在這步,我們再來做最后一個假設(shè),假設(shè)cpu寫cache都是按照指令順序fifo寫的,那現(xiàn)在可以拋棄volatile了吧?你覺得呢?
那肯定不行啊!因為對于arm和power這個weak consistency的架構(gòu)的cpu來說,它們只會保證指令之間有比如控制依賴,數(shù)據(jù)依賴,地址依賴等等依賴關(guān)系的指令間提交的先后順序,而對于完全沒有依賴關(guān)系的指令,比如x=1;y=2,它們是不會保證執(zhí)行提交的順序的,除非你使用了volatile,java把volatile編譯成arm和power能夠識別的barrier指令,這個時候才是按順序的。
最后總結(jié),答案就是:還需要~~
參考資料
- [1] http://igoro.com/archive/gallery-of-processor-cache-effects/
- [2] https://en.wikipedia.org/wiki/Sequential_consistency
- [3] https://en.wikipedia.org/wiki/Consistency_model
- [4] Maranget, Luc, Susmit Sarkar, and Peter Sewell. "A tutorial introduction to the ARM and POWER relaxed memory models." Draft available from http://www. cl. cam. ac. uk/~ pes20/ppc-supplemental/test7. pdf (2012).
- [5] https://www.zhihu.com/question/296949412?sort=created
PS:以上代碼提交在 Github :
https://github.com/Niuh-Study/niuh-juc-final.git





















